背景:若一个家族过于庞大,要判断两个人是否是亲戚,不太容易。现规定:x和y是亲戚,y和z是亲戚,那么x和z也是亲戚。如果x和y是亲戚,那么x的亲戚都是y的亲戚,y的亲戚也都是x的亲戚。
简介:并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。
主要操作:
1、初始化。把每个点所在集合初始化为其自身。
2、查找。
(1)查找时,采用递归的方法找其祖宗,祖宗集合号等于自己时停止。
(2)在回归时,把当前结点到祖宗路径上的所有结点统一为祖宗的集合号。
3、合并。如果两个元素的集合号不同,将两个元素合并为一个集合。擒贼先擒王,只改祖宗即可。
图解:
假设现在有7个人,通过输入亲戚关系图,判断两个人是否有亲戚关系。
(1)初始化


(2)输入亲戚关系2和7
(3)查找
查找2所在的集合号为2,7所在的集合号为7。
(4)合并
两个元素集合号不同,将两个元素合并为一个集合。在此约定把小的集合号赋值给大的集合号,因此修改father[7]=2。

查找方法:
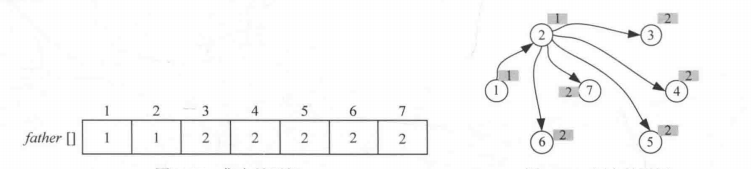
判断5和2是不是亲戚关系:
(1)查找5的父亲2,2的父亲1,1的父亲是1,搜索停止。5到其祖宗1这条路径上所有的结点集合号更新为1。
(2)查找2的父亲1,1的父亲是1,搜索停止。2到其祖宗1这条路径上所有的结点集合号更新为1。
(3)5和2的集合号都为1,所以5和2是亲戚关系。
Java代码实现:
public class WeightedQuickUnionUF {
private int[] id;
private int[] sz; //元素代表,某一家族成员数量
private int count;
public WeightedQuickUnionUF(int N) {
count = N; //初始有N的家族
id = new int[N];
for (int i = 0; i < N; i++) id[i] = i;
sz = new int[N];
for (int i = 0; i < N; i++) sz[i] = 1;
}
public int count() {
return count;
}
private int root(int i) {
while (i != id[i]) {
id[i] = id[id[i]]; //将子孙i指向的爸爸改为指向爷爷
i = id[i]; //子孙i更新为了爷爷i,
}
return i;
}
public boolean connected(int p, int q) {
return root(p) == root(q);
}
public void union(int p, int q) {
int i = root(q);
int j = root(p);
if (i == j) return;
//Make smaller root point to larger one.
//使小家族指向大家族,若家族j比家族i大
if (sz[i] < sz[j]) {
id[i] = j; //家族i指向家族j,叫家族j爸爸
sz[j] += sz[i]; //家族j的成员数量加上了家族i的成员数量
} else {
id[j] = i;
sz[i] += sz[j];
}
count--; //合并之和,家族种类数减1
}
}