数据分析与挖掘建模实战-单因子探索分析与可视化
其他
2019-03-01 21:01:05
阅读次数: 0

理论铺垫:

-
集中趋势(数据聚拢的衡量)
- 均值:连续值的 中位数:异样值 衡量集中趋势 分位数:和其他几个值综合使用 众数:离散值
Q1 = (n+1) * 0.25
Q2 = (n+1) * 0.5
Q3 = (n + 1) * 0.75
-
离中趋势
-
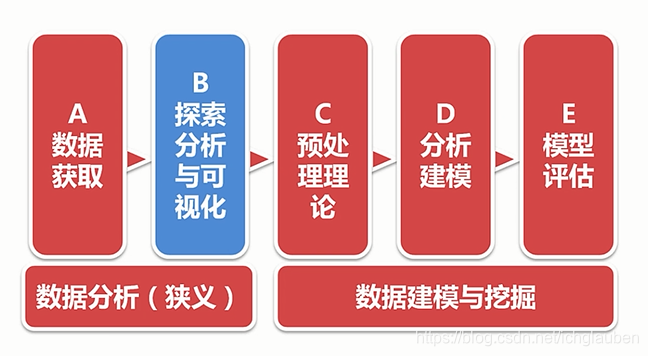
σ=N1∑i=1N(xi−μ)2
-
σ越小 表示数据越聚拢 越大 数据越离散
-
查看正态分布表
正态分布表

-
数据分布
- 偏态与峰度
- 偏态系数与峰态系数
- 偏态:数据偏离正态的衡量 偏:平均值的偏
- 正常:中位数和均值将接近 甚至相等 但是数据不一定对称分布 中位数和均值有差别
-
coefficient of skew:
S=(n1∑i=1n(xi−xˉ)2)23n1∑i=1n(xi−xˉ)3
-
S为正 正偏 表示均值偏大 - 负偏 均值小
-
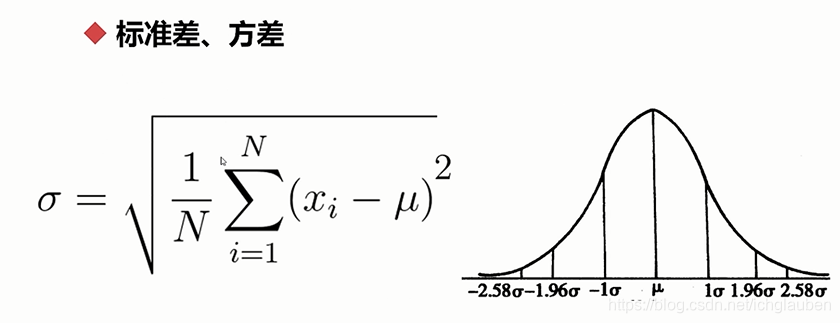
Kurtosis coefficient(峰态系数) 数据分布集中强度衡量 一般是3 若有个分布相差>2 判断不是正态分布了:
K=(n1∑i=1n(xi−xˉ)2)2n1∑i=1n(xi−xˉ)−4
-
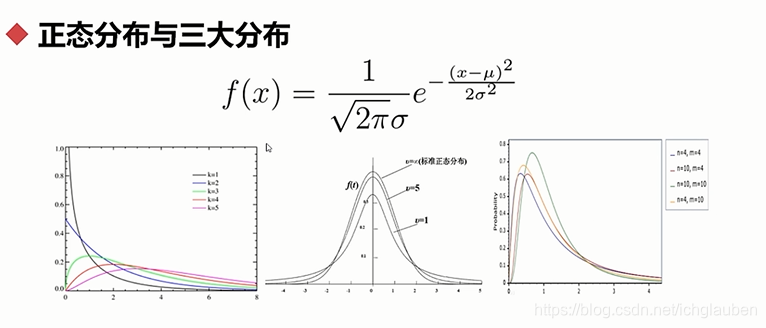
K方分布χ2分布:设 X1,X2,…Xn相互独立, 都服从标准正态分布N(0,1), 则称随机变量
χ2=X12+X22+......+Xn2所服从的分布为自由度为 n 的χ2分布
-
t分布 :设X1服从标准正态分布N(0,1),X2服从自由度为n的χ2分布,且X1、X2相互独立,则称变量t=X1/(X2/n)1/2 所服从的分布为自由度为n的t分布。
-
F分布 :设X1服从自由度为m的χ2分布,X2服从自由度为n的χ2分布,且X1、X2相互独立,则称变量F=(X1/m)/(X2/n)所服从的分布为F分布,其中第一自由度为m,第二自由度为n
-
抽样理论(全量检验无法实现
可以完全随机抽样 等差距抽样 分类分层抽样 会有误差 重复抽样 不重复抽样
- 抽样误差与精度
- 抽样平均误差计算公式:
- 重复抽样(放回抽样):
μx=nσ2
σ:总体方差 N:总体个数 n:抽样个数
- 不重复抽样
μx=nσ2(N−1N−n)
- 估计总体时抽样数目的确定:
- 重复抽样:
n=Δ2Zα/2δ2
- 不重复抽样:
n=NΔ2+Zα/2Δ2NZα/2δ2
-
δ2: 总体方差
Zα: 取到标准差相对于正值的距离 均值 + - 2
σ范围
Δ2:需要控制的方差
-
example:

- 保证在 95.45% 2 - 2
μx ,2 + 2
μx

转载自blog.csdn.net/ichglauben/article/details/85883577