目录
HuffmanTree
定义
哈弗曼树是一种优化的二叉树,称为最优二叉树,是加权路径长度最小的二叉树。所谓权值在这里指的是节点中的数据。
名词解释
节点的权值:权就相当于重要程度,通过一个具体的数字来表示
路径:在树中从一个节点到另一个节点的分支。
路径长度:一条路径上的分支数量。
树的路径长度:从树的根节点到每个节点的路径长度之和。
树的带权路径长度:树中各个叶子节点的路径长度*该叶子节点的权的和。
性质
1、根节点值是所有的叶子节点值相加得到
2、创建哈弗曼树的节点值全部在叶子节点上,而且只在叶子节点出现
3、哈夫曼树的加权路径长度是最小的,这个是因为权值大的节点离根节点近,权值小的节点离根节点远。
创建HuffmanTree
1. 由给定的n个权值{ w1, w2, w3, … , wn}构造n棵只有根节点的二叉树森林F={T1, T2 , T3, … ,Tn},每棵二叉树Ti只有一个带权值wi的根节点,左右孩子均为空。
2. 重复以下步骤,直到F中只剩下一棵树为止
- 在F中选取两棵根节点权值最小的二叉树,作为左右子树构造一棵新的二叉树,新二叉树根节点的权值为其左右子树根节点的权值之和
- 在F中删除这两棵二叉树
- 把新的二叉树加入到F中
定义HuffmanTree节点
二叉树的节点采用类模板的结构,而且用双亲孩子表示法构建链表。包括键值_val;父亲节点指针pParent,和左右孩子指针pLeft以及pRight。
template<class T>
struct HaffmanTreeNode
{
HaffmanTreeNode(const T& val)
:_val(val)
, pLeft(nullptr)
, pRight(nullptr)
, pParent(nullptr)
{}
T _val;
HaffmanTreeNode<T>* pLeft;
HaffmanTreeNode<T>* pRight;
HaffmanTreeNode<T>* pParent;
};构造函数
构造函数提供了以个,是空的构造函数,防止因为没有默认构造函数产生错误。另外又写了一个构造数的方法。
CreateHaffmanTree()
:pRoot(nullptr)
{}
参数解释
vector<CharInfo> v这个数组中存储的是权值的信息。
构建思想
构建哈夫曼树的方式在上面已经提到,但是如何用代码来实现呢?这里可以借用最小堆来实现。每次取最小堆的堆顶元素第一次是作为左节点,第二次作为右节点。同时将两者出堆,接着用两者的关键值创建一个父亲节点入堆。利用循环就可以创建出来哈弗曼树了。至于为什么要用最小堆,根据前述的方法,我们需要每次取数组中的最小的两个值来构建新的节点,用最小堆的话可以分两次取堆顶数据,然后让创建的新的节点再入堆。最小堆会自动调整,不需要人为参与修改。而且堆的存储机制就是动态增长的数组,天然符合这里利用数组传参的要求。其中这里传入给最小堆的数据类型是节点指针,为什么是节点指针很好理解。如果是节点本身,那么我们就没有办法将之前创建的内容链接在一起,见下图:

如果自己实现最小堆过于麻烦,所以这里我使用优先级队列。不过因为优先级队列默认是大队,所以必须自己写一个比较仿函数。如下 :
struct cmp
{
bool operator()(pNode& left, pNode& right)
{
return left->_val._count > right->_val._count;
}
};这里需要注意的是,仿函数的参数不能够定义为const对象。需要修改。
构建的代码如下:注意循环结束的条件是最小堆中只有一个元素,因为此时已经构建完成。
void GetHaffmanTree(std::vector<T>& v)
{
if (v.empty())
return;
std::priority_queue < pNode, std::vector<pNode>, cmp> q;
for (size_t i = 0; i < v.size(); ++i)
{
if (v[i]._count != 0)
{
pNode node = new Node(v[i]);
q.push(node);
}
}
while (q.size() > 1)
{
pNode left = q.top();
q.pop();
pNode right = q.top();
q.pop();
pNode parent = new Node(left->_val + right->_val);
parent->pLeft = left;
parent->pRight = right;
left->pParent = parent;
right->pParent = parent;
q.push(parent);
}
pRoot = q.top();
}析构函数
析构函数通过调用Destroy函数实现,而Destroy函数通过递归实现。
~CreateHaffmanTree()
{
Destroy(pRoot);
}
private:
void Destroy(pNode root)
{
if (nullptr == root)
return;
Destroy(root->pLeft);
Destroy(root->pRight);
delete root;
root = nullptr;
}获取根节点
pNode GetRoot()
{
return pRoot;
}文件压缩及解压缩
有了哈弗曼树,我们就可以利用哈弗曼树创建哈夫曼编码,通过哈夫曼编码可以实现文件压缩的功能。
哈夫曼编码
所谓哈夫曼编码是在哈弗曼树的基础上,定义向左的路径为零,向右的路径为一。这样定义以后,每一个叶子节点都会有一个唯一的编码值。而重要的是,在哈弗曼树中,所有叶子节点就是我们用来构建哈弗曼树的原值。
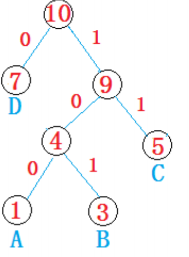
需要注意的是,哈夫曼编码不是唯一的,就算是同样的原值,因为插入的顺序不一样会导致不同的编码,但是毋庸置疑的是,每一个叶子节点一定会有唯一的编码值。
压缩思路
1. 打开被压缩文件,获取文件中每个字符串出现的总次数。
2. 以每个字符出现的总次数为权值构建huffman树。
3. 通过huffman树获取每个字符的huffman编码。
4. 读取源文件,对源文件中的每个字符使用获取的huffman编码进行改写,将改写结果写到压缩文件中,直到文件结束。
压缩文件格式
举例:ABBBCCCCCDDDDDDD
假设按照上述操作已经对源文件压缩完毕,怎么解压缩?解压缩之后文件的后缀怎么与源文件保持一致?因此:压缩文件中除了保存压缩数据外,还必须保存解压缩所需的信息。压缩文件格式:

解压缩
1. 从压缩文件中获取源文件的后缀
2. 从压缩文件中获取字符次数的总行数
3. 获取每个字符出现的次数
4. 重建huffman树
5. 解压压缩数据
a. 从压缩文件中读取一个字节的获取压缩数据ch
b. 从根节点开始,按照ch的8个比特位信息从高到低遍历huffman树:
- 该比特位是0,取当前节点的左孩子,否则取右孩子,直到遍历到叶子节点位置,该字符就被解析成功
- 将解压出的字符写入文件
- 如果在遍历huffman过程中,8个比特位已经比较完毕还没有到达叶子节点,从a开始执行
c. 重复以上过程,直到所有的数据解析完毕