摘要:GAN采用判别模型引导生成模型的训练在连续型数据上已经产生了很好的效果,但是有两个limitations,第一,当目标是离散数据时,如文本,不可能文本+1产生梯度信息引导生成器的生成;第二,判别模型只能对完整的序列产生判别信息,对于非完整序列,它并不知道当前的判别结果和未来完整序列的判别结果是否相同。SeqGAN可以解决这两个问题。采用强化学习的reward思想,实行梯度策略更新解决生成器的微分问题,即解决了第一个问题,采用Monte Carlo search将不完整的序列补充完整解决第二个问题。
SeqGAN:
给定真实序列数据集,训练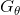
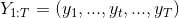
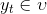
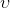
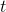

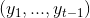

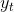
是随机的。此外,训练
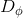


SeqGAN具体细节如下:
生成器模型(策略)目的是从开始状态
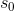
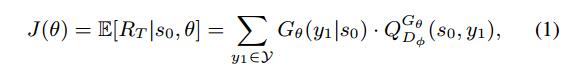
式中,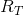
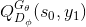
下一个问题是如何计算

然而判别器只对一个完整的序列提供reward值,因此采用MC搜索with a roll-out策略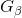
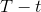
![]()
即产生N个序列。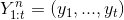
通过roll-out策略

采用

当我们有了判别器模型,我们就准备更新生成器。当action确定,状态转移是确定的,即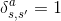
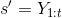
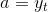
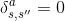
,重写action value如下:

对于初始状态

目标函数的梯度如下:

上面的形式是确定性的状态转移,即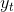

期望可以通过采样方法近似,因此更新生成器的参数:
![]()
整个算法如下:
