用户轨迹挖掘学习
现有的位置服务,通常直接使用用户提供的位置数据,缺乏对这些数据的分析和挖掘,忽略了这些位置数据中蕴含的信息和知识。
如何利用数据挖掘和机器学习等技术从个人及大众用户轨迹数据中获取知识,并利用这些知识来定制更加智能的基于轨迹的位置服务。
一:基于位置的服务(LBS)
轨迹记录了用户在真实世界中的活动,这些活动在一定程度上体现了个人的意图,喜好和行为模式。
从轨迹中可挖掘的知识包括:
1:个人数据中挖掘出的用户行为,意图,经验和生活方式
2:集合多人数据来发现热点地区和经典线路
3:理解人与人的相关性,以及人与地域之间的活动模式:
二:个人轨迹频繁模式挖掘
个人历史轨迹建模
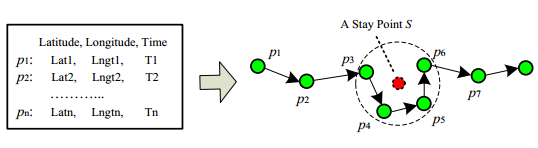
停留点进行聚类,利用各个停留点所归属的聚类来替换停留点,将停留点序列进一步转化为聚类的序列。
这样用户在不同时间阶段的历史轨迹可比
个人轨迹频繁模式挖掘
利用Aprior,FP_growth挖掘频繁项集
利用prefixspan算法挖掘序列模式
三:基于多人轨迹数据的大众旅游推荐
大众轨迹数据建模
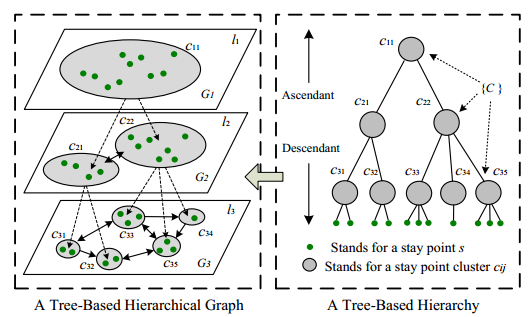
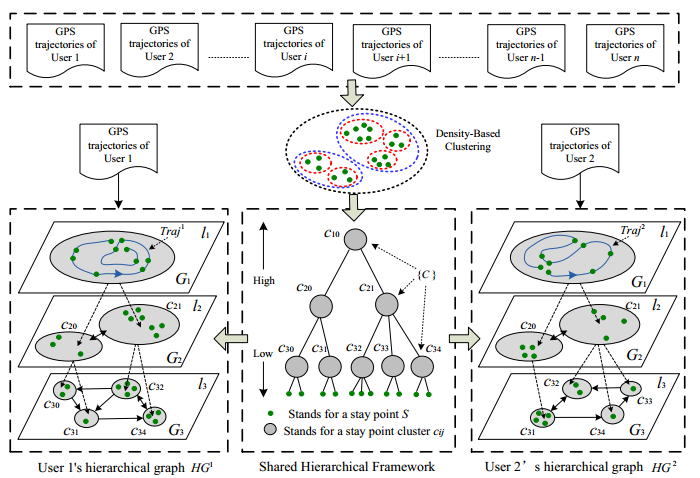
基于层次图模型的多用户轨迹聚合
从每个用户的每条线路中提取出停留点,放在集合中,然后利用一种基于密度的聚类算法,对停留点集合进行层次化聚类
在不同的地理尺度上,将相近的停留点划分到同一个聚类,得到一个层次树
树种的节点代表不同的停留点聚类,不同层次表示不同的地理空间尺度。
层次越深,粒度越细,代表的地理空间也越小。
发掘兴趣点(旅游地点)和旅行专家(旅行达人)
概览
每个地区(聚类)的兴趣度
每个用户的经验值(对一个地域的了解程度和所具备的经验值)
对地点按照兴趣度排名,对用户按照经验值排名
把具有较高排名的地区作为有趣的景点
把经验值较高的人作为本地的专家推荐给用户
如何计算兴趣度和人的经验值
一个人的经验值可表示为他去过的地方的兴趣度的和
一个地方的兴趣度可表示为所有访问过该地点的人的经验值的和
因此 给地点的兴趣度和人的经验值赋上非全零的随机初值,通过一个简单迭代的算法计算出最终的收敛结果。
区域性:
一个人的经验值跟地域有关系。比如一个北京的旅行专家可能对上海不是很熟悉。
如图:人的经验值和地点的兴趣度相互依赖和关联的关系
检测景点旅行线路
根据得到的地点兴趣度和人的经验值
1:选择这个顺序的人的经验值之和,即选择这个顺序的人越有经验,这个访问顺序可能越合理
2:这个顺序中包含的景点的兴趣度,如果一条线包含的景点越有趣,越值得被推荐
3:人们选择这个顺序的概率
如图:计算一个顺序的经典程度
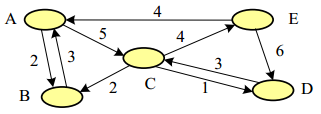
线路A->C的经典值:
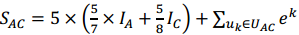
这里,IA 和IC表示地点A和地点C的兴趣度,e^k,为用户 UK的经验值,
5/7表示有7个人从A点离开,5个人选择了A->C这条路线。表示A点的兴趣度只有5 /7可以传播到这条线路上来
5/8表示有8人到达C,其中有5人来自A->C这条线路。表示C点的兴趣度只有5/8分配到A->C这条线路上来
进一步的,这个建模方法将挖掘景点旅行线路转化成一个带权值的最小生成树问题。
利用改进的最小生成树算法!就可以得TopN的旅行线路
四:个性化朋友和地点推荐
基于历史轨迹的人与人之间的相似度的计算
人在地理空间的移动的相似性,也在一定程度上反应了不同人之间的品味和爱好的相似性。
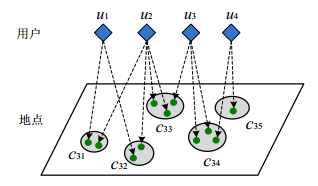
利用层次图来比较用户的相似性
方法:利用层次化聚类的思想将所有用户的停留点转化为一个公共的层次树,树种的各个节点表示不同
尺度和粒度的地点。此后,将每个用户的线路分别导入这个公共的框架,便可得到用户各自的层次图
通过匹配两个层次图来计算用户相似度
层次:较深的层次具有较细的空间粒度和尺度。两个用户在越深的层次上图越相似,活动轨迹越相似
相似序列的长度:用户共享的序列越多,序列的长度越长,相似性越大
个性化朋友和地点推荐
1:计算出用户之间的相似性,为某个用户找出最相似的n个人作为潜在的朋友,完成个性化朋友推荐
2:在潜在的朋友历史轨迹中查找出一些该用户没有去过的地点,并利用协同过滤的方法来估计该用户
对这些地点的兴趣度。
如图:用户和访问地点之间关系的矩阵表达式
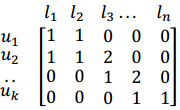
3:按照估算的兴趣度对用户去过的地点排名,并把排名较高的m个地点推荐给用户