one-hot:
对每个特征进行普通的数字编码。对于每个特征有多少状态,就用多少状态码来表示,one-hot编码保证每个样本的单个特征只有一位处于状态1,其他都是状态0。
对于2、3、4种状态,可以得到以下的表示: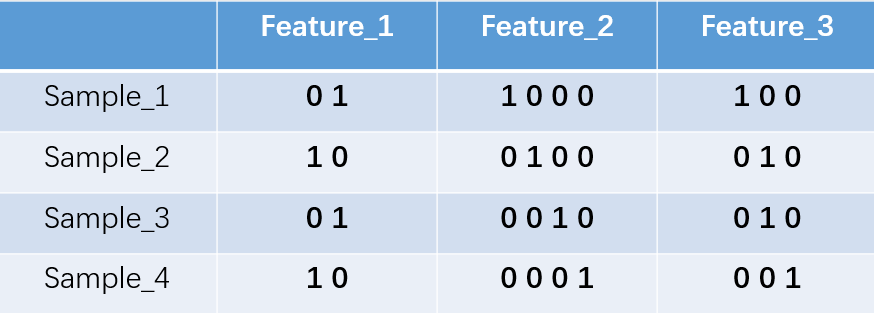
所以可以得到sample_1的特征向量为:【0.1.1.0.0.0.1.0.0】 sample_4:【1.0.0.0.0.1.0.0.1】
one-hot在文本特征提取上属于词袋模型:
假设语料库有三句话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
获取语料库中的所有词,得到特征:
feature1:我 feature2:爱 feature3:爸爸 feature4:妈妈 feature5:中国
此时每个特征有2个状态:有/无
| 我 | 爱 | 爸爸 | 妈妈 | 中国 | |
| 我爱中国 | 01 | 01 | 10 | 10 | 01 |
| 爸爸妈妈爱我 | 01 | 01 | 01 | 01 | 10 |
于是得到特征向量为:我爱中国:0.1.0.1.1.0.1.0.0.1 爸爸妈妈爱我:0.1.0.1.0.1.0.1.1.0
但我们发现所有特征都有两个状态,可以对特征状态位进行简化:我爱中国:1.1.0.0.1 爸爸妈妈爱我:1.1.1.1.0
优缺点分析:
有点:解决了离散值特征的问题;同时在一定程度上起到扩充特征的作用。
缺点:不考虑词之间顺序的词袋模型。假设条件时词之间相互独立。得到的特征过于离散稀疏。
TF-IDF:
算法思想是:统计每个词出现的词频(tf),再为其附上一定的权值(idf)
tf-idf = tf*idf (tf = 某个词在文章中出现的次数/文章的总词数,idf(逆文档频率) = log(语料库的文档总数/包含该词的文档数+1)
优缺点:
有点:简单快速,结果比较符合实际。
缺点:单纯考虑词频,而忽略了词之间的位置信息和相互关系。