别名
查询数据时,如果表名很长,使用起来不方便,此时,就可以为表取一个别名,用这个别名来代替表的名称 。同时为了更好的显示所查询出来的字段,也可以给字段取别名。
一,表作为别名:
mysql> select a.name,a.age from student as a; // a为别名 +--------+------+ | name | age | +--------+------+ | quert | 15 | | peilin | 20 | | 微微 | 21 | | 老晴 | 22 | | aa | 33 | +--------+------+ 5 rows in set (0.00 sec)
二,字段为别名
mysql> select a.name as 姓名,a.age as 年龄 from student as a; // 中文显示 +--------+------+ | 姓名 | 年龄 | +--------+------+ | quert | 15 | | peilin | 20 | | 微微 | 21 | | 老晴 | 22 | | aa | 33 | +--------+------+ 5 rows in set (0.00 sec)
条件
where子句(条件查询):按照“条件表达式”指定的条件进行查询
where常用的运输符:
| 运算符 | 说明 |
| 比较运算符 | |
| < | 小于 |
| <= | 小于或等于 |
| = | 等于 |
| != 或 <> | 不等于 |
| >= | 大于等于 |
| > | 大于 |
| in | 在某集合内 |
| between | 在某范围内 |
| 逻辑运算符 | |
| not 或 ! | 逻辑非 |
| or 或 || | 逻辑或 |
| and 或 && | 逻辑与 |

例如:
mysql> select * from student where id >3; +----+------+------+ | id | name | age | +----+------+------+ | 4 | 老晴 | 22 | | 18 | aa | 33 | +----+------+------+ 2 rows in set (0.00 sec)
分页(limit)
mysql> select * from student limit 1, 3; // 1表示偏移位置,3表示输出个数 +----+--------+------+ | id | name | age | +----+--------+------+ | 2 | peilin | 20 | | 3 | 微微 | 21 | | 4 | 老晴 | 22 | +----+--------+------+ 3 rows in set (0.00 sec)
排序(order by)
一,按照一个字段排序:
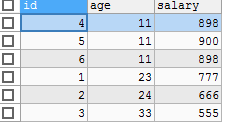
SELECT id, age, salary FROM tbs_test.`test_2` ORDER BY age;
查询出的字段如图所示
二,按照多个字段排序:
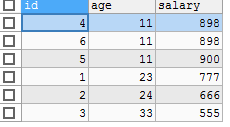
SELECT id, age, salary FROM tbs_test.`test_2` ORDER BY age, salary;
如下图:先对第一个字段排序,如果第一个字段相同的,用第二个字段排序。
分组(group by)
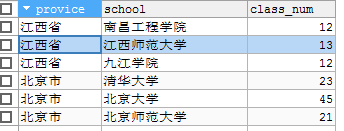
SELECT provice AS '省份', school AS '学校', class_num AS '班级数量' FROM tbs_test.`pro_school` GROUP BY provice;
原数据:
group by后的数据,看似没什么意义: 但是可以结合聚合函数进行使用。默认默认显示是是相同数据的第一条。

结合聚合示例:
SELECT provice AS '省份', SUM(class_num) AS '班级数量和' FROM tbs_test.`pro_school` GROUP BY provice;
查询出的数据:

聚合函数
常见的聚合函数
(1)max(列名):求最大值。 (2)min(列名):求最小值。 (2)sum(列名):求和。 (4)avg(列名):求平均值。 (5)count(列名):统计记录的条数。
max:
for the right syntax to use near 'selec * from klass' at line 1 mysql> select * from klass; +----+----------+-------+--------+-----------+ | id | name | grade | course | class_num | +----+----------+-------+--------+-----------+ | 1 | 三年八班 | 高三 | 数学 | 10 | | 2 | 三年八班 | 高三 | 语文 | 20 | | 3 | 三年八班 | 高三 | 美术 | 30 | | 4 | 三年八班 | 高三 | 语文 | 22 | | 5 | 二年八班 | 高二 | 语文 | 22 | | 6 | 二年八班 | 高二 | 数学 | 32 | | 7 | 二年八班 | 高二 | 英语 | 62 | | 8 | 二年八班 | 高二 | 体育 | 11 | +----+----------+-------+--------+-----------+ 8 rows in set (0.00 sec) mysql> select max(class_num) as 最多的课时, course,grade, name from klass; +------------+--------+-------+----------+ | 最多的课时 | course | grade | name | +------------+--------+-------+----------+ | 62 | 数学 | 高三 | 三年八班 | +------------+--------+-------+----------+ 1 row in set (0.00 sec)
min:
mysql> select * from klass; +----+----------+-------+--------+-----------+ | id | name | grade | course | class_num | +----+----------+-------+--------+-----------+ | 1 | 三年八班 | 高三 | 数学 | 10 | | 2 | 三年八班 | 高三 | 语文 | 20 | | 3 | 三年八班 | 高三 | 美术 | 30 | | 4 | 三年八班 | 高三 | 语文 | 22 | | 5 | 二年八班 | 高二 | 语文 | 22 | | 6 | 二年八班 | 高二 | 数学 | 32 | | 7 | 二年八班 | 高二 | 英语 | 62 | | 8 | 二年八班 | 高二 | 体育 | 11 | | 9 | 二年八班 | 高二 | 音乐 | 10 | +----+----------+-------+--------+-----------+ 9 rows in set (0.00 sec) mysql> select min(class_num) as 最多的课时, course,grade, name from klass; +------------+--------+-------+----------+ | 最多的课时 | course | grade | name | +------------+--------+-------+----------+ | 10 | 数学 | 高三 | 三年八班 | +------------+--------+-------+----------+ 1 row in set (0.00 sec)
注意:求最值时,若有两个值相同,先找到第一个就不往下找了。
其他函数就不一一介绍,用法一一致,这些聚合函数,结合分组才有更多的实际意义。
分组和聚合联合使用:
实例1:count 和 group by
mysql> select name, count(course) as 相同班级的课程数 from klass group by name; // 先对其进行分组,再用聚合函数求值 +----------+------------------+ | name | 相同班级的课程数 | +----------+------------------+ | 三年八班 | 4 | | 二年八班 | 5 | +----------+------------------+ 2 rows in set (0.00 sec)
实例2:max,min 和 group by
mysql> select name, max(class_num) as 不同年级的最大班级数 from klass group by name; +----------+----------------------+ | name | 不同年级的最大班级数 | +----------+----------------------+ | 三年八班 | 30 | | 二年八班 | 62 | +----------+----------------------+ 2 rows in set (0.00 sec) mysql> select name, min(class_num) as 不同年级的最大班级数 from klass group by name; +----------+----------------------+ | name | 不同年级的最大班级数 | +----------+----------------------+ | 三年八班 | 10 | | 二年八班 | 10 | +----------+----------------------+ 2 rows in set (0.00 sec)
实例3:avg 和 group by
mysql> select name, avg(class_num) as 不同年级的最大班级数 from klass group by name; +----------+----------------------+ | name | 不同年级的最大班级数 | +----------+----------------------+ | 三年八班 | 20.5000 | | 二年八班 | 27.4000 | +----------+----------------------+ 2 rows in set (0.00 sec)
分组聚合之having
having子句可以让我们筛选成组后的各种数据,where子句在聚合前先筛选记录,也就是说作用在group by和having子句前。而 having子句在聚合后对组记录进行筛选。
例如:
mysql> select name, count(course) as 相同班级的课程数 from klass group by name having 相同班级的课程数>4; +----------+------------------+ | name | 相同班级的课程数 | +----------+------------------+ | 二年八班 | 5 | +----------+------------------+ 1 row in set (0.00 sec)
注意:having 中筛选的字段必须在select中存在,否则查询会报错。
where和having的区别:
作用的对象不同。WHERE 子句作用于表和视图,HAVING 子句作用于组。
WHERE 在分组和聚集计算之前选取输入行(因此,它控制哪些行进入聚集计算), 而 HAVING 在分组和聚集之后选取分组的行。因此,WHERE 子句不能包含聚集函数; 因为试图用聚集函数判断那些行输入给聚集运算是没有意义的。 相反,HAVING 子句总是包含聚集函数。(严格说来,你可以写不使用聚集的 HAVING 子句, 但这样做只是白费劲。同样的条件可以更有效地用于 WHERE 阶段。)
在上面的例子中,我们可以在 WHERE 里应用数量字段来限制,因为它不需要聚集。 这样比在 HAVING 里增加限制更加高效,因为我们避免了为那些未通过 WHERE 检查的行进行分组和聚集计算。
综上所述:
having一般跟在group by之后,执行记录组选择的一部分来工作的。where则是执行所有数据来工作的。
再者having可以用聚合函数,如having sum(qty)>1000
例子:where + group by + having + 函数 综合查询
子查询
表数数据:
mysql> select * from student; +-----+--------+------+-------+------------+--------------+ | id | name | sex | birth | department | address | +-----+--------+------+-------+------------+--------------+ | 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | | 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | | 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 | | 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | | 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 | | 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | +-----+--------+------+-------+------------+--------------+ 6 rows in set (0.00 sec) mysql> select * from score; +----+--------+--------+-------+ | id | stu_id | c_name | grade | +----+--------+--------+-------+ | 1 | 901 | 计算机 | 98 | | 2 | 901 | 英语 | 80 | | 3 | 902 | 计算机 | 65 | | 4 | 902 | 中文 | 88 | | 5 | 903 | 中文 | 95 | | 6 | 904 | 计算机 | 70 | | 7 | 904 | 英语 | 92 | | 8 | 905 | 英语 | 94 | | 9 | 906 | 计算机 | 90 | | 10 | 906 | 英语 | 85 | +----+--------+--------+-------+ 10 rows in set (0.00 sec)
条件:查询出分数大于90分的学生。
mysql> select * from student where id in (select stu_id from score where grade>90); +-----+--------+------+-------+------------+--------------+ | id | name | sex | birth | department | address | +-----+--------+------+-------+------------+--------------+ | 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | | 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 | | 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | | 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 | +-----+--------+------+-------+------------+--------------+ 4 rows in set (0.00 sec)
连接查询
内连接(inner join)
元数据:
mysql> select * from student; +-----+--------+------+-------+------------+--------------+ | id | name | sex | birth | department | address | +-----+--------+------+-------+------------+--------------+ | 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | | 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | | 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 | | 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | | 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 | | 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | | 907 | 大哥 | 男 | 1990 | 数学系 | 江西赣州市 | +-----+--------+------+-------+------------+--------------+ 7 rows in set (0.00 sec) mysql> select * from score; +----+--------+--------+-------+ | id | stu_id | c_name | grade | +----+--------+--------+-------+ | 1 | 901 | 计算机 | 98 | | 2 | 901 | 英语 | 80 | | 3 | 902 | 计算机 | 65 | | 4 | 902 | 中文 | 88 | | 5 | 903 | 中文 | 95 | | 6 | 904 | 计算机 | 70 | | 7 | 904 | 英语 | 92 | | 8 | 905 | 英语 | 94 | | 9 | 906 | 计算机 | 90 | | 10 | 906 | 英语 | 85 | | 11 | 908 | 数学 | 90 | +----+--------+--------+-------+ 11 rows in set (0.00 sec)
where的方式:
mysql> select * from student,score where student.id = score.stu_id -> ; +-----+--------+------+-------+------------+--------------+----+--------+--------+-------+ | id | name | sex | birth | department | address | id | stu_id | c_name | grade | +-----+--------+------+-------+------------+--------------+----+--------+--------+-------+ | 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 1 | 901 | 计算机 | 98 | | 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 2 | 901 | 英语 | 80 | | 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 3 | 902 | 计算机 | 65 | | 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 4 | 902 | 中文 | 88 | | 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 | 5 | 903 | 中文 | 95 | | 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 6 | 904 | 计算机 | 70 | | 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 7 | 904 | 英语 | 92 | | 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 | 8 | 905 | 英语 | 94 | | 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 9 | 906 | 计算机 | 90 | | 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 10 | 906 | 英语 | 85 | +-----+--------+------+-------+------------+--------------+----+--------+--------+-------+ 10 rows in set (0.00 sec)
join 或 inner join 的方式: 这两种都是一样的
mysql> select * from student join score on student.id = score.stu_id; +-----+--------+------+-------+------------+--------------+----+--------+--------+-------+ | id | name | sex | birth | department | address | id | stu_id | c_name | grade | +-----+--------+------+-------+------------+--------------+----+--------+--------+-------+ | 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 1 | 901 | 计算机 | 98 | | 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 2 | 901 | 英语 | 80 | | 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 3 | 902 | 计算机 | 65 | | 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 4 | 902 | 中文 | 88 | | 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 | 5 | 903 | 中文 | 95 | | 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 6 | 904 | 计算机 | 70 | | 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 7 | 904 | 英语 | 92 | | 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 | 8 | 905 | 英语 | 94 | | 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 9 | 906 | 计算机 | 90 | | 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 10 | 906 | 英语 | 85 | +-----+--------+------+-------+------------+--------------+----+--------+--------+-------+ 10 rows in set (0.00 sec)
外连接(outer join)
left join(左外连接)
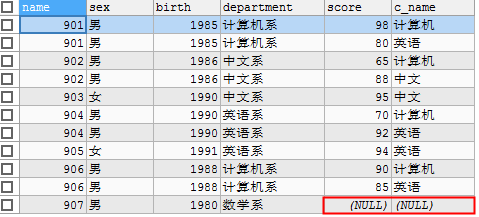
SELECT stu.id NAME, sex, birth, department, sco.`score`, sco.`c_name` FROM tbs_test.`student` AS stu LEFT JOIN tbs_test.`stu_score` AS sco ON stu.id=sco.`stu_id`;
结果如下显示:标红的这一字段,在分数表中没有数据,所以用空值显示。
right join(右外连接):
SELECT stu.id NAME, sex, birth, department, sco.`score`, sco.`c_name` FROM tbs_test.`student` AS stu RIGHT JOIN tbs_test.`stu_score` AS sco ON stu.id=sco.`stu_id`;
同理又外连接可的如下数据:分数表中有个数学在学生表中并没有,仍然显示,只不过学生信息用空值显示。
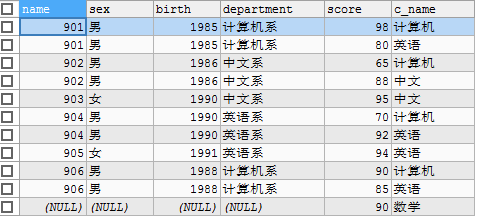
union all(union all)全连接查询
语句:
语句: (select colum1,colum2...columN from tableA ) union (select colum1,colum2...columN from tableB ) 或 (select colum1,colum2...columN from tableA ) union all (select colum1,colum2...columN from tableB );
union语句注意事项:
1.通过union连接的SQL它们分别单独取出的列数必须相同;
2.不要求合并的表列名称相同时,以第一个sql 表列名为准;
3.使用union 时,完全相等的行,将会被合并,由于合并比较耗时,一般不直接使用 union 进行合并,而是通常采用union all 进行合并;
4.被union 连接的sql 子句,单个子句中不用写order by ,因为不会有排序的效果。但可以对最终的结果集进行排序;
(select id,name from A order by id) union all (select id,name from B order by id); //没有排序效果 (select id,name from A ) union all (select id,name from B ) order by id; //有排序效果