前言
伟大领袖毛主席说过——手中有粮,心就不慌。服务器的日常管理,离不开关键指标的监控,无论是防患于未然,还是意外发生之后尽快还原故障真相,靠的便是完善的监控体系。只有对系统实现了360°监控,才能对线上的业务放心,而不是当问题发生时,手忙脚乱,只会说“我擦,怎么又挂了”。接下来,我们一起来学习下哪些指标是需要关心的、各自代表啥意思、如何监控这些指标及发现不良运行状态后如何处理。
服务器常用监控指标
服务器常用的监控项有CPU、Memory、Load、Disk、Disk I/O、Network等。这是通用的监控指标,除此之外,各自业务的监控系统也很重要,需要精通业务的开发人员diy监控项了,仅作提醒。下面是对每种类型的介绍:
-
CPU相关
计算方法:通过查看/proc/stat来得到,可以参考sar命令的统计输出来理解。cpu.idle:CPU或CPU空闲且系统没有未完成的磁盘I / O请求的时间百分比。 cpu.busy:与cpu.idle相对,他的值等于100减去cpu.idle。 cpu.guest:CPU或CPU运行虚拟处理器所花费的时间百分比。 cpu.iowait:CPU或CPU空闲的时间百分比,在此期间系统具有未完成的磁盘I / O请求。 cpu.irq:CPU或CPU为硬件中断服务所花费的时间百分比。 cpu.softirq:CPU或CPU用于服务软件中断所花费的时间百分比。 cpu.nice:在具有良好优先级的用户级别执行时发生的CPU利用率百分比。 cpu.steal:虚拟机管理程序为另一个虚拟处理器提供服务时虚拟CPU或CPU无意中等待所花费的时间百分比。 cpu.system:在系统级别(内核)执行时发生的CPU利用率百分比。 cpu.user:在用户级别(应用程序)执行时发生的CPU利用率百分比。 cpu.cnt:cpu核数。 cpu.switches:cpu上下文切换次数,计数器类型。 -
内存相关
计算方法:读取/proc/meminfo 中的内容,其中的mem.memfree是free+buffers+cached,mem.memused=mem.memtotal-mem.memfree。可以参考free命令的输出和帮助文档来理解每个metric的含义。root@iZ2zeic9ggky8lb31din1gZ:~# cat /proc/meminfo MemTotal: 2048124 kB MemFree: 208772 kB MemAvailable: 1286472 kB Buffers: 196852 kB Cached: 939116 kB SwapCached: 0 kB Active: 1020548 kB Inactive: 603520 kB Active(anon): 488732 kB Inactive(anon): 37648 kB Active(file): 531816 kB Inactive(file): 565872 kB Unevictable: 0 kB Mlocked: 0 kB SwapTotal: 0 kB SwapFree: 0 kB Dirty: 0 kB Writeback: 0 kB AnonPages: 488144 kB Mapped: 207928 kB Shmem: 38280 kB Slab: 187916 kB SReclaimable: 168004 kB SUnreclaim: 19912 kB KernelStack: 3680 kB PageTables: 7440 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 1024060 kB Committed_AS: 1557344 kB VmallocTotal: 34359738367 kB VmallocUsed: 0 kB VmallocChunk: 0 kB HardwareCorrupted: 0 kB AnonHugePages: 6144 kB CmaTotal: 0 kB CmaFree: 0 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB DirectMap4k: 59264 kB DirectMap2M: 2037760 kB DirectMap1G: 0 kB -
负载相关
计算方法:读取/proc/loadavg,都是原始值类型的:
load.1min load.5min load.15min,分别表示系统在过去1分钟、5分钟、15分钟内运行进程队列中的平均负载。
具体来说:
0.00-1.00 之间的数字表示此时路况非常良好,没有拥堵,车辆可以毫无阻碍地通过。
1.00 表示道路还算正常,但有可能会恶化并造成拥堵。此时系统已经没有多余的资源了,管理员需要进行优化。
1.00-*** 表示路况不太好了,如果到达2.00表示有桥上车辆一倍数目的车辆正在等待。这种情况你必须进行检查了。
如果是多核CPU - 多车道 - 数字/CPU核数 在0.00-1.00之间正常
多核CPU的话,满负荷状态的数字为 “1.00 * CPU核数”,即双核CPU为2.00,四核CPU为4.00。 -
磁盘相关
计算方法:先读取/proc/mounts拿到所有挂载点,然后通过syscall.Statfs_t拿到blocks和inode的使用情况。每个metric都会附加一组tag描述,类似mount=mount,fstype=mount,fstype=fstype,其中mount是挂载点,比如/home,mount是挂载点,比如/home,fstype是文件系统,比如ext4。df.bytes.free:磁盘可用量,int64 df.bytes.free.percent:磁盘可用量占总量的百分比,float64,比如32.1 df.bytes.total:磁盘总大小,int64 df.bytes.used:磁盘已用大小,int64 df.bytes.used.percent:磁盘已用大小占总量的百分比,float64 df.inodes.total:inode总数,int64 df.inodes.free:可用inode数目,int64 df.inodes.free.percent:可用inode占比,float64 df.inodes.used:已用的inode数据,int64 df.inodes.used.percent:已用inode占比,float64 -
磁盘 I/O 相关
计算方法:每秒读取一次/proc/diskstats,计算差值,都是计数器类型的。每个metric都会有一组tag描述,形如device=$device,用来表示具体的设备,比如sda1、sdb。可以参考iostat的帮助文档来理解具体的metric含义。disk.io.ios_in_progress:当前正在进行的实际I / O请求数。 disk.io.msec_read:所有读取花费的总ms数。 disk.io.msec_total:ios_in_progress> = 1的时间。 disk.io.msec_weighted_total:衡量最近的I / O完成时间和积压。 disk.io.msec_write:所有写入花费的总ms数。 disk.io.read_merged:在单个req中合并的相邻读取请求。 disk.io.read_requests:成功完成的读取总数。 disk.io.read_sectors:成功读取的扇区总数。 disk.io.write_merged:在单个req中合并相邻的写入请求。 disk.io.write_requests:成功完成的写入总数。 disk.io.write_sectors:成功写入的扇区总数。 disk.io.read_bytes:单位是字节的数字 disk.io.write_bytes:单位是字节的数字 disk.io.avgrq_sz:下面几个值就是iostat -x 1看到的值 disk.io.avgqu-SZ disk.io.await disk.io.svctm disk.io.util:磁盘IO利用百分数,比如56.43,56.43表示%。 -
网络相关
计算方法:读取/proc/net/dev的内容,每个metric都附加有一组tag,形如iface=$iface,标明具体那个interface,比如eth0。metric中带有in的表示流入情况,out表示流出情况,total是总量in+out,支持的metric如下:net.if.in.bytes net.if.in.compressed net.if.in.dropped net.if.in.errors net.if.in.fifo.errs net.if.in.frame.errs net.if.in.multicast net.if.in.packets ==net.if.out.bytes== 网卡每秒向外传输的数据量 net.if.out.carrier.errs net.if.out.collisions net.if.out.compressed net.if.out.dropped net.if.out.errors net.if.out.fifo.errs net.if.out.packets ==net.if.total.bytes== 网卡每秒发送和接收的数据量 net.if.total.dropped net.if.total.errors net.if.total.packets
常用监控工具介绍
linux服务器上,可用的监控工具非常非常多,大家只要挑选一种比较全面的,适合自己的,用熟练即可。这里我推荐几款的监控工具:
- 命令行的
- nmon
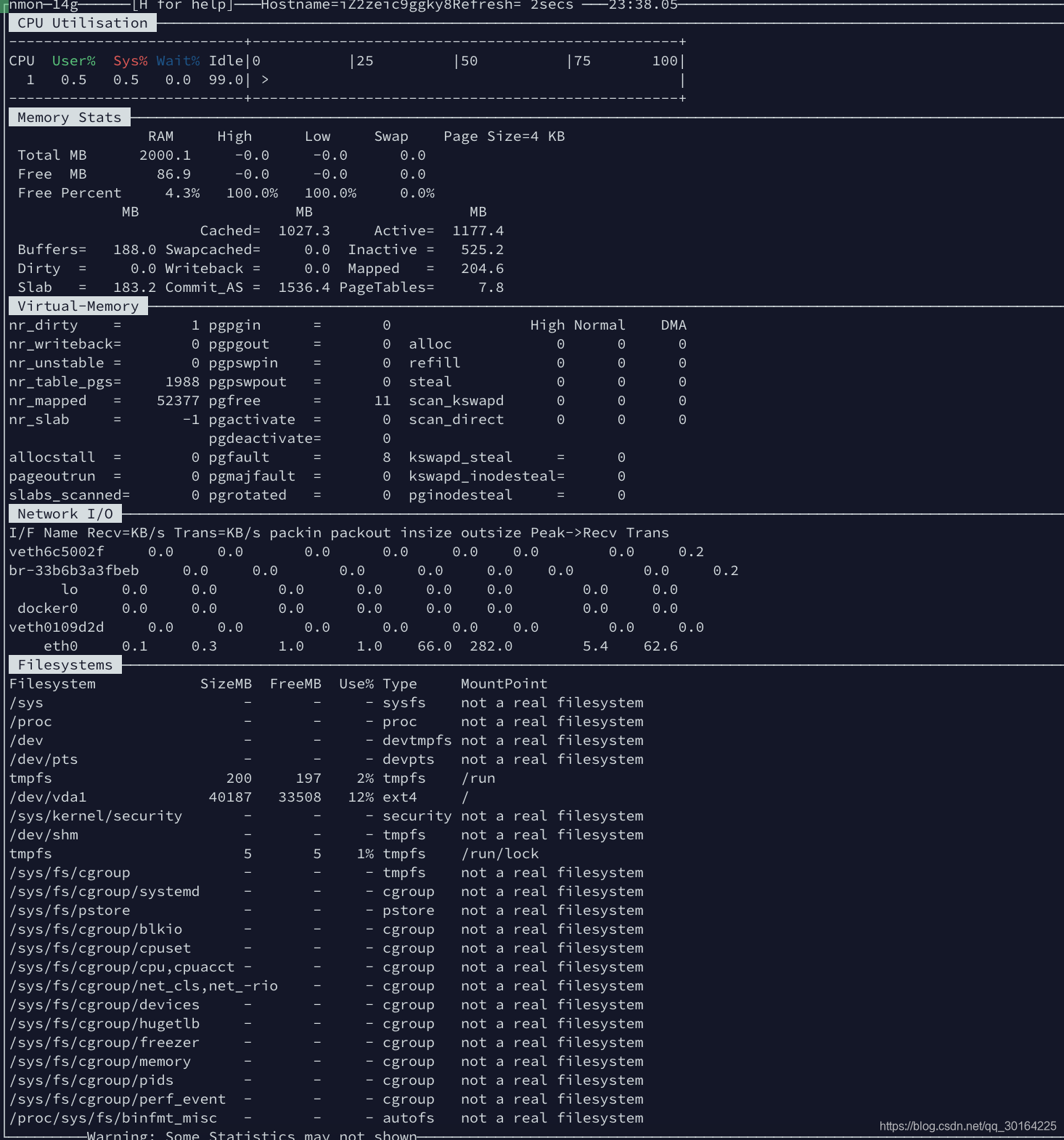
Nmon是Nigel’s Monitor缩写,它最早开发用来作为AIX的系统监控工具。如果使用在线模式,可以使用光标键在屏幕上操作实时显示在终端上的监控信息。使用捕捉模式能够将数据保存为CSV格式,方便进一步的处理和图形化展示。它能提供实施全面的系统参数情况,非常不错。
下面是nmoon对系统实时采集的数据监控:
2. top类
top类提供了各种各样的相关监控,例如:监控流量的iftop、磁盘I/O的iotop、apache的apachetop、ftp上传和下载的ftptop、mysql的mytop等等。
- 图形化的
专业化的监控工具不仅提供了指标的监控,而且具备完整的生态圈,自定义触发器和自定义监控告警等等,例如下面两个非常著名的监控工具:
- Nagios
Nagios提供对多种操作系统和发行版的完整监控 - 包括操作系统指标,服务状态,进程状态,文件系统使用情况等。当您使用Nagios监控Linux环境时,您正在使用地球上最强大的Linux监控工具之一。 - Zabbix
Zabbix 是一个免费的企业级分布式开源监控解决方案。
Zabbix 软件能够监控众多网络参数和服务器的健康度、完整性。Zabbix 使用灵活的告警机制,允许用户为几乎任何事件配置基于邮件的告警。这样用户可以快速响应服务器问题。Zabbix 基于存储的数据提供出色的报表和数据可视化功能。这些功能使得 Zabbix 成为容量规划的理想选择。
Zabbix 支持主动轮询和被动捕获。所有的 Zabbix 报告、统计信息和配置参数都可以通过基于 Web 的前端页面进行访问。基于 Web 的前端页面确保您的网络状态和服务器健康状况等可以从任何地方访问。在经过适当的配置后,Zabbix 可以在监控 IT 基础设施方面发挥重要作用。无论是对于拥有少量服务器的小型组织,还是拥有大量服务器的大型公司而言,同样适用。
中文文档地址:https://www.zabbix.com/documentation/4.0/zh/manual/introduction/about
另外,各种层出不穷的监控工具还有很多,大家可以自行去寻找,只要能解决问题的,都是好的。接下来我们将一起看下,各种指标监控触发阈值之后,应该如何应对和排查问题。