《Reinforcement Learning: State-of-the-Art》 第三章 Least-Squares Methods for Policy Iteration 第五节 举例说明最小二乘法对策略迭代的行为。
将离线LSPI和在线乐观LSPI两种方法,应用于car-on-the-hill问题(Moore和Atkeson,1995),这是近似强化学习的经典benchmark。
由于其维度低,这个问题可以使用简单的线性逼近器来解决,基函数分布在等距网格上。 我们专注于算法的行为。
1.问题模型
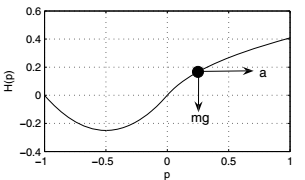
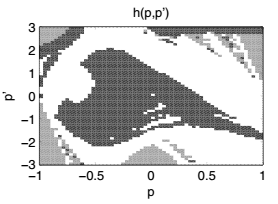
图1 左:山上的汽车,小车显示为黑色点。 右:近乎最优的策略(黑色表示a = -4,白色表示a = +4,灰色表示两个行为同样好)
在山上车问题中,必须通过施加水平力驱动质点小车越过无摩擦的山顶。 对于一些初始状态,由于可用力有限,必须首先将汽车向左侧,向上相反的斜坡驱动,并获得向右加速前朝向目标动量。
用 表示汽车的水平位置,它的动力学模型是(在Ernst等人,2005的变体中):
 (1)
(1)
是p坐标高度。
状态变量是位置和速度,![]() ,动作a是施加的力。使用0.1秒的离散时间步长。在相邻时间步之间对(1)式做数值积分,获得离散时间动态T。 因此,
,动作a是施加的力。使用0.1秒的离散时间步长。在相邻时间步之间对(1)式做数值积分,获得离散时间动态T。 因此, 和
是连续变量
和
的采样。 状态空间是
![]() 加上每当
加上每当 落在这些边界之外时达到的终止状态,并且离散动作空间是
![]() 。 目标是以允许的限度内的速度驶过山顶向右,而以任何其他方式到达终止状态被认为是失败。 为表达此目标,奖励设计如下:
。 目标是以允许的限度内的速度驶过山顶向右,而以任何其他方式到达终止状态被认为是失败。 为表达此目标,奖励设计如下:
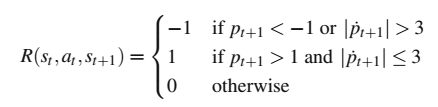
折扣回报。图1右侧是近似最优策略。
2.离线算法实现
使用等距13×13网格上的二维线性插值在状态空间上近似Q函数。为了在离散动作空间上表示Q函数,为两个离散动作存储单独的参数,因此近似值可以写为:
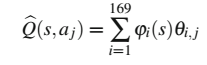
其中状态相关的基函数(BF) 提供插值系数,对于任何
,最多4个BF非零,并且
。通过复制状态相关的BF用于两个离散动作,该近似值可以以标准形式(2)编写,因此可以用于最小二乘方法进行策略迭代。
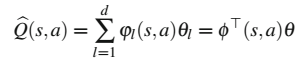 (2)
(2)
我们将这个逼近器的LSPI应用于 car-on-the-hill 问题。独立生成一组10 000个随机均匀分布的状态动作样本;重复使用这些样本来评估每个策略迭代的策略。通过这些设置,LSPI通常在7到9次迭代中收敛(从20次独立运行,当连续参数矢量之间的差异降至0.001以下时,认为实现了收敛)。图2 顶部展示了代表性的运行期间找到的策略的子序列。根据所选表示的分辨率限制,找到图1中的近似最优策略的合理近似值。

图2. 所考虑的算法找到的代表性政策子序列。 上:离线LSPI; 中:模糊Q迭代; 底部:在线LSPI。 对于轴和颜色含义,请参见图3.2,右边,另外注意到,当两个动作同样好时,负(黑色)动作是首选。
3.价值迭代算法
为了进行比较,我们还使用相同的逼近器和相同的收敛阈值运行近似价值迭代算法。 (实际的算法,称为模糊Q迭代,在Busüoniu等人(Approximate dynamic programming with a fuzzy parameterization. Automatica 46(5), 804–814)中描述;在这里,我们只关心它代表近似值迭代类的事实。)算法在45次迭代后收敛。经常在实践中观察到这种与策略迭代相比收敛较慢的情况。图 2 中间显示了价值迭代找到的策略的子序列。与我们考虑的策略算法一样,策略由近似Q函数隐式表示,特别是,通过最大化Q函数来选择动作,如![]() 。最终的解决方案与LSPI发现的解决方案不同,算法的收敛也不同: LSPI最初在每次迭代时在策略空间中进行大步骤(因此,例如,在第二次迭代之后策略的结构已经可见),而价值迭代产生较小的增量步骤。
。最终的解决方案与LSPI发现的解决方案不同,算法的收敛也不同: LSPI最初在每次迭代时在策略空间中进行大步骤(因此,例如,在第二次迭代之后策略的结构已经可见),而价值迭代产生较小的增量步骤。
4. 在线乐观LSPI算法实现(online, optimistic LSPI)
最后,将在线乐观的LSPI应用于car-on-the-hill。该实验运行1000秒的模拟时间,因此最终收集了10000个样本,就像离线算法一样。该间隔被分成单独的学习试验,在随机初始状态下初始化,在达到终端状态时停止,或者在3秒后停止。每10个样本(即,每1秒)执行一次策略改进,并使用ε-贪心探索策略(参见第1章),最初ε= 1并且指数衰减使其在在350秒后达到0.1。 图2 下排显示了代表性的运行期间发现的策略的子序列。在线LSPI在策略空间中比在离线LSPI的情况下采取更小的步,因为在相邻的策略改进之间,它处理更少的样本,这些样本来自状态空间的较小区域。实际上,在学习结束时,LSPI仅处理了每个样本一次,而离线LSPI在每次迭代时处理所有样本一次。

图3 与离线LSPI的比较,在线LSPI中的策略得分的演变。 从20次独立实验,95%置信区间的平均值。
图3显示了在线学习过程中在线LSPI获得的策略的性能,与离线LSPI发现的最终策略进行了比较。性能通过初始状态的等距网格上的平均经验回报来衡量,通过模拟评估,精度为0.001;我们称之为平均回报score。尽管理论上对其收敛性和近似最优性存在不确定性,但在线LSPI在经验上至少达到了与离线算法一样好的性能(令人兴奋的其他几个问题的结果,请参阅论文(Reinforcement Learning and Dynamic Programming Using Function Approximators,Bus¸oniu, L., 2010 第5章和Using prior knowledge to accelerate online least-squares policy iteration,Bus¸oniu, L., 2010 )。获得的价值迭代解的得分是0.219,略低于任一版本的LSPI得到的得分。
LSPI的执行时间约为34秒,在线LSPI的执行时间约为28秒,值迭代的执行时间约为0.3秒。这说明了这样一个事实,即策略迭代的收敛速度优势并不一定转化为计算时间的优势 - 因为每次策略评估都可以具有与整个价值迭代相当的复杂性。在我们的特定情况下,LSPI需要建立A,B和b的估计并求解线性方程组,而对于所采用的插值近似,每个近似值迭代减少到非常简单的参数更新。对于其他类型的近似值,价值迭代算法计算更加密集,但仍然倾向于比策略迭代算法需要更少的计算。另请注意,在线LSPI的执行时间远小于1000秒的模拟实验持续时间。