| 论文名和编号 |
摘要/引言 |
相关背景和工作 |
论文方法/模型 |
实验(数据集)及 分析(一些具体数据) |
未来工作/不足 |
是否有源码 |
|||
| 问题 |
原因 |
解决思路 |
优势 |
||||||
| 基于词语关系的词向量模型 文章编号:1003-0077(2017)03-0025-07 |
1.目前的自然语言处理中对于词向量的训练模型大多基于浅层的文本信息,没有充分挖掘深层的依存关系。 2.one-hot coding等表达方式不能有效传递词语所蕴含的语义信息,而且当采用余弦夹角、内积或者欧式距离来衡量两两词语之间的相似度时,会导致灾难性后果。 |
1.词的词义体现在该词与其他词产生的关系中,而词语关系包含关联单位、关系类型和关系方向三个属性。 |
1.提出了一种新的基于神经网络的词向量训练模型,具有三个顶层,分别对应关系的三个属性,更合理地利用词语关系对词向量进行训练,借助大规模未标记文本,利用依存关系和上下文关系来训练词向量。 |
1.通过这种方式训练得到的模型能够更准确地表达词语的语义信息。 2.关系模型在语义表达上更具优势,得益于关系模型能够充分挖掘依存关系和上下文关系。 |
1.机器学习方法已经广泛运用于文本挖掘任务,但因为传统的机器学习算法的输入往往是实值类型的向量或矩阵,所以我们需要将字符串或者符号形式的输入转换为实值类型的向量或矩阵。 2.Bengio借助语言模型的思想,使用句子中第t-n+1到第t-1个词作为回归神经网络的输入,第t个词作为回归神经网络的输出,利用语言模型的思想和回归神经网络方向传播算法,对词向量进行学习。 3.Mikolov等发布的word2vec工具提供了skip-gram和continues bag-of-word(CBOW)两种词向量训练模型,利用当前词周围的词来预测当前词。 |
1.文章认为词语语义的本质在于关系,而其由三元组:(1)关联单位,即某关系关联了哪两个词;(2)关系模型,即某关系为何种关系;(3)关系方向,即哪个词是关系的施加方,哪个词是关系的承受方。而不同关系对词向量训练具有不同程度的影响力,所以引入权重来表示该关系的重要程度。 2.为了加快训练速度以适应大规模训练的要求,框架只保留了输入层和顶层:输入层为目标词的词向量,其初始值为随机初始化的维度固定的向量;顶层分为三个部分,分别对应关系类型、关系方向和关联单位。关系类型和关系方向部分使用softmax训练,关联单位部分使用hierarchical softmax训练以应对大规模文本中的大量词汇。 |
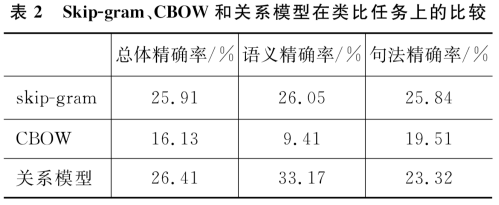
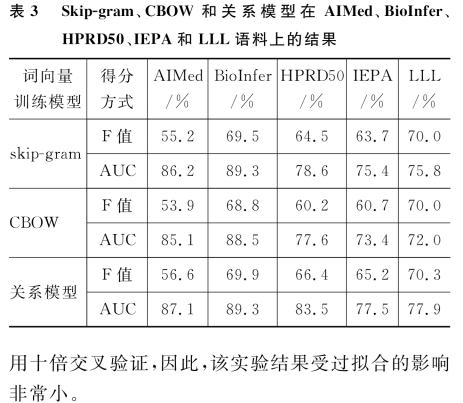
1.类比任务:用词向量的余弦相似度来衡量词之间的类比,共14类,其中五类为语义类比。实验中,以word2vec工具提供的text8预料为训练集,以Mikolov整理的19544个类比关系为测试集,以精确率的方式衡量词向量质量。结果在语义若任务上关系模型具有明显优势(33.17%),比skip-gram高7.12%;在句法任务上,关系模型达到了23.32%,比skip-gram模型低2.52%。总体考虑,关系模型具有最高的精确率26.41%。由此可知关系模型在语义表达方面更具优势,其源于关系模型能充分挖掘依存关系和上下文关系。 2.蛋白质关系抽取任务:目标是从生物医学文本中挖掘出具有交互作用的蛋白质对,可以看作是一个二元分类问题。如“The binding of hTAFII28 and hTAFII30 requires distinct domains of hTAFII18”,算法需要自动识别出hTAFII28与hTAFII30是具有交互关系的蛋白质对。实验中以5.8GB的生物医学文献为训练集,以目前该任务上的五个公共的评测数据集:AIMed、BioInfer、HPRD50、IEPA和LLL为测试集,采用十倍交叉验证计算F值和AUC值的方式衡量词向量的质量。结果当使用相同的初始化权重、学习率等时,关系模型在五个语料上均优于skip-gram模型,在AIMed、BioInfer、HPRD50、IEPA和LLL上的F值比skip-gram分别高出1.4%,0.4%,1.9%,1.5%和0.3%,而AUC值分别高出0.9%,0.0%,4.9%,2.1%,2.1%。 |
1.将引入外部语义资源,如WordNet本体等,进一步提高词向量的语义表达能力。 |
无 |