生产者向topic中发送数据,消费者消费该topic对应的数据,为了提高吞吐量,生产者会将该topic对应的数据分别发送到多个partition,每个partition都有一定数量的副本作为备份,以提高kafka的高可用性。如下图所示:

原图请看:https://www.processon.com/diagraming/5c515d61e4b0641c83ee8064
生产者和消费者都只在leader副本上写读数据,三个leader副本平均分配在三个broker上,其他follower副本都只做备份,以防leader宕机,follower副本升级成为leader副本。
但是三个broker之间是有一定的策略进行数据的读写的,follower副本会隔指定的时间去leader副本上读取最新消息,包括元数据和日志消息。
下面我们来详细说一下kafka是如何复制leader副本的。
执行./kafka-topic.sh --describe --zookeeper 192.168.153.128:2181 --topic test_topic,我们看一下test_topic的详情
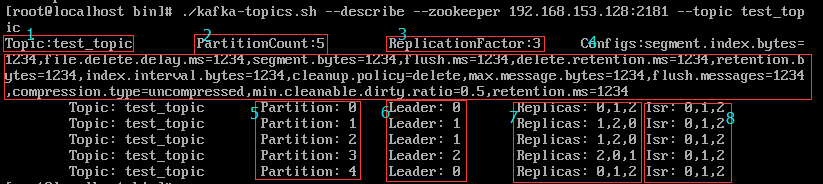
1、topic名称
2、分区数
3、副本因子
4、创建topic的各种配置参数,详情请参考:https://blog.csdn.net/qq_35689573/article/details/86702611
5、分区编号
6、每个分区对应的leader副本所在的broker节点编号
7、每个分区对应的副本所在的broker节点编号集合
8、isr:kafka维护的一个副本维护队列,leader负责维护和跟踪同步副本列表中所有follower滞后状态,消息提交之后才被成功复制到所有的同步副本,消息复制延迟受最慢的follower限制,如果某个follower落后太多或宕机,leader会把他从isr中剔除出去。那么该副本对应的分区也就称之为同步失效分区,即under-replicated分区。
kafka副本之间的负责有几个关键词:HW,LEO,ISR,under-replicated,fully replicated
HW:high watermark,是指ISR中所有节点都已经复制完的消息的offset。也是消费者所能获取到的消息的最大offset。
LEO:LogEndOffset,表示每个分区log的最后一条消息的offset
fully replicated:全量同步

当生产者发布消息到topic的某个分区时,消息首先被传递到leader副本,然后leader通知follower有新消息过来,follower去leader中拉取消息,一旦有足够的副本收到消息,leader就会提交这个消息,消费者就能消费到这个消息了。
我们前面说到如果副本发生故障,leader会把他从isr中剔除,那如果follower重启后呢?follower重启后会去leader上恢复最新的HW并将日志截断到HW,并继续从leader中获取HW以后的消息,一旦完全赶上leader,副本将被重新加入到ISR队列中,系统将重新回到fully replicated模式。
那如果leader发生故障呢,其他follower会争相竞争做leader,最终只有一个follower竞争成功升级成为leader,故障leader重启后成为follower去新leader同步消息。