版权声明:最终解释权归汐银所有,转贴请私聊 https://blog.csdn.net/qq_39562468/article/details/83988167
在学习hive中我们首先练笔的应该是数据统计
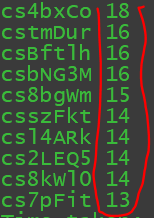
问题:用py爬取某网站用户名并通过hive分析用户发言次数前十
爬虫代码我就不列出来了
将其爬下来如何上传到linux,通过cat查看
然后我们将其上传到hive数据库
先进hive数据库
/usr/hive/apache-hive-2.1.1-bin/bin/hive创建表user
create table user(user_name string) row format delimited fields terminated by '#';解释:创建一个user库再创建一个名叫user_name格式为string的表,其中分割词为#
然后将数据导入到这个表
load data local inpath '/root/data/xm.txt' overwrite into table match_data;然后按照出现次数从大到小排序排出前十发言用户
select user_id,count(*) as np from user group by user_id order by np desc limit 10;解释:其中np为红色笔标注的姓名出现次数