版权声明:未经允许,禁止转载 https://blog.csdn.net/weixin_43216017/article/details/87609780
决策树常用的有ID3,C4.5和CART算法,在得到决策树之后还要对树进行剪枝。
ID3算法:https://blog.csdn.net/weixin_43216017/article/details/87474045
CART算法:https://blog.csdn.net/weixin_43216017/article/details/87617727
决策树的剪枝:https://blog.csdn.net/weixin_43216017/article/details/87534496
在上一篇介绍ID3算法文章中,我们指出ID3算法采用信息增益作为标准,缺点在于会偏向分类更多的自变量,并且不能处理连续值。
在本文中,我们将介绍C4.5算法,采用信息增益比代替信息增益,从而减小某一自变量分类个数的影响。
我们假设使用的数据集为
D,待计算的自变量为
A,
g(D,A)则信息增益比为:
gr(D,A)=HA(D)g(D,A)
其中,
HA(D)=−i=1∑n∣D∣∣Di∣log2∣D∣∣Di∣
计算实例:
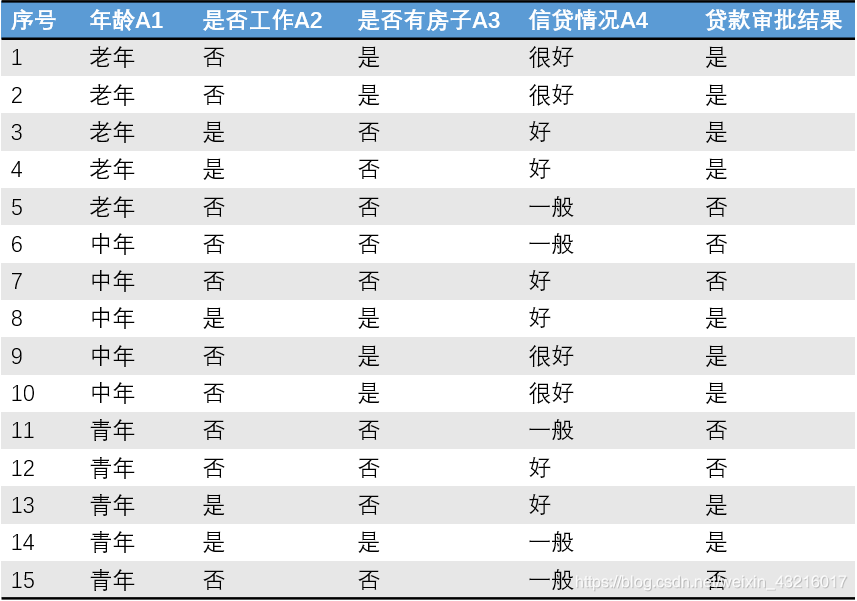
经计算,(信息增益的详细计算过程在上一篇ID3中)
Gain(A1)=0.083
Gain(A2)=0.324
Gain(A3)=0.420
Gain(A4)=0.363
下面计算自变量A1的信息增益比,
H1(D)=−31log231−−31log231−−31log231=1.5850
gr(D,A1)=1.58500.083=0.0524
同理可得
gr(D,A2)=0.91830.324=0.3528
gr(D,A3)=0.97100.420=0.4325
gr(D,A3)=1.56560.363=0.2319
一般而言,我们还是要选择一个信息增益比最大的变量。但是,采用信息增益比也有缺点,即它会偏向于分类较少的变量。
我们总结一下:
ID3算法使用的是信息增益,它偏向于分类较多的变量;
C4.5算法使用的是信息增益比,它偏向于分类较少的变量。
为了克服这些问题,我们采取如下方式:首先计算信息增益和信息增益比,然后选取信息增益在平均值以上的那些变量,最后在这些变量中选择信息增益比最大的变量。
例如:在上面的实例中,我们发现变量A2,A3,A4的信息增益在平均值以上。然后,我们就在A2,A3,A4三个变量中选择信息增益比最大的变量。