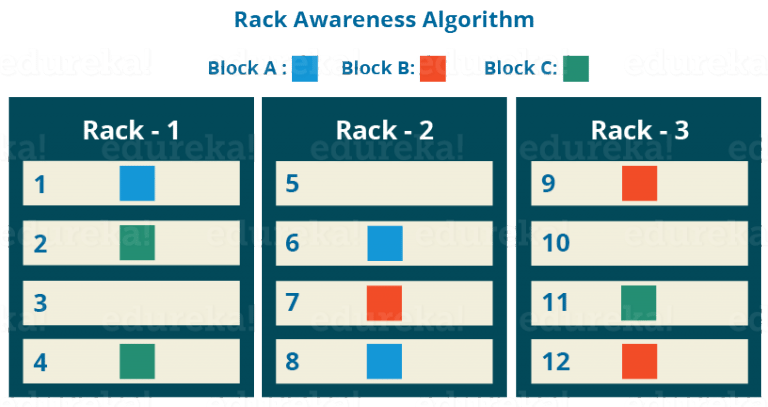
为了提供Fault Tolerance,Hadoop Namenode在获取rack id后,会将Block复制几份存放在不同的rack中。该算法称为Rack Awreness, 如下图
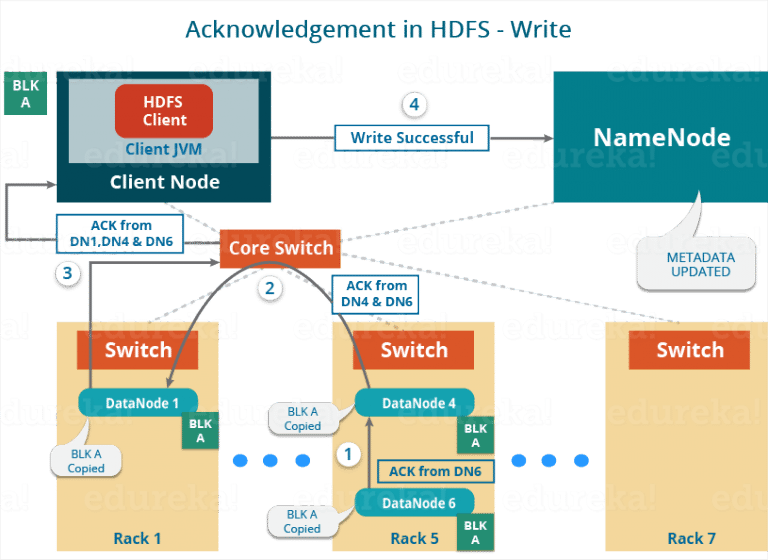
HDFS 写流程:
1. 建立pipline

2. Streaming Data

3.Shutdown and Acknoledgement:
多Blocks的并行操作:
For Block A: 1A -> 2A -> 3A -> 4A
For Block B: 1B -> 2B -> 3B -> 4B -> 5B -> 6B

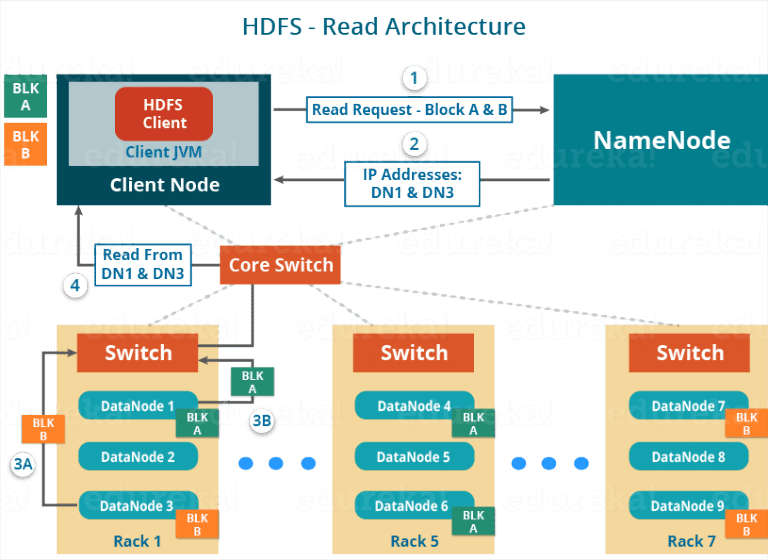
HDFS Read:
https://www.edureka.co/blog/apache-hadoop-hdfs-architecture/#datanode
https://www.coursera.org/learn/big-data-essentials/lecture/JmzZr/block-and-replica-states-recovery-process-1