1. HashMap
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
* 初始化负载因子为0.75
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
主要存放数据的数据结构
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
Node类
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
hash方法
// >>> 无符号右移
// ^ 位异或
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
putValue方法
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 放入第一个元素时table为空,出发resize方法
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/**
*i = (n - 1) & hash;//hash是传过来的,其中n是底层数组的长度,用&运算符计算出i的值
*p = tab[i];//用计算出来的i的值作为下标从数组中元素
if(p == null){//如果这个元素为null,用key,value构造一个Node对象放入数组下标为i的位置
tab[i] = newNode(hash, key, value, null);
}
**/
/**
* 1. 从底层数组中取值
**/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
/**
* 2.
* 如果底层元素匹配成功,赋值给e
* hash 值相等 key的地址相等,且key不为空,且key的内容也要相等
**/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
/**
* 3. 如果是TreeNode,直接放到树中
**/
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
/**
* 加到node数组中了
**/
else {
/**
* 冲突解决的for循环
**/
//便利node数组中的某一位对应的单链表
for (int binCount = 0; ; ++binCount) {
//如果单链表遍历到最后也没有找到元素,说明不存在,直接添加到最后
if ((e = p.next) == null) {
//解决冲突的关键,连地址法,直接挂在已经占据位置的node的后面
p.next = newNode(hash, key, value, null);
/**
* static final int TREEIFY_THRESHOLD = 8;
**/
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//把链表转化为红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
////如果hash值相等,key也相等或者equals相等,赋值给e
p = e;
}
}
/**
* 5. 用新的value替换旧的value,并返回旧的value
**/
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
putTreeVal方法
/**
* Tree version of putVal.
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
//遍历树的节点
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
//如果put的key的地址相等或者不为空的时候的内容也相等,直接返回树中该节点
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
//遍历完树中节点之后还是没有找到key的话,在树中添加新的节点
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
resize()方法
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
新的capability就是16
newCap = DEFAULT_INITIAL_CAPACITY;
创建大小为16的node数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
返回新创建table
return newTab;
做一个总结,在hashMap中放入(put)元素,有以下重要步骤:
1、计算key的hash值,算出元素在底层数组中的下标位置。
2、通过下标位置定位到底层数组里的元素(也有可能是链表也有可能是树)。
3、取到元素,判断放入元素的key是否==或equals当前位置的key,成立则替换value值,返回旧值。

4、如果是树,循环树中的节点,判断放入元素的key是否==或equals节点的key,成立则替换树里的value,并返回旧值,不成立就添加到树里。
5、否则就顺着元素的链表结构循环节点,判断放入元素的key是否==或equals节点的key,成立则替换链表里value,并返回旧值,找不到就添加到链表的最后。
精简一下,判断放入HashMap中的元素要不要替换当前节点的元素,key满足以下两个条件即可替换:
1、hash值相等。
2、==或equals的结果为true。
2. HashMap HashTable ConcurrentHashMap的比较
1. 线程安全角度
HashMap是线程不安全的,Hashtable和ConcurrentHashMap是线程安全的。
Hash Table 统一加了锁。 "synchronized"关键字的意思就是加锁了,不管是put,get还是什么的,统一加上了锁。
public synchronized V get(Object key)
public synchronized V put(K key, V value)
关键字在方法上,还不是静态方法,那锁的就是this,也就是当前对象。
Hash Table效率偏低:这里不管读写都加锁,而且锁的对象都一样,是整个对象。出现锁竞争与等待的可能很大。
2. ConcurrentHashMap的线程安全处理
public V get(Object key) {
//
Node<K,V>[] tab;
Node<K,V> e, p;
int n, eh; K ek;
//spread相当于HashMap中的hash方法,处理一下hash值,使其分布不容易碰撞
int h = spread(key.hashCode());
//table是当前对象中用于保存所有元素的数组,必须不能为空,而且长度大于0
//tabAt的意思就是从table中找到hash为h的这个元素,如果没找到,说明不含有key为此值的元素
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//如果hash值相同,说明几乎就是
if ((eh = e.hash) == h) {
//再判断一下key是不是相同啊,是不是equals啊什么的,就准备返回了
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//这里跟下面的一样,都是遍历链表
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//既然在当前位置,第一个元素还不是,那就遍历这条链表,找到对应的
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
unsafe.compareAndSwap();
比如说现在内存中有a=1;
线程T1拿到a=1,然后准备修改a,这个时候就调用unsafe.compareAndSwap()去修改。
访问内存的时候:如果发现内存中的a还是T1认为的那样(为1),则修改,并且返回true.
如果内存中的a已经被其他线程修改了(跟手上的a的值对不上,不为1),则不修改,返回false;
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
//1.for
for (Node<K,V>[] tab = table;;) {
Node<K,V> f;
int n, i, fh;
//table还是空的情况,初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//找到元素的位置是空的,直接放进去,下面的注释也说到了,不用锁。
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//跳过
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
//到了这里,应该是找到了新的元素应该存放的位置,而且这个位置上还有其他的元素
V oldVal = null;
//此处加锁,锁的是f,f是什么?是找到的位于数组上的该位置上的第一个元素
synchronized (f) {
//之前f=tabat(tab,i),这里看来应该是必须成立的,直接下一步
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
//然后就是寻找,替换。
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//替换了后,binCount是有所增加了,所以进入,并且在if的最后跳出循环。
if (binCount != 0) {
//就是查看下链表够不够长,需要换成红黑树不
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
3. 小结
如果是单线程情况,就用HashMap。多线程,还是用ConcurrentHashMap比较好。
3.String StringBuilder StringBuffer比较
3.1 不可变性
String 是不可变的,StringBuffer、StringBuilder是可变的
3.2 线程安全角度
String 、StringBuffer是线程安全的,StringBuilder是线程不安全的 (StringBuffer的append操作用了synchronized)
3.3 效率
String对象串联的效率最慢,单线程下字符串的串联用StringBuilder,多线程下字符串的串联用StringBuffer
4. 深浅拷贝
如果在拷贝这个对象的时候,只对基本数据类型进行了拷贝,而对引用数据类型只是进行了引用的传递,而没有真实的创建一个新的对象,则认为是浅拷贝。反之,在对引用数据类型进行拷贝的时候,创建了一个新的对象,并且复制其内的成员变量,则认为是深拷贝。
5. wait和sleep方法
1. 释放的资源不一样
sleep方法只让出了CPU,而并不会释放同步资源锁!!!
wait()方法则是指当前线程让自己暂时退让出同步资源锁,
2. 唤醒方法不一样
sleep:时间片到了
wait:外部调用notify方法
注意:notify的作用相当于叫醒睡着的人,而并不会给他分配任务,就是说notify只是让之前调用wait的线程有权利重新参与线程的调度);
3. 作用域不一样
sleep:任何地方
wait()方法则只能在同步方法或同步块中使用;
4. 亲爸爸不一样
sleep()是线程线程类(Thread)的方法,调用会暂停此线程指定的时间,但监控依然保持,不会释放对象锁,到时间自动恢复;
wait()是Object的方法,调用会放弃对象锁,进入等待队列,待调用notify()/notifyAll()唤醒指定的线程或者所有线程,才会进入锁池,不再次获得对象锁才会进入运行状态;
6.servlet是否线程安全,如何改造
我们写的代码本身就是多线程的,每一个请求有servletRequest对象来接受请求,由servletResponse对象来响应该请求,
同一个servlet的多个请求到来时,可能发生多线程同时访问同一资源的情况,数据可能变得不一致,
解决方法:
1、同步对共享数据的操作
使用synchronized 关键字能保证一次只有一个线程可以访问被保护的区段,
Servlet可以通过同步块操作来保证线程的安全。
2、避免使用实例变量(成员变量)
使用实例变量会造成线程安全问题,只是这个问题在高并发的情况下更容易体现出来,
其他时候这个问题依然存在,只是不一定体现,多线程并不共享局部变量,所以我们要尽可能的在servlet中使用局部变量,
所以只要在Servlet里面的任何方法里面都不使用实例变量,那么该Servlet就是线程安全的。
7.session和cookie的区别
1,session 在服务器端,cookie 在客户端(浏览器)
2,session 默认被存在在服务器的一个文件里(不是内存)
3,session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效(但是可以通过其它方式实现,比如在 url 中传递 session_id)
4,session 可以放在 文件、数据库、或内存中都可以。
5,用户验证这种场合一般会用 session 因此,维持一个会话的核心就是客户端的唯一标识,即 session id
8.get和post的区别
1. 可看到的
GET后退按钮/刷新无害,POST数据会被重新提交(浏览器应该告知用户数据会被重新提交)。
GET书签可收藏,POST为书签不可收藏。
GET能被缓存,POST不能缓存 。
GET编码类型application/x-www-form-url,POST编码类型encodedapplication/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。
GET历史参数保留在浏览器历史中。POST参数不会保存在浏览器历史中。
GET对数据长度有限制,当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。POST无限制。
GET只允许 ASCII 字符。POST没有限制。也允许二进制数据。与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。在发送密码或其他敏感信息时绝不要使用 GET !POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。
GET的数据在 URL 中对所有人都是可见的。POST的数据不会显示在 URL 中。
9. Tcp三次握手和四次分手
9.1 三次握手
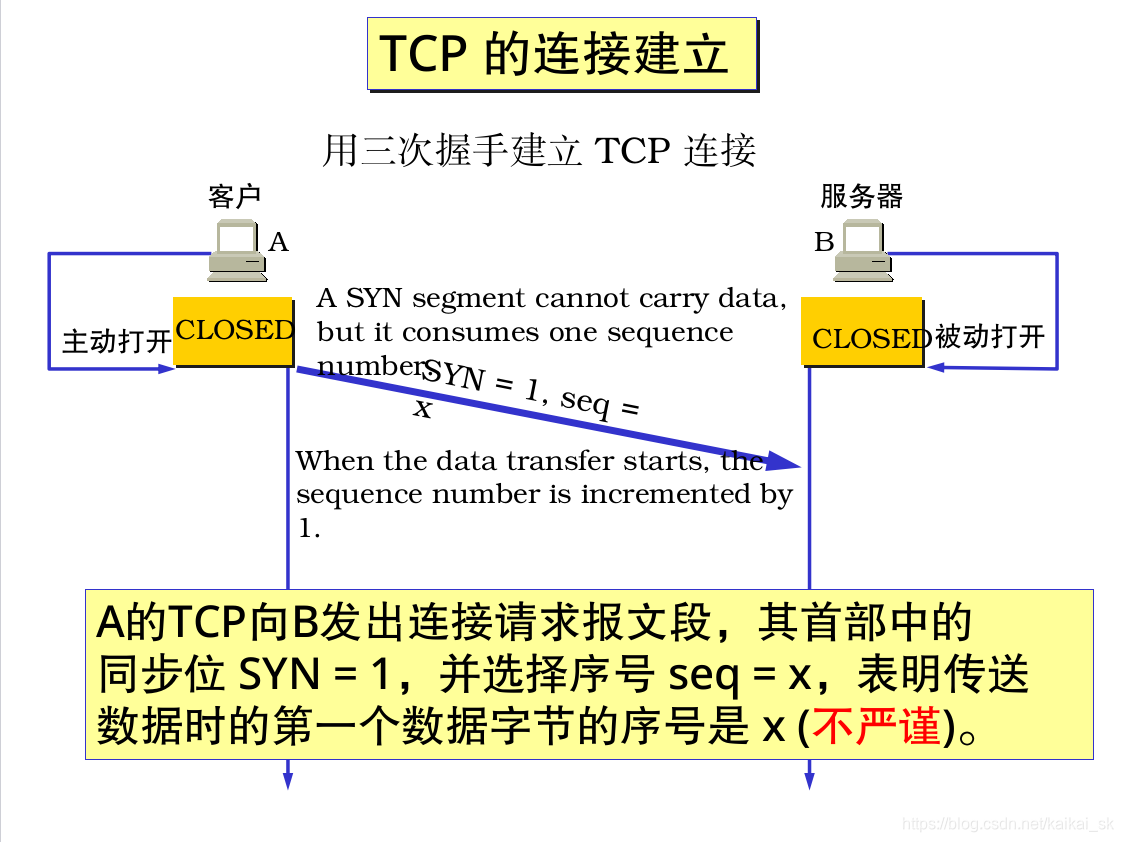
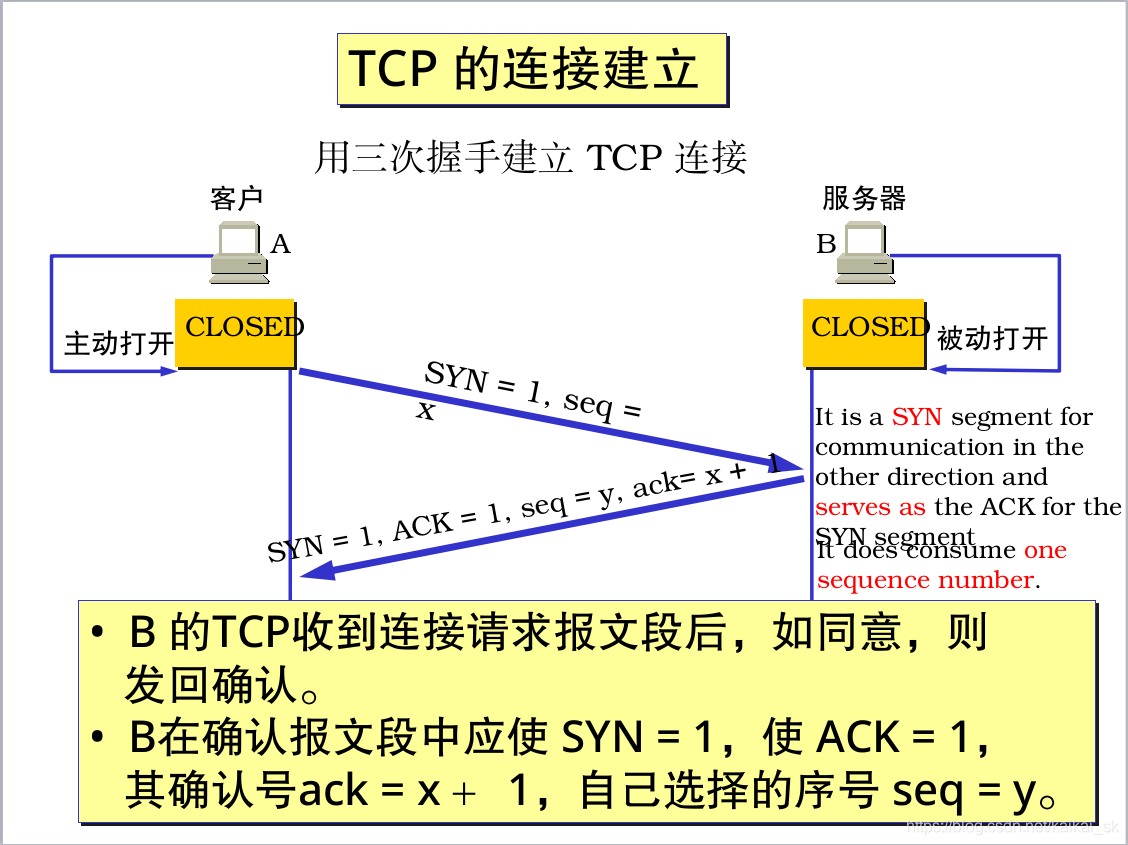
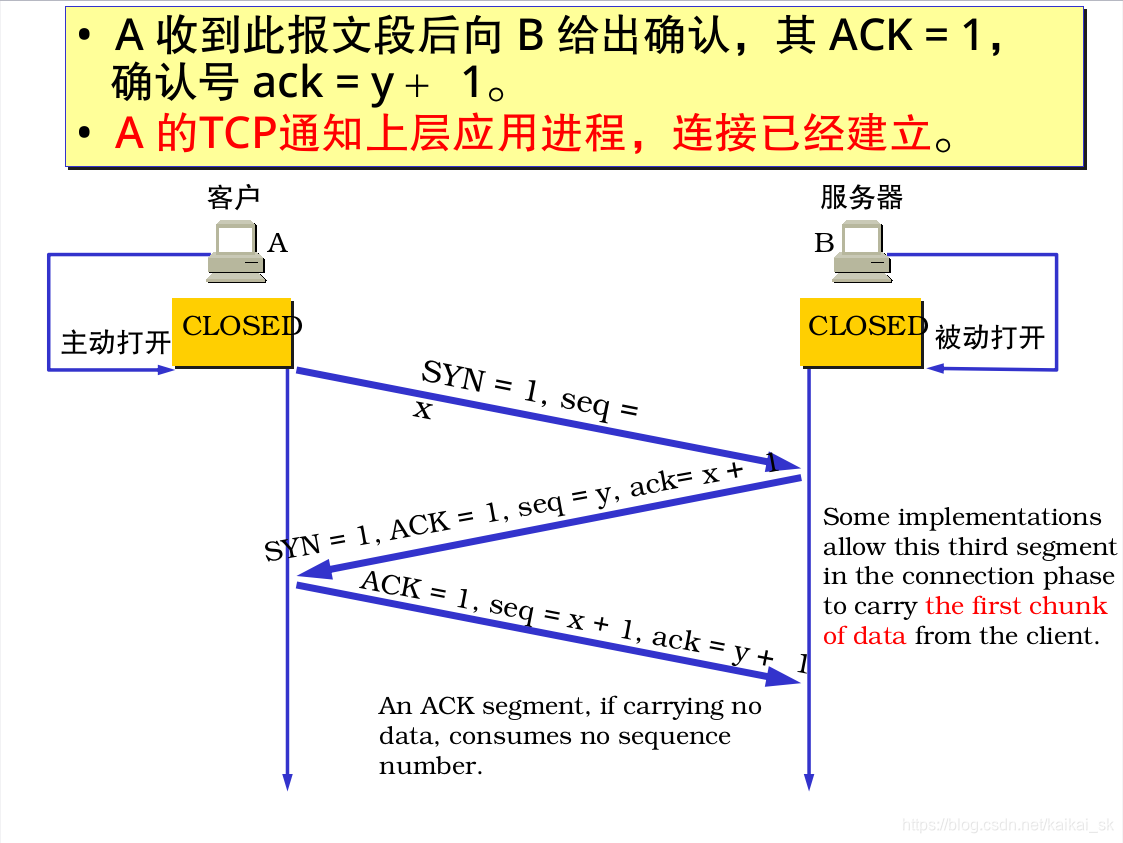
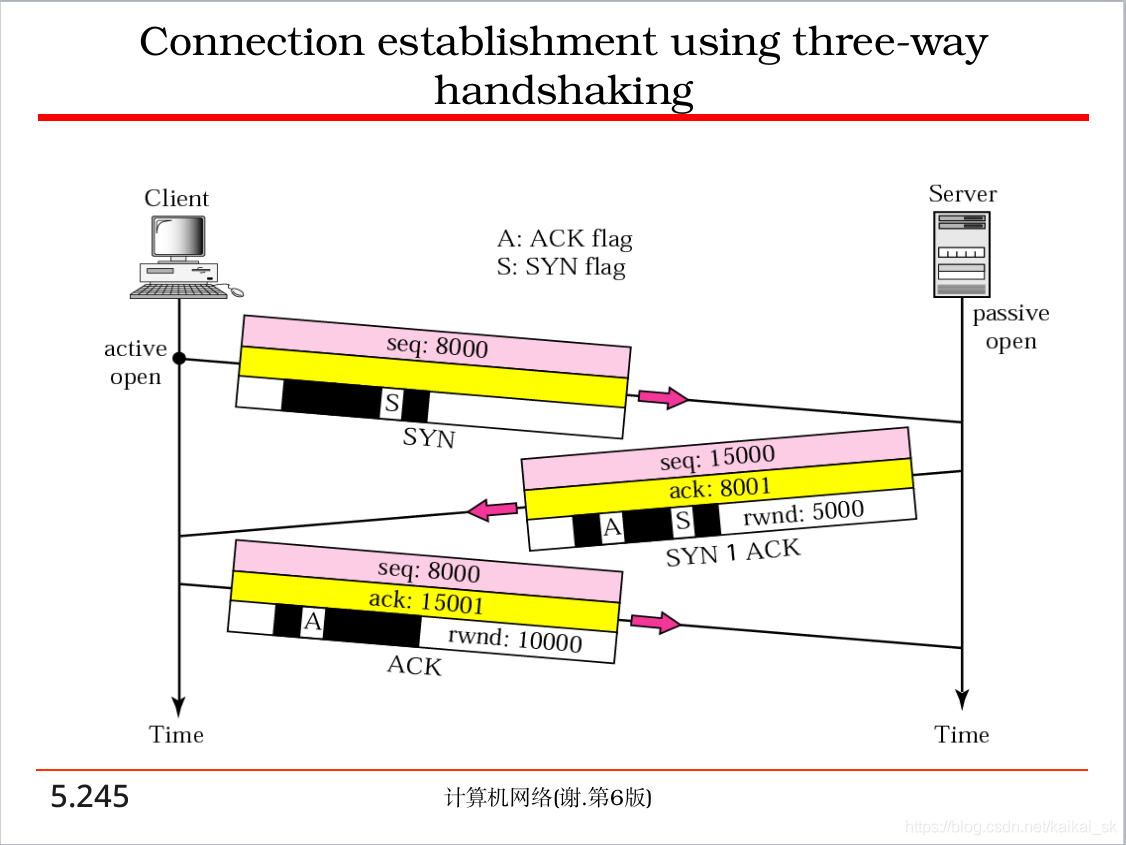
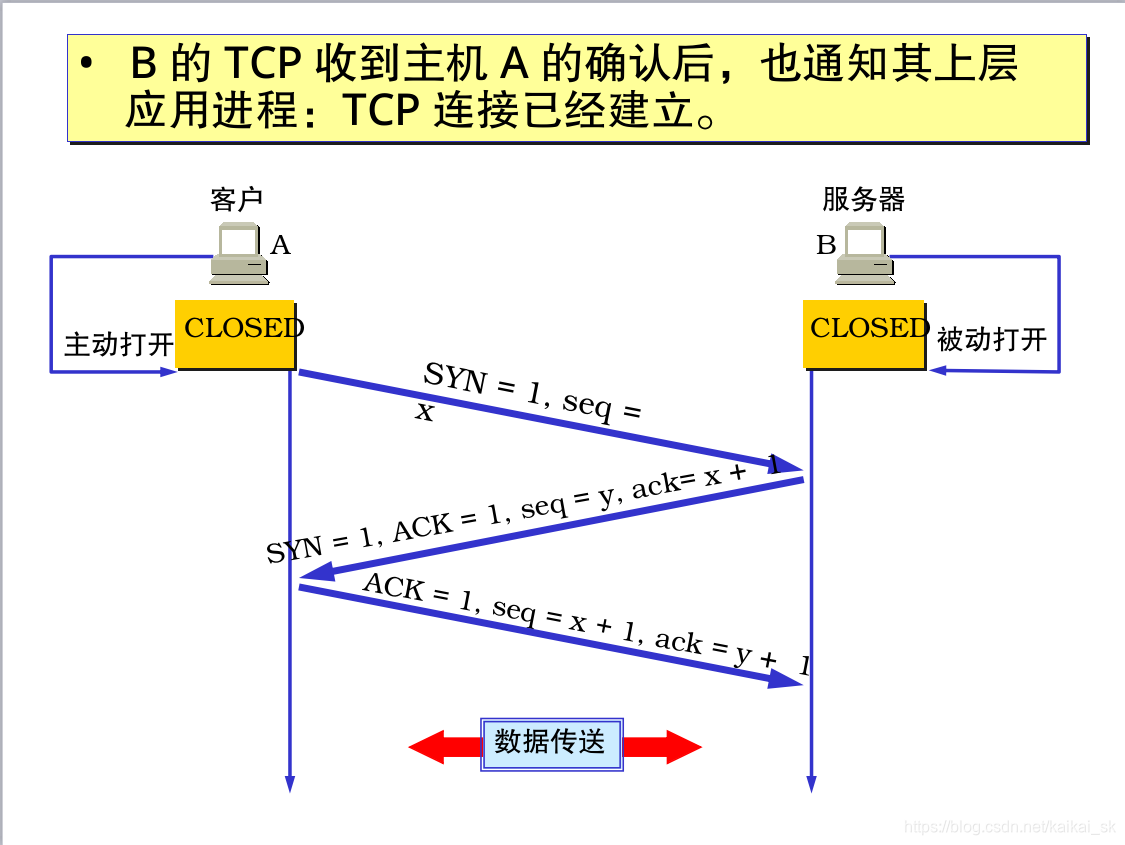
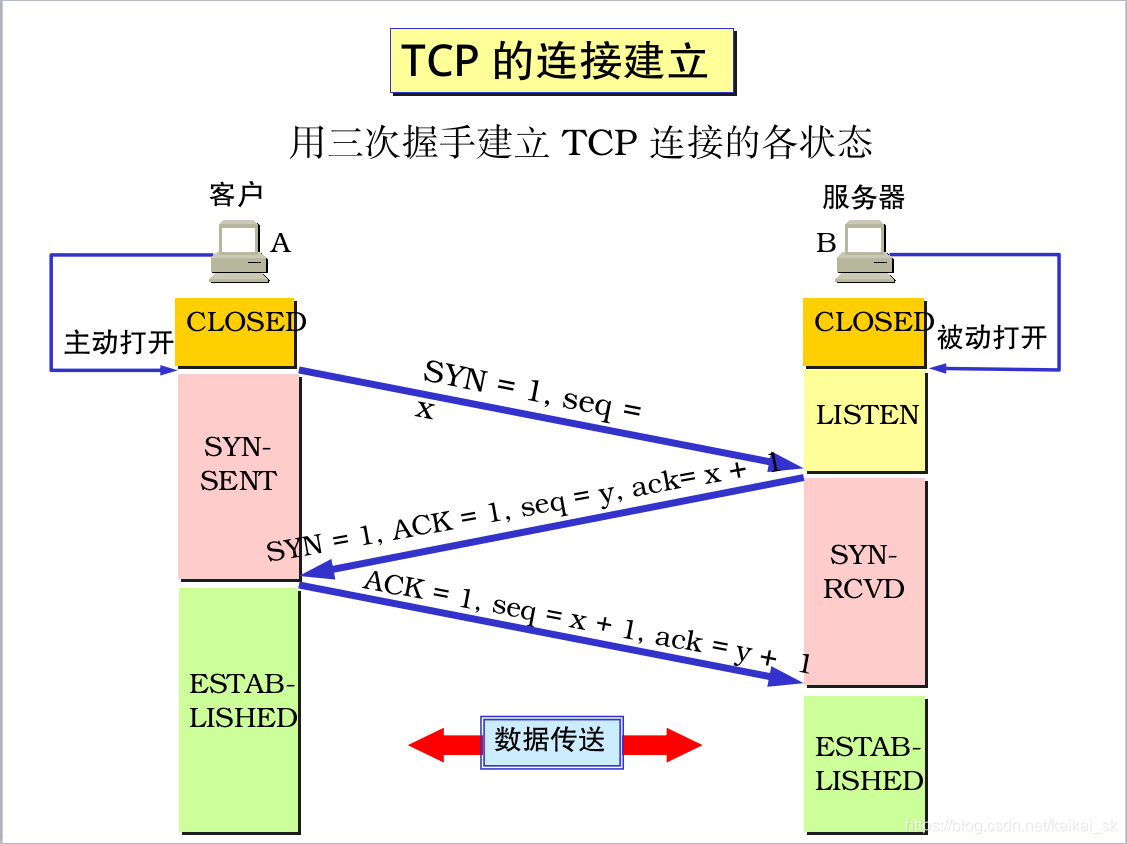
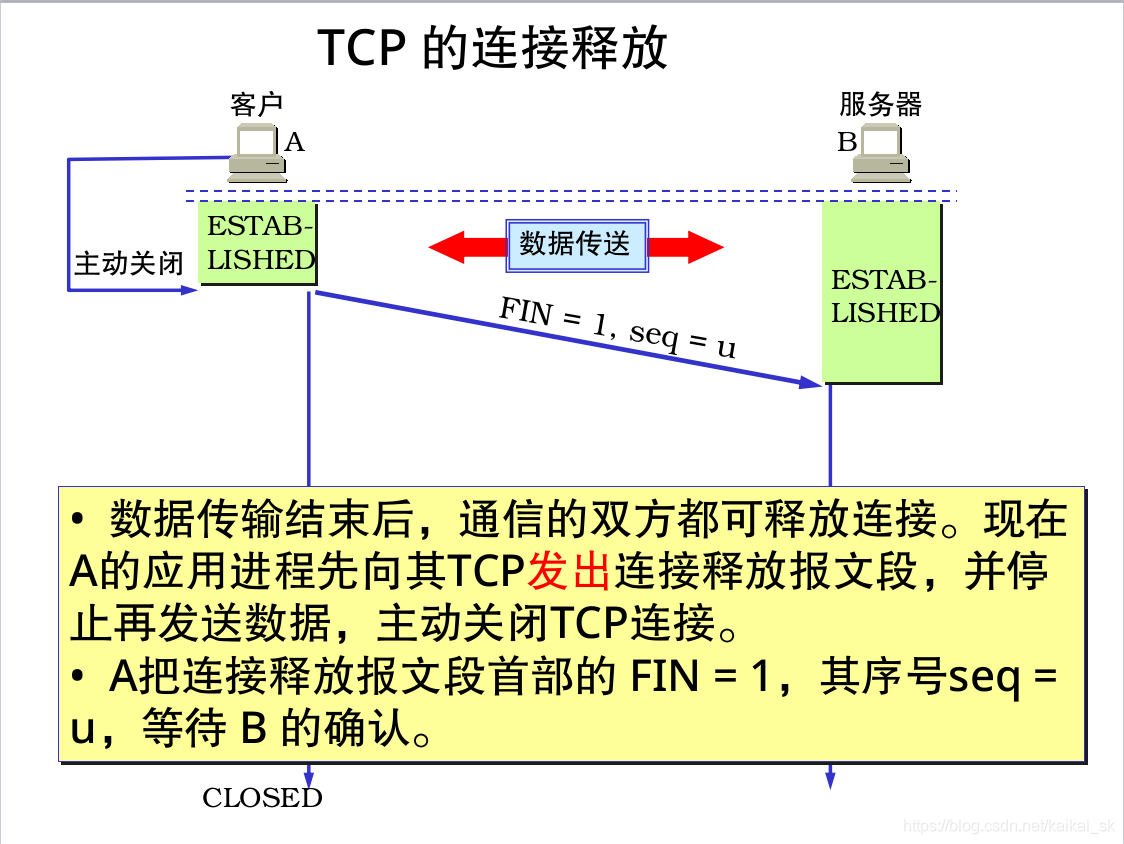
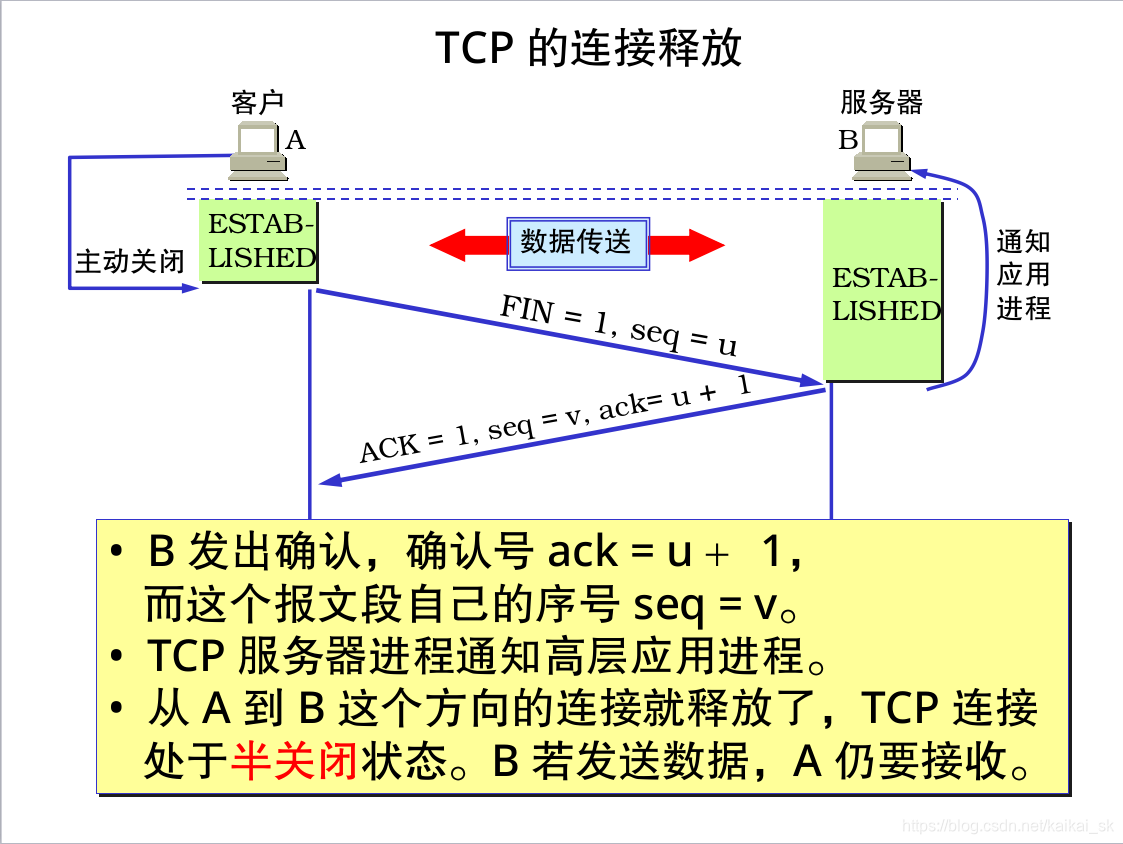
9.2四次分手
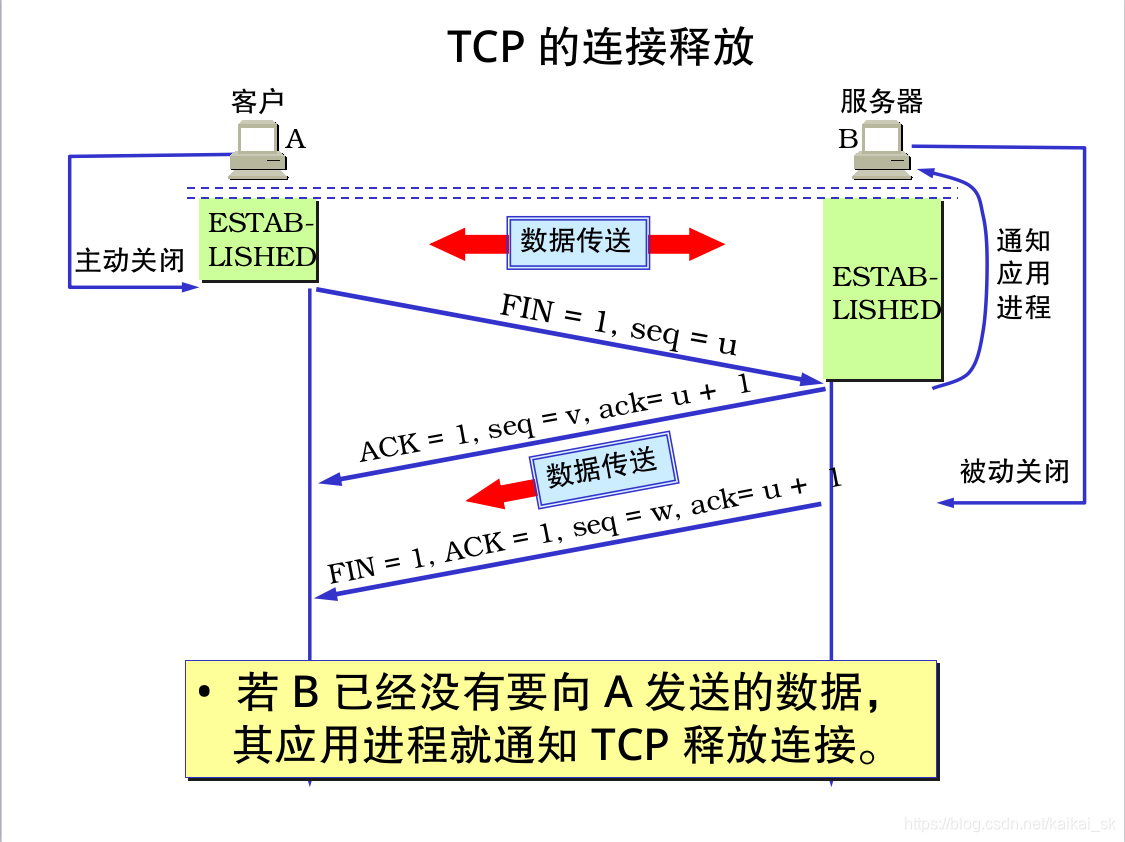

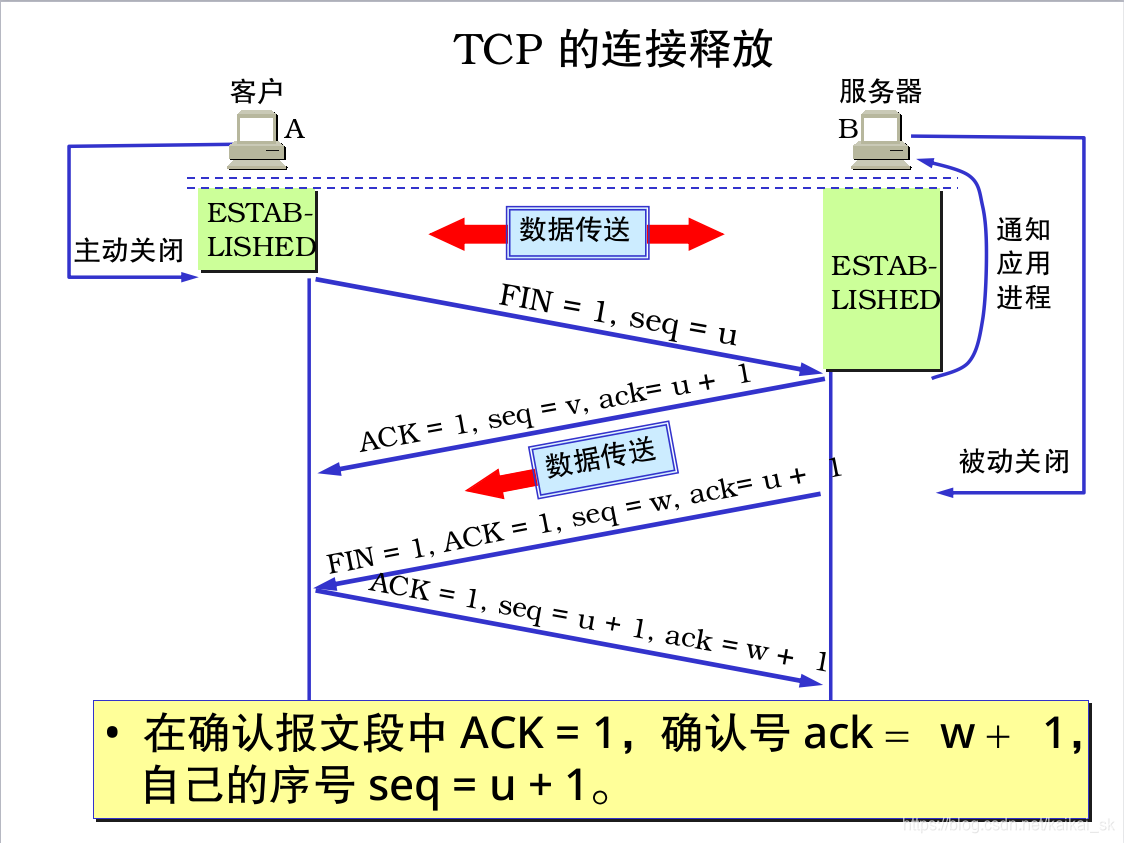
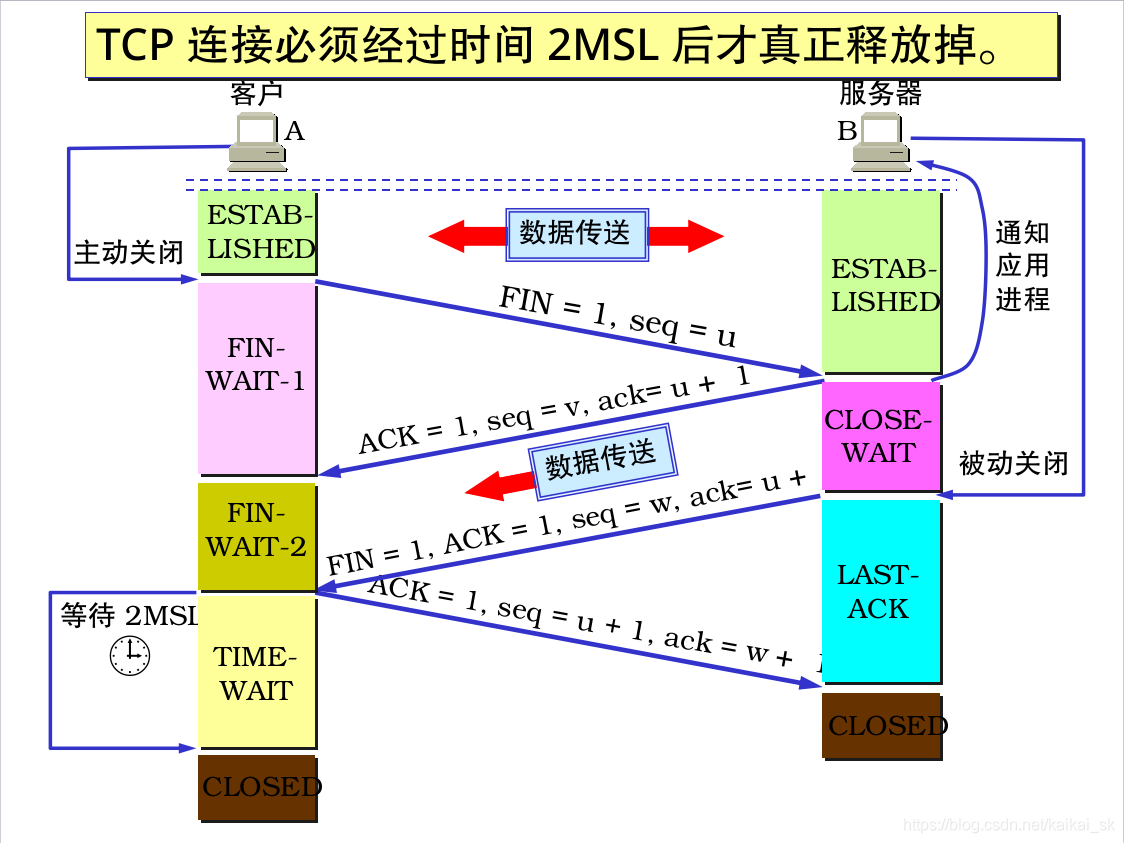
10 .countLatch的await方法是否安全
脑壳疼
https://zhuanlan.zhihu.com/p/38850439
11. ThreadLocal原理,注意事项,参数传递
/**
* 每个 Thread 里都含有一个 ThreadLocalMap 的成员变量,这种机制将 ThreadLocal 和线程巧妙地绑定在了一起,
* 既可以保证无用的 ThreadLocal 被及时回收,不会造成内存泄露,又可以提升性能。
* 假如我们把 ThreadLocalMap 做成一个 Map<t extends Thread, ?> 类型的 Map,那么它存储的东西将会非常多(相当于一张全局线程本地变量表),
* 这样的情况下用线性探测法解决哈希冲突的问题效率会非常差。
* 而 JDK 里的这种利用 ThreadLocal 作为 key,再将 ThreadLocalMap 与线程相绑定的实现,完美地解决了这个问题。
* 总结一下什么时候无用的 Entry 会被清理:
* 1. Thread 结束的时候
* 2. 插入元素时,发现 staled entry,则会进行替换并清理
* 3. 插入元素时,ThreadLocalMap 的 size 达到 threshold,并且没有任何 staled entries 的时候,会调用 rehash 方法清理并扩容
* 4. 调用 ThreadLocalMap 的 remove 方法或set(null) 时
* 尽管不会造成内存泄露,但是可以看到无用的 Entry 只会在以上四种情况下才会被清理,
* 这就可能导致一些 Entry 虽然无用但还占内存的情况。因此,我们在使用完 ThreadLocal 后一定要remove一下,保证及时回收掉无用的 Entry。
* 特别地,当应用线程池的时候,由于线程池的线程一般会复用,Thread 不结束,这时候用完更需要 remove 了。
* 总的来说,对于多线程资源共享的问题,同步机制采用了 以时间换空间 的方式,
*而 ThreadLocal 则采用了 以空间换时间 的方式。
*前者仅提供一份变量,让不同的线程排队访问;而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
**/
public class ThreadLocal<T>
{
//ThreadLocal对象的唯一标识
//threadLocalHashCode 通过 CAS 操作进行更新,每次 hash 操作的增量为 0x61c88647(这个数的原理没有探究)。
private final int threadLocalHashCode = nextHashCode();
public void set(T value)
{
//获取当前线程引用
Thread t = Thread.currentThread();
//获得ThreadLocalMap实例
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
/**
* Thread类中定义了ThreadLocalMap类型的成员变量
* 每个Thread里面都有一个ThreadLocal.ThreadLocalMap成员变量,
* 也就是说每个线程通过ThreadLocal.ThreadLocalMap与ThreadLocal相绑定,
* 这样可以确保每个线程访问到的thread-local variable都是本线程的。
**/
ThreadLocalMap getMap(Thread t)
{
return t.threadLocals;
}
void createMap(Thread t, T firstValue)
{
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
public T get()
{
//获取当前线程
Thread t = Thread.currentThread();
//获取ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null)
{
//this 就是ThreadLocal实例对象
// 然后通过ThreadLocal实例对象来查找其value值
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null)
{
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//如果不存在就初始化
return setInitialValue();
}
private T setInitialValue()
{
//value = null
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
//将value注入到map中
if (map != null)
map.set(this, value);
else
createMap(t, value);
//返回null
return value;
}
static class ThreadLocalMap
{
//Map的初始容量
private static final int INITIAL_CAPACITY = 16;
//存储数据的数据结构
private Entry[] table;
//逻辑长度
private int size = 0;
//要扩容时的size的阈值
private int threshold;
/**
* 计算hash值之后,从数组中取出
**/
private Entry getEntry(ThreadLocal<?> key)
{
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
/**
* Version of getEntry method for use when key is not found in
* its direct hash slot.
*
* 使用线性探测法继续查找
*
* @param key the thread local object
* @param i the table index for key's hash code
* @param e the entry at table[i]
* @return the entry associated with key, or null if no such
*/
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];e != null;
e = tab[i = nextIndex(i, len)])//从这里可以看出,ThreadLocalMap 解决冲突的方法是 线性探测法(不断加 1),
//而不是 HashMap 的 链地址法,
{
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null)
{
//如果entry里对应的key为null的话,表明此entry为staled entry,就将其替换为当前的key和value
replaceStaleEntry(key, value, i);
return;
}
}
/**若是经历了上面步骤没有命中hash,也没有发现无用的Entry,
*set方法就会创建一个新的Entry,并会进行启发式的垃圾清理,用于清理无用的Entry。
*主要通过cleanSomeSlots方法进行清理(清理的时机通常为添加新元素或另一个无用的元素被回收时。参见注释)
**/
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
/**
* 垃圾回收
**/
private boolean cleanSomeSlots(int i, int n)
{
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do
{
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null)
{
n = len;
removed = true;
//一旦发现一个位置对应的 Entry 所持有的 ThreadLocal 弱引用为null,
//就会把此位置当做 staleSlot 并调用 expungeStaleEntry 方法进行整理 (rehashing) 的操作
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
/**
* Construct a new map initially containing (firstKey, firstValue).
* ThreadLocalMaps are constructed lazily, so we only create
* one when we have at least one entry to put in it.
* @param firstKey 第一个参数就是本ThreadLocal实例(this),
* @param firstValue 第二个参数就是要保存的线程本地变量。
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue)
{
/**
*构造函数首先创建一个长度为16的Entry数组,
*然后计算出firstKey对应的哈希值,然后存储到table中,
* 并设置size和threshold。
**/
table = new Entry[INITIAL_CAPACITY];
// 相当于取模运算hashCode % size的一个更高效的实现
// 正是因为这种算法,我们要求size必须是 2的指数,因为这可以使得hash发生冲突的次数减小。
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
/**
* 每个Entry对象都有一个ThreadLocal的弱引用,这是为了防止内存泄漏。一旦线程结束,key变为一个不可达的对象,这个Entry就可以被GC了。
*/
static class Entry extends WeakReference<ThreadLocal<?>>
{
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
}
12. Java中的各种锁(内置锁,显示锁,各种容器锁,锁优化,锁消除,锁粗化,锁偏向,轻量级锁)
13. session的存储
14.防止表单重复提交
https://www.jianshu.com/p/01b6ab61f24a
15.JVM内存模型
16.各种java工具(jps,jinfo,jmap)
17.数据库索引及底层实现
18.索引失效的场景
19.最左原则
20.查看执行计划和Cardiation
21.数据库中的各种锁(悲观乐观锁,行级和表级锁)
22 . 隔离级别和实现
23 redo log undo log bin log 主从复制
24 mvcc Next-Key lock
25 CAP原理
26 缓存穿透怎么解决
27 redis的IO模型
28 如何保证redis的高可用
29 redis是单线程还是多线程
30 线上cpu占比过高怎么排查
31. Spring中的ioc 和Aop原理,ioc初始化流程
AnnotationConfigApplicationContext容器的构造函数
public AnnotationConfigApplicationContext(Class<?>... annotatedClasses) {
this();
register(annotatedClasses);
refresh();
}
重点关注Refresh方法
1、prepareRefresh()刷新前的预处理;
1)、initPropertySources()初始化一些属性设置;子类自定义个性化的属性设置方法;
2)、getEnvironment().validateRequiredProperties();检验属性的合法等
3)、earlyApplicationEvents= new LinkedHashSet();保存容器中的一些早期的事件;
2、obtainFreshBeanFactory();获取BeanFactory;
1)、refreshBeanFactory();刷新【创建】BeanFactory;
创建了一个this.beanFactory = new DefaultListableBeanFactory();
设置id;
2)、getBeanFactory();返回刚才GenericApplicationContext创建的BeanFactory对象;
3)、将创建的BeanFactory【DefaultListableBeanFactory】返回;
3、prepareBeanFactory(beanFactory);BeanFactory的预准备工作(BeanFactory进行一些设置);
1)、设置BeanFactory的类加载器、支持表达式解析器…
2)、添加部分BeanPostProcessor【ApplicationContextAwareProcessor】
3)、设置忽略的自动装配的接口EnvironmentAware、EmbeddedValueResolverAware、xxx;
4)、注册可以解析的自动装配;我们能直接在任何组件中自动注入:
BeanFactory、ResourceLoader、ApplicationEventPublisher、ApplicationContext
5)、添加BeanPostProcessor【ApplicationListenerDetector】
6)、添加编译时的AspectJ;
7)、给BeanFactory中注册一些能用的组件;
environment【ConfigurableEnvironment】、
systemProperties【Map<String, Object>】、
systemEnvironment【Map<String, Object>】
4、postProcessBeanFactory(beanFactory);BeanFactory准备工作完成后进行的后置处理工作;
1)、子类通过重写这个方法来在BeanFactory创建并预准备完成以后做进一步的设置
以上是BeanFactory的创建及预准备工作============
5、invokeBeanFactoryPostProcessors(beanFactory);执行BeanFactoryPostProcessor的方法;
BeanFactoryPostProcessor:BeanFactory的后置处理器。在BeanFactory标准初始化之后执行的;
两个接口:BeanFactoryPostProcessor、BeanDefinitionRegistryPostProcessor
1)、执行BeanDefinitionRegistryPostProcessor的方法;
先执行BeanDefinitionRegistryPostProcessor
1)、获取所有的BeanDefinitionRegistryPostProcessor;
2)、看先执行实现了PriorityOrdered优先级接口的BeanDefinitionRegistryPostProcessor、
postProcessor.postProcessBeanDefinitionRegistry(registry)
3)、在执行实现了Ordered顺序接口的BeanDefinitionRegistryPostProcessor;
postProcessor.postProcessBeanDefinitionRegistry(registry)
4)、最后执行没有实现任何优先级或者是顺序接口的BeanDefinitionRegistryPostProcessors;
postProcessor.postProcessBeanDefinitionRegistry(registry)
再执行BeanFactoryPostProcessor的方法
1)、获取所有的BeanFactoryPostProcessor
2)、看先执行实现了PriorityOrdered优先级接口的BeanFactoryPostProcessor、
postProcessor.postProcessBeanFactory()
3)、在执行实现了Ordered顺序接口的BeanFactoryPostProcessor;
postProcessor.postProcessBeanFactory()
4)、最后执行没有实现任何优先级或者是顺序接口的BeanFactoryPostProcessor;
postProcessor.postProcessBeanFactory()
6、registerBeanPostProcessors(beanFactory);注册BeanPostProcessor(Bean的后置处理器)【 intercept bean creation】
不同接口类型的BeanPostProcessor;在Bean创建前后的执行时机是不一样的
BeanPostProcessor、
DestructionAwareBeanPostProcessor、
InstantiationAwareBeanPostProcessor、
SmartInstantiationAwareBeanPostProcessor、
MergedBeanDefinitionPostProcessor【internalPostProcessors】、
1)、获取所有的 BeanPostProcessor;后置处理器都默认可以通过PriorityOrdered、Ordered接口来执行优先级
2)、先注册PriorityOrdered优先级接口的BeanPostProcessor;
把每一个BeanPostProcessor;添加到BeanFactory中
beanFactory.addBeanPostProcessor(postProcessor);
3)、再注册Ordered接口的
4)、最后注册没有实现任何优先级接口的
5)、最终注册MergedBeanDefinitionPostProcessor;
6)、注册一个ApplicationListenerDetector;来在Bean创建完成后检查是否是ApplicationListener,如果是
applicationContext.addApplicationListener((ApplicationListener<?>) bean);
7、initMessageSource();初始化MessageSource组件(做国际化功能;消息绑定,消息解析);
1)、获取BeanFactory
2)、看容器中是否有id为messageSource的,类型是MessageSource的组件
如果有赋值给messageSource,如果没有自己创建一个DelegatingMessageSource;
MessageSource:取出国际化配置文件中的某个key的值;能按照区域信息获取;
3)、把创建好的MessageSource注册在容器中,以后获取国际化配置文件的值的时候,可以自动注入MessageSource;
beanFactory.registerSingleton(MESSAGE_SOURCE_BEAN_NAME, this.messageSource);
MessageSource.getMessage(String code, Object[] args, String defaultMessage, Locale locale);
8、initApplicationEventMulticaster();初始化事件多播器;
1)、获取BeanFactory
2)、从BeanFactory中获取applicationEventMulticaster的ApplicationEventMulticaster;
3)、如果上一步没有配置;创建一个SimpleApplicationEventMulticaster
4)、将创建的ApplicationEventMulticaster添加到BeanFactory中,以后其他组件直接自动注入
9、onRefresh();留给子容器(子类)
1、子类重写这个方法,在容器刷新的时候可以自定义逻辑;
10、registerListeners();给容器中将所有项目里面的ApplicationListener注册进来;
1、从容器中拿到所有的ApplicationListener
2、将每个监听器添加到事件派发器中;
getApplicationEventMulticaster().addApplicationListenerBean(listenerBeanName);
3、派发之前步骤产生的事件;
11、finishBeanFactoryInitialization(beanFactory);初始化所有剩下的单实例bean;
1、beanFactory.preInstantiateSingletons();初始化后剩下的单实例bean
1)、获取容器中的所有Bean,依次进行初始化和创建对象
2)、获取Bean的定义信息;RootBeanDefinition
3)、Bean不是抽象的,是单实例的,是懒加载;
1)、判断是否是FactoryBean;是否是实现FactoryBean接口的Bean;
2)、不是工厂Bean。利用getBean(beanName);创建对象
0、getBean(beanName); ioc.getBean();
1、doGetBean(name, null, null, false);
2、先获取缓存中保存的单实例Bean。如果能获取到说明这个Bean之前被创建过(所有创建过的单实例Bean都会被缓存起来)
从private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);获取的
3、缓存中获取不到,开始Bean的创建对象流程;
4、标记当前bean已经被创建
5、获取Bean的定义信息;
6、【获取当前Bean依赖的其他Bean;如果有按照getBean()把依赖的Bean先创建出来;】
7、启动单实例Bean的创建流程;
1)、createBean(beanName, mbd, args);
2)、Object bean = resolveBeforeInstantiation(beanName, mbdToUse);让BeanPostProcessor先拦截返回代理对象;
【InstantiationAwareBeanPostProcessor】:提前执行;
先触发:postProcessBeforeInstantiation();
如果有返回值:触发postProcessAfterInitialization();
3)、如果前面的InstantiationAwareBeanPostProcessor没有返回代理对象;调用4)
4)、Object beanInstance = doCreateBean(beanName, mbdToUse, args);创建Bean
1)、【创建Bean实例】;createBeanInstance(beanName, mbd, args);
利用工厂方法或者对象的构造器创建出Bean实例;
2)、applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
调用MergedBeanDefinitionPostProcessor的postProcessMergedBeanDefinition(mbd, beanType, beanName);
3)、【Bean属性赋值】populateBean(beanName, mbd, instanceWrapper);
赋值之前:
1)、拿到InstantiationAwareBeanPostProcessor后置处理器;
postProcessAfterInstantiation();
2)、拿到InstantiationAwareBeanPostProcessor后置处理器;
postProcessPropertyValues();
===赋值之前:=
3)、应用Bean属性的值;为属性利用setter方法等进行赋值;
applyPropertyValues(beanName, mbd, bw, pvs);
4)、【Bean初始化】initializeBean(beanName, exposedObject, mbd);
1)、【执行Aware接口方法】invokeAwareMethods(beanName, bean);执行xxxAware接口的方法
BeanNameAware\BeanClassLoaderAware\BeanFactoryAware
2)、【执行后置处理器初始化之前】applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
BeanPostProcessor.postProcessBeforeInitialization();
3)、【执行初始化方法】invokeInitMethods(beanName, wrappedBean, mbd);
1)、是否是InitializingBean接口的实现;执行接口规定的初始化;
2)、是否自定义初始化方法;
4)、【执行后置处理器初始化之后】applyBeanPostProcessorsAfterInitialization
BeanPostProcessor.postProcessAfterInitialization();
5)、注册Bean的销毁方法;
5)、将创建的Bean添加到缓存中singletonObjects;
ioc容器就是这些Map;很多的Map里面保存了单实例Bean,环境信息。。。。;
所有Bean都利用getBean创建完成以后;
检查所有的Bean是否是SmartInitializingSingleton接口的;如果是;就执行afterSingletonsInstantiated();
12、finishRefresh();完成BeanFactory的初始化创建工作;IOC容器就创建完成;
1)、initLifecycleProcessor();初始化和生命周期有关的后置处理器;LifecycleProcessor
默认从容器中找是否有lifecycleProcessor的组件【LifecycleProcessor】;如果没有new DefaultLifecycleProcessor();
加入到容器;
写一个LifecycleProcessor的实现类,可以在BeanFactory
void onRefresh();
void onClose();
2)、 getLifecycleProcessor().onRefresh();
拿到前面定义的生命周期处理器(BeanFactory);回调onRefresh();
3)、publishEvent(new ContextRefreshedEvent(this));发布容器刷新完成事件;
4)、liveBeansView.registerApplicationContext(this);
======总结===========
1)、Spring容器在启动的时候,先会保存所有注册进来的Bean的定义信息;
1)、xml注册bean;<bean>
2)、注解注册Bean;@Service、@Component、@Bean、xxx
2)、Spring容器会合适的时机创建这些Bean
1)、用到这个bean的时候;利用getBean创建bean;创建好以后保存在容器中;
2)、统一创建剩下所有的bean的时候;finishBeanFactoryInitialization();
3)、后置处理器;BeanPostProcessor
1)、每一个bean创建完成,都会使用各种后置处理器进行处理;来增强bean的功能;
AutowiredAnnotationBeanPostProcessor:处理自动注入
AnnotationAwareAspectJAutoProxyCreator:来做AOP功能;
xxx....
增强的功能注解:
AsyncAnnotationBeanPostProcessor
....
4)、事件驱动模型;
ApplicationListener;事件监听;
ApplicationEventMulticaster;事件派发:
32. SpringMVC的流程
33 .Spring boot Spring Cloud相关组件
SpringBoot相关组件
| 名称 | 描述 |
|---|---|
| spring-boot-starter | 核心 Spring Boot starter,包括自动配置支持,日志和 YAML |
| spring-boot-starter-web | 对全栈 web 开发的支持, 包括 Tomcat 和 spring-webmvc |