本文章主要是实现一个最基础的网络爬虫框架,采用广度优先策略,即先爬取当级的所有网页,再对下级网页进行爬取。这样的文章可以说是一找一大堆,但我还是写了一遍,别人写的代码,那是别人的东西,如果不亲自实践,那你是永远都无法掌握,发出来也是想给初学者一个参考。还有救是每次写超过50行的代码我都会做流程图,虽然很不标准,但还是可以有一个基本思路。有流程图说明代码中有自己的思考,还是那句话,写程序,百分之80的时间用于思考,百分之20的时间用于写代码,你越是学你就越能体会到这句话的重要性。闲话到此为止,我直接放流程图和代码,多的也不赘述,学能力是程序员最大的能力,自己研究吧
基本流程
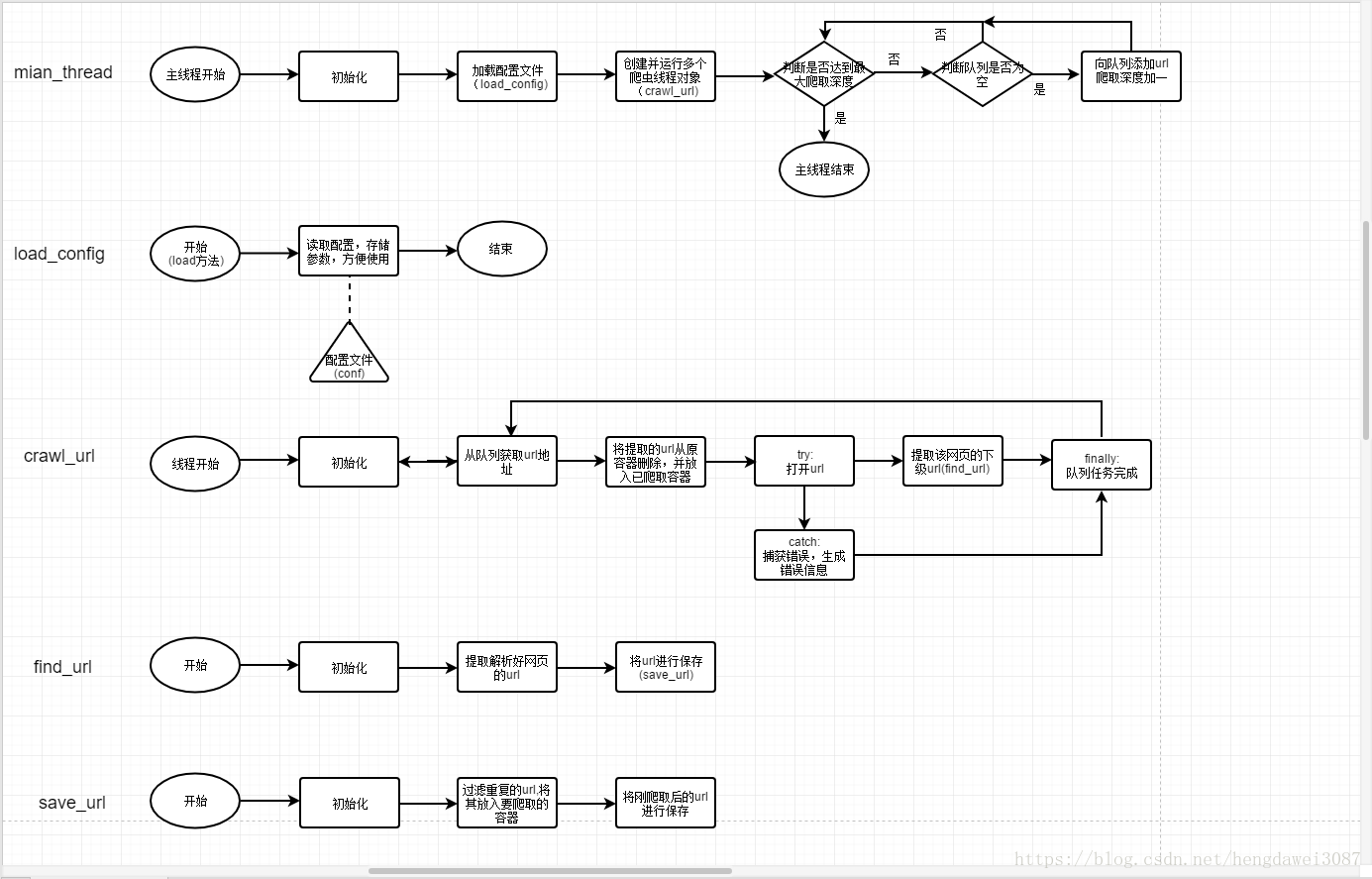
运行主线程,进行初始化(实例化load_config类,读取配置文件,依次实例化其他对象)
开启多条爬虫线程,爬虫线程会从queue取出url,爬取url
将爬取并解析好的web传入find_url,进行下级url的查找
save_url将爬取的url进行保存
当queue空后,且装有待爬取url的容器不为空,则深度加1,并对下一级网页进行爬取
代码
main_thread.py
import queue
import crawl_url
import find_url
import save_url
import load_config
def main():
#初始化对象
Load_Config=load_config.LoadConfig()
#加载配置文件
Load_Config.load()
Save_Url=save_url.SaveUrl(Load_Config.output_file)
Find_Url=find_url.FindUrl()
url_queue=queue.Queue()
#放置现在需要爬取的网页
target_url=[]
target_url.append(Load_Config.target_url)
#放置已经爬取的网页
loaded_url=[]
#加载并运行多个爬虫线程
for i in range(Load_Config.thread_count):
Crawl_Url=crawl_url.CrawlUrl(url_queue,Save_Url,Find_Url,Load_Config,target_url,loaded_url)
#主线程结束时,子线程立即结束
Crawl_Url.setDaemon(True)
#爬虫线程开始
Crawl_Url.start()
#开始向队列添加url
#当前爬取深度
cur_depth=0
#判断是否达到最大爬取深度
while cur_depth<Load_Config.max_depth:
#判断队列是否为空,为空向队列添加url
if url_queue.empty() and len(target_url)!=0:
for each in target_url:
url_queue.put(each)
#删除已经至queue的url
target_url.remove(each)
cur_depth+=1
url_queue.join()
print('爬虫结束。。。。。。')
if __name__ =='__main__':
main()crawl_url.py
from bs4 import BeautifulSoup
import urllib.request
import urllib.error
import logging
import main_thread
import threading
#import find_url
#import save_url
logging.basicConfig(filename='log.txt',level=logging.NOTSET)
class CrawlUrl(threading.Thread):
def __init__(self,queue,Save_Url,Find_Url,Load_Config,target_url,loaded_url):
threading.Thread.__init__(self)
self.queue=queue
self.Save_Url=Save_Url
self.Find_Url=Find_Url
#爬虫线程延迟
self.Load_Config=Load_Config
self.target_url=target_url
self.loaded_url=loaded_url
def run(self):
while True:
#从queue中取出url
url=self.queue.get()
#将此已经取出的url放入loaded_url容器
self.loaded_url.append(url)
print(url)
try:
#打开url
respond=urllib.request.urlopen(url,data=None,timeout=self.Load_Config.thread_timeout)
#用beatuiful对网页编码进行解析
respond=BeautifulSoup(respond.read(),'html.parser')
#提取该网页的下级url
href_list=self.Find_Url.find(respond)
self.target_url.extend(href_list)
#筛选重复的url
self.target_url=set(self.target_url)
self.target_url=list(self.target_url)
self.Save_Url.save(href_list)
except urllib.error.HTTPError as e:
logging.debug("HTTPError: %s" % e.code)
except urllib.error.URLError as e:
logging.debug("URLError:%s" % e.reason)
except Exception as e:
logging.debug("Exception:%s" % e)
finally:
self.queue.task_done()load_url.py
from configparser import ConfigParser
class LoadConfig():
def __init__(self):
#放置现在需要爬取的网页
self.target_url=''
#urls存储路径
self.output_file=[]
#最大爬取深度
self.max_depth=0
#爬虫线程延迟
self.thread_interval=0
#爬虫线程超时时间
self.thread_timeout=0
#爬虫线程数
self.thread_count=0
def load(self,filename='config.conf'):
#创建ConffigParser对象
conf=ConfigParser()
#读取配置文件
conf.read(filename,encoding='utf-8')
#加载配置
self.target_url=conf.get('configuration','url')
self.output_file=conf.get('configuration','output_file')
self.max_depth=int(conf.get('configuration','max_depth'))
self.thread_interval=int(conf.get('configuration','thread_interval'))
self.thread_timeout=float(conf.get('configuration','thread_timeout'))
self.thread_count=int(conf.get('configuration','thread_count'))
print(".....................................")
print("target_url:",self.target_url)
print("output_file:",self.output_file)
print("max_depth:",self.max_depth)
print("thread_interval:",self.thread_interval)
print("thread_timeout:",self.thread_timeout)
print("thread_count:",self.thread_count)
if __name__=="__main__":
config=LoadConfig()
config.load()find_url.py
import re
from bs4 import BeautifulSoup
import urllib.request
class FindUrl():
def __init__(self):
#创建筛选href的正则表达式
self.pat=re.compile('href=\"([^"]*)\"')
def find(self,respond):
#创建用来存url的list
href_list=[]
#寻找所以a标签
tag_a=respond.findAll('a')
for each in tag_a:
#从a标签中筛选href
href=self.pat.search(str(each))
#判断是否匹配到href
if href is None:
continue
href=href.group(1)
#将herf添加至list
href_list.append(href)
#返回url列表
return set(href_list)
if __name__ =='__main__':
url = urllib.request.urlopen(r'http://www.supreme007.com/', data=None,timeout=10)
response = BeautifulSoup(url.read(), "html.parser")
find_url=FindUrl()
urls=[]
urls=find_url.find(response)
urls=set(urls)
for each in urls:
print(each)save_url.py
import logging
import time
logging.basicConfig(filename='log.txt',level=logging.NOTSET)
class SaveUrl():
def __init__(self,output_file):
self.output_file=output_file
#记录已经保存的urls
self.urls_saved=[]
def save(self,loaded_url):
#去除已经保存过的url
for each in self.urls_saved:
loaded_url.remove(each)
#保存urls
try:
file=open(self.output_file,mode='a',encoding='utf-8')
for url in loaded_url:
file.write(url+'\n')
self.urls_saved.append(url)
file.close()
except IOError as error:
logging.debug('IOError: '+error)
if __name__=='__main__':
urls=['www.baidu.com','www.google.com','www.yahoo.com','www.google.com']
saveurl=SaveUrl('C:/Users/Administrator/Desktop/1.txt')
saveurl.save(urls)config.conf
[configuration]
url:http://www.supreme007.com/
output_file:./output/urls.txt
max_depth:2
thread_interval:1
thread_timeout:10
thread_count:5
运行结果