前面博文我尝试安装了VMware虚拟机和Ubuntu测试系统。下面开始安装大数据基础工具Hadoop。主要包括:
安装SSH,安装jdk,安装Hadoop及单机部署测试,伪分布式部署测试,集群部署测试。
关于SSH安装调试及集群间免密登陆参考我的博文:
https://blog.csdn.net/qq_15903671/article/details/84964221
关于JDK安装参考我的博文:
https://blog.csdn.net/qq_15903671/article/details/84964226
一、安装Hadoop及单机部署测试
1.1 基本解压安装
Hadoop的单机运行很简单,只要最基本的安装包解压后配置jdk和必要的环境变量就可以直接运行。
安装包就自行百度吧,我将安装包放到/home/Hadoop路径下。
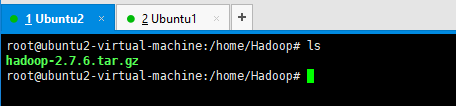
1.2 输入指令tar -zxvf hadoop-2.7.6.tar.gz 进行解压,解压后如下图所示
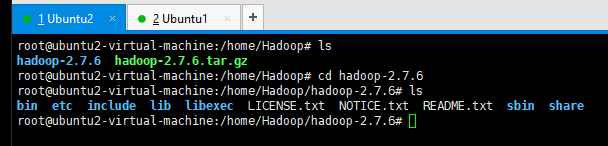
1.3 下面修改Hadoop的jdk依赖配置,在Hadoop根目录的下的etc/hadoop/hadoop-env.sh配置文件中。


还是老老实实在Ubuntu的可视化界面上用文本编辑器改吧。。。哈哈
注:这个文件可能是只读的,为了测试方便,可以使用root用户到Hadoop的根目录的上级目录下,使用shmod 777 hadoop(文件夹名称)命令让整个hadoop文件夹下的文件可被编辑。
1.4 修改环境变量,配置PATH信息。打开/etc/profile文件,新增HADOOP_HOME、HADOOP_CONF_DIR、PATH

由于jdk安装的时候配置了PATH,在后面补一下信息就好
输入指令 source /etc/profile 使配置立即生效。

1.5 单机运行试试效果
可以使用share/hadoop/mapreduce/路径下的测试jar包,使用hadoop命令运行试试看看
1.5.1 测试准备:输入输出文件及文件夹
在hadoop根目录下创建input文件夹,用来保存测试输入数据,测试程序将自动创建output文件夹。
mkdir input
cp etc/hadoop/*.xml input
留意上面指令,是在hadoop的根目录下运行的,会把Hadoop文件里相对路径为etc/hadoop/*.xml的所有文件都拷贝到input

1.5.2 执行测试程序
输入指令:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep input output 'dfs[a-z.]+'
或指令:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep input output3 '<name>[a-z.]+'


执行日志如图

其实上面还有好多日志,发现WARN io.ReadaheadPool: Failed readahead on ifile 字样,有博文说是快速读取文件时文件被关闭引起,也可能是其他bug,暂且不具体研究。
1.5.3 查看运行结果
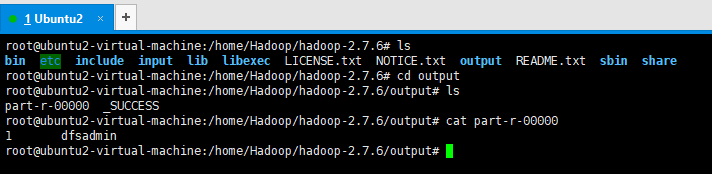
目前看,只找到了一条dfsadmin 与输入的匹配条件相吻合。

name标签的内容还是蛮多的。