整体方案
日志文件以固定大小进行切割,使用filebeat监控日志目录,实时采集写入kafka中,并通过python kafka消费入库。

Filebeat
Filebeat是本地文件的日志数据采集器,监听日志目录或特定文件,并将它们转发给ElastickSearch、Logstash、Kafka中。它由三个主要组件组成:
- Prospector
负责检测指定日志目录或文件,并对检测到的每个日志文件,filebeat启动一个收割进程(harvester),Filebeat目前支持两种Prospector类型:log和stdin,每个Prospector类型可以在配置文件中定义多个 - Harvester
负责读取单个文件内容,harvester负责文件的打开和关闭,并将读取到的新内容发送到处理程序(spooler) - Spooler
集合harvester发送的数据,并将数据发送到指定地点。
Filebeat保持每个文件的状态,并频繁地将Harvester上次读取文件的位置从注册表更新到磁盘,确保将全部的日志数据读取出来。如果output出行故障,Filebeat会将最后的文件读取位置保存下来,直到output恢复快速地对文件进行读取;如果Filebeat故障重启,会从注册表恢复重启之前的状态信息,让Filebeat继续从之前已知的位置开始进行读取。

Kafka
Kafka是由Scala和Java编写的一种高吞吐量的分布式发布订阅消息系统,并且支持消息的持久化。相关术语介绍:
- Broker
Kafka集群的每个节点称为Broker
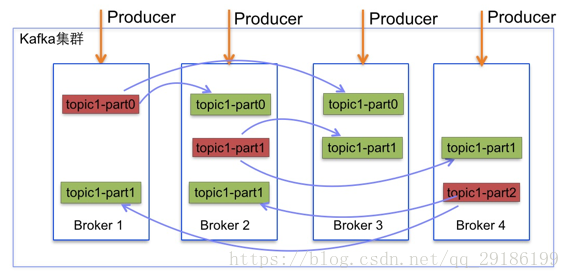
- Topic
消息的分类,消息发送到指定的Topic中,Topic由多个Partition组成
- Partition
Partition由一系列有序不可变的消息组成,物理上由多个Segment组成 - Segment
由index file和data file组成,这两个文件一一对应,后缀分别为“.index”,“.log”,表示索引文件和数据文件。索引文件存放的是相对偏移量,关系图如下:

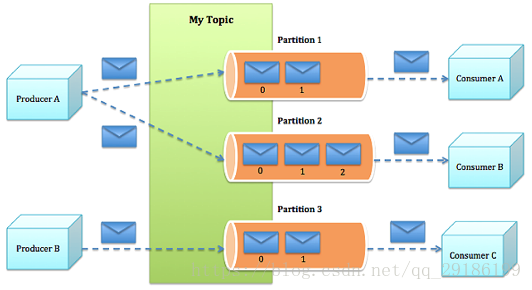
- Producer
向Kafka集群发送消息,可以发送到指定分区,也可以指定均衡策略,不指定默认采取随机均衡,消息随机发送到不同分区中。 - Consumer
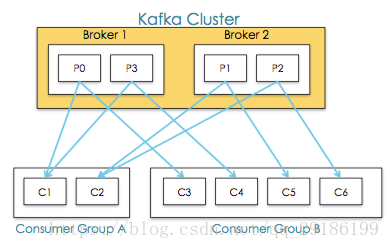
Kafka使用offset来记录当前消费位置,可以有多个group来同时消费同一topic下的消息,如果有两个不同的group同时消费,它们的消费记录位置offset互不干扰。 - Consumer Group
每个Consumer属于一个特定的Consumer Group,可为每个Consumer指定group name,若不指定则属于默认group。消费者的数量应该小于等于分区数量,因为在一个group中,每个分区只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费。
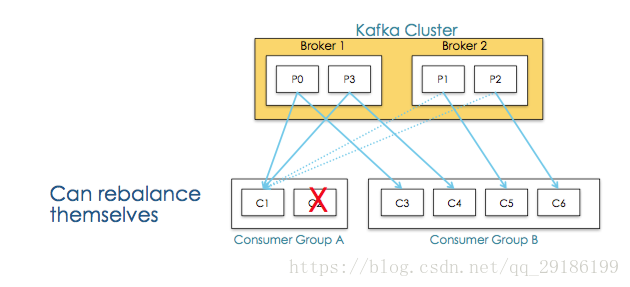
新消费者加入消费组,它将消费一个或多个分区;消费者离开消费组,它所消费的分区分配给其他消费者,这种现象称为重平衡(rebalance),重平衡期间,所有消费者都不能消费消息,会造成短暂的不可用。
Python Kafka
Python Kafka为Kafka消息消费的Python客户端,
官网地址:https://pypi.org/project/kafka-python/
开发之前,需要安装Python Kafka库:
>>> pip install kafka-python
完整代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import logging
import json
import threading
from pymysql import connect
from kafka import KafkaConsumer, TopicPartition, OffsetAndMetadata
class mysqlSink:
def __init__ (self,
host,
user,
passwd,
db,
port,
charset
):
self.host = host
self.user = user
self.passwd = passwd
self.db = db
self.port = port
self.charset= charset
self.conn = None
self.cursor = None
self.index = 0
self._conn()
# 建立连接
def _conn (self):
try:
self.conn = connect(host=self.host, port=self.port, db=self.db, user=self.user, password=self.passwd, charset=self.charset)
self.cursor = self.conn.cursor()
return True
except:
return False
# 重建连接
def _reConn (self, num = 3600, stime = 3):
_number = 0
_status = True
while _status and _number <= num:
try:
self.conn.ping() #cping 校验连接是否异常
_status = False
except:
if self._conn() == True: #重新连接,成功退出
_status = False
break
_number += 1
time.sleep(stime) #连接不成功,休眠3秒钟,继续循环,知道成功或重试次数结束
# 处理数据
def handle (self, sql, record, consumer, tp):
try:
message = json.loads(record.value)['message']
values = message.split('\t')
self.index = self.index + 1
#self._reConn()
self.cursor.execute(sql, tuple(values))
if self.index % 5000 == 0:
self.conn.commit()
# manually commit offset
committed_offset = consumer.committed(tp)
position = consumer.position(tp)
logging.info("[partition: %s, last committed offset: %s, current offset: %s, next offset: %s]: offset commit" % (record.partition, committed_offset, record.offset, position))
consumer.commit(offsets={tp:(OffsetAndMetadata(record.offset, None))})
#self.cursor.close()
#self.cursor = self.conn.cursor()
self.index = 0
except Exception as e:
#抛出异常
raise Exception("Handle Exception[%s]: { partition: %s, offset: %s, value: %s }" % (e, record.partition, record.offset, record.value))
# 关闭连接
def close (self):
self.cursor.close()
self.conn.close()
# 消费线程
class consumerThread (threading.Thread):
def __init__(self, threadName, topic, partition):
threading.Thread.__init__(self)
self.threadName = threadName
self.topic = topic
self.partition = partition
def run(self):
messageConsumer(self.threadName, self.topic, self.partition)
def stop(self):
sys.exit()
# 消费处理
def messageConsumer(threadName, topic, partition):
print('%s is running...' % threadName)
consumer = KafkaConsumer(group_id='my_group_new',
client_id=threadName,
bootstrap_servers=['127.0.0.1:9092'],
enable_auto_commit=False)
tp = TopicPartition(topic, partition)
consumer.assign([tp])
committed_offset = consumer.committed(tp)
end_offset = consumer.end_offsets([tp])[tp]
logging.info('partition: %s, last committed offset: %s, the lastest offset: %s' % (partition, committed_offset, end_offset))
#manually specify offset
consumer.seek(tp, committed_offset + 1)
sink = mysqlSink('10.10.2.110','root','root','test',3306,'utf8')
sql = 'insert into ad_request_event (app_version,city_id,adsense_code,ad_id,create_time,request_time) values (%s,%s,%s,%s,%s,%s)'
try:
for record in consumer:
sink.handle(sql, record, consumer, tp)
except BaseException as e:
print('%s Exit' % threadName, e)
logging.error(e)
sink.close()
# 主函数
if __name__=='__main__':
#日志配置
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='consumer.log',
filemode='a')
thread1 = consumerThread("Consumer-0", "request_event_log", 0)
thread2 = consumerThread("Consumer-1", "request_event_log", 1)
thread1.start()
thread2.start()
thread1.join()
thread2.join()