以前在学习C的时候知道了编码格式,但并不是很了解他们的关系和其中的具体用法,例如:
ANSI: 无格式定义;(第一个字节开始就是文件内容)
Unicode: 前两个字节为FFFE;
Unicode big endian: 前两字节为FEFF;
UTF-8: 前两字节为EFBB,第三字节为BF
看起来似懂非懂,直到我学习c++,在学习动态库时,有一步是打开动态库:代码入下:
HMODULE hdll = LoadLibrary(L"mydll.dll");
这句里面就有L,那么这个L是干嘛的呢?他起什么作用呢?
先说L和_T的区别吧
在字符串前面加一个L,如L"mydll.dll"表示将ANSI字符转换成UNICODE字符串,就是每个字符占用两个字节.
strlen("abc") = 3;
strlenL("abc") = 6;
_T("")是一个宏,定义在tchar.h下. _T宏可以把引号里面的字符串根据你的环境设置,使得编译器会根据编译目标环境选择合适的字符处理方式(UNICODE还是ANSI)
如果你的编码格式是UNICODE,那么_T宏会在字符串前面加一个L,这时_T("abc")就相当于L"abc",这是宽字符.如果没有定义UNICODE,那么_T不会在字符串前面加L,这时_T("abc")相当于"abc".
附:TEXT,_TEXT,_T这三个是一样的(下面有代码演示)
①TCHAR auSTR1 = TEXT("str1");
②char auSTR2[] = "str2";
③WCHAR auSTR3[] = L"str3";
①在定义了UNICODE的时候会解释成③,没有定义UNICODE时等于②,而②无论是否定义了UNICODE都是生成ANSI字符串,而③总是生成UNICODE字符串
为了程序的可移植性,建议使用第一种方法,但在某些情况下,某个字符必须为ANSI或UNICODE,那就用下面两个方法
我们现在知道了_T和L的用法区别,那他们的区别是怎么来的呢?
windows的api有两种,一种是最后为A的,一种是最后为W的.如LoadLibraryA 和 LoadLibraryW
W 用于UNICODE,A用于ANSI.
但UNICODE更通用些,如果在英文版系统里,W的可以显示汉字,A的就不行
W和A的编码不同
A的在内存中英文占一个字节,汉字占两个字节
W的
UTF-16版本,英文占两个字节,汉字占两个字节
UTF-32版本,英文占四个字节,汉字占四个字节
为了更直观的看出用法和区别,下面代码送上
修改属性->配置属性->常规->字符集(使用UNICODE字符集)
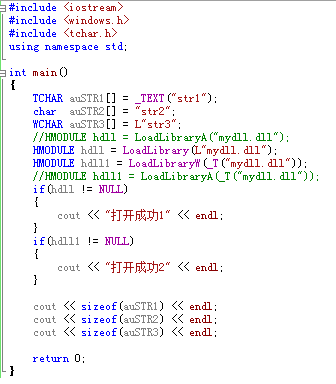

修改属性->配置属性->常规->字符集(使用多字节字符集)


对比两次运行的环境和加 // 的部分以及他们的运行结果,上面的结论都能得到证实.
每日一句
Fear not that the life shall come to and end,but rather fear that it shall never have a beginning.
不要害怕你的生活将要结束,应该担心你的生活永没有真正开始.