数据采集:selenium爬取美团全国酒店信息(一):https://blog.csdn.net/eighttoes/article/details/87364011
数据采集:selenium爬取美团全国酒店信息(二):https://blog.csdn.net/eighttoes/article/details/87377488
数据采集:selenium爬取美团全国酒店信息(四)使用代理:https://blog.csdn.net/eighttoes/article/details/87408709
上一篇完成了某一个城市的所有酒店信息的爬取,接下来需要获取全国所有城市的URL,然后逐个爬取。
数据在如下图片这里:
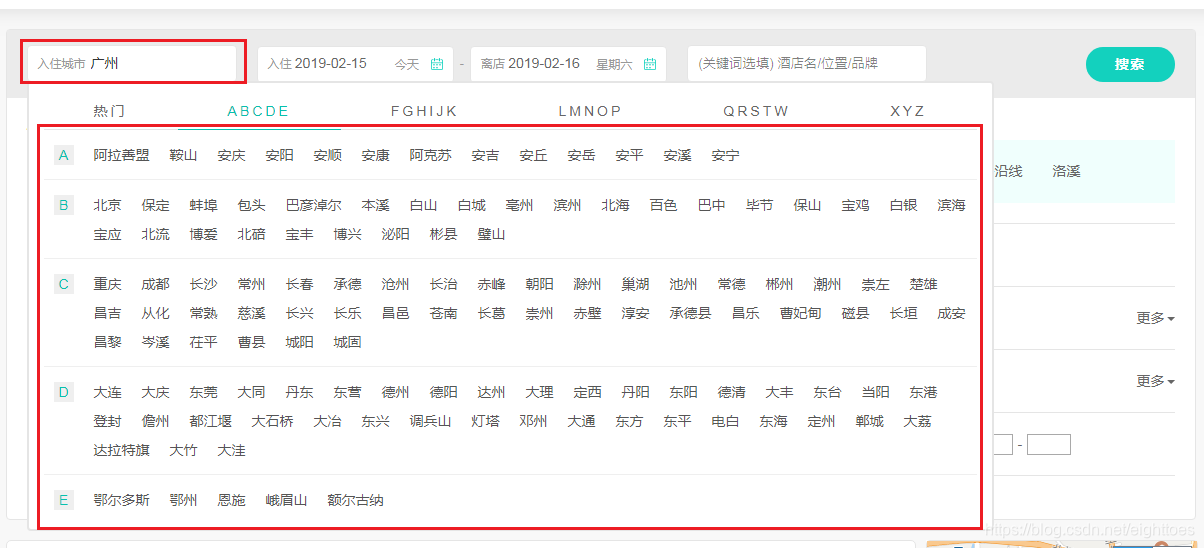
因为使用的是selenium,所以不管网站是怎么渲染的,直接源码中获取就可以了。
def parse_city(xhtml):
city_name = xhtml.xpath('//div[@class="classify-content"]/div/div[@class="classify-row"]/div/a/text()')
city_url = xhtml.xpath('//div[@class="classify-content"]/div/div[@class="classify-row"]/div/a/@href')
## 利用集合去重
city_set = set(zip(city_name, city_url))
city_tup = tuple(city_set)
return city_tup
函数返回一个元组city_tup,如果把这个city_tup,print出来,是下面这样的
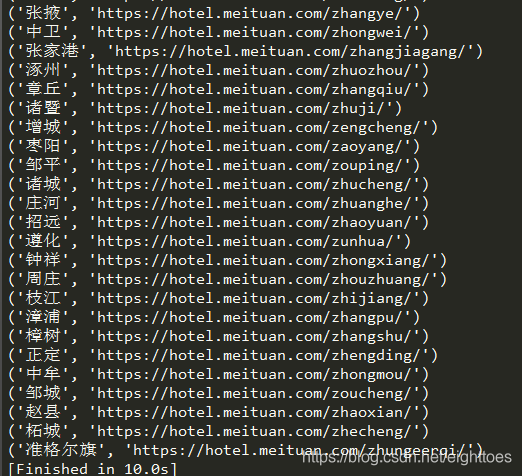
一般来说,只需要用for循环迭代这个city_tup,然后结合上一篇博文的代码,一个一个城市地爬取,这个爬虫就算完成了。
但是,现在需要考虑一个问题,利用selenium来做爬虫,效率是很低的,美团上记录的城市一个有811个,假设每一个城市爬取1分钟,就需要13.5个小时。在这10来个小时的过程中,很难保证IP不会被封禁,浏览器不会崩溃,或者一些奇奇怪怪问题出现。
所以,需要把这个city_tup保存起来,在爬虫遇到异常中断的时候,后续可以接着上一次的记录来爬取。
一开始我是把city_tup放到multiprocessing.Queue()队列当中的(为了方便用多进程做并发),但是程序异常中断之后,Queue中的记录也没了。
所以,我后来发觉还是放到redis的列表当中比较好,即使关机重启了,记录也还在。
redis存取操作如下:
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
## 往redis中存数据
for tup in city_tup:
r.lpush('meituan_tasks', tup)
print(r.llen('meituan_tasks'))
## 从redis中取数据
while r.llen('meituan_tasks'):
item = r.rpop('meituan_tasks')
item = tuple(eval(item.decode()))
print(item)