beautifsoup----爬虫数据挖掘又一大利器
– 安装:
conda install beautifulsoup4 或者 pip install beautifulsoup4(这个4代表着bs的版本)
这里我用了conda安装:

– beautiful soup:
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库.
官方文档:Beautifulsoup官方文档(里面讲的很详细)
–案例:
-
工具:urllib bs
-
思考:
1. 用urllib.request.Request请求网页,使用headers设置用户代理或者使用proxy代理服务器隐 藏身份,因为直接请求,返回403。
2. 通过查看源代码发现,用户名在auth类下的a标签里,而用户回复内容在postbody类里
4. 炖一锅汤,使用css选择器 select方法下的get_text()方法找到我们想要的数据
5. for循环并按想要的格式输出数据 -
代码:

输出结果:

疑问:如何获取所有跟贴战友的name和content?
但是通过结果我们发现,最终结果只有四个战友的名字和其回复内容,但是我们发现登录丁香园账号后这个帖子有很多跟贴。
解决办法:
使用cookie,模拟用户登录

输出结果:

**特别提醒:**这里range函数里如果是len(name),结果会多一行“没找到”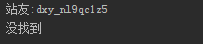
原因就是我们用cookie模拟登录,那么最后一个战友的name是自己。
总结:
bs是出了xml bs4等外的非常重要的一种数据提取库
他们的优缺点:
- 正则: 很快,不好用,不许安装
- beautifulsoup:慢,使用简单,安装简单
- lxml: 比较快,使用简单,安装一般
bs的四大对象:
- Tag
- NavigableString
- BeautifulSoup
- Comment
遍历文档树的方法
-
find_all和find
-
css选择器(select)