目录
1.数组的定义
数组是由n(n>=1)个相同类型的数据元素组成的有限序列,数组中的每一个数据通常为数据元素。数组中的元素可以通过下标随机访问,其中下标的个数由数组的维数决定。
2.数组的特点
数组中的数据元素数目是确定的。一旦定义了一个数组,其数据元素的数目不再增减。
数组中的数据元素具有相同的数据类型。
数组的中的每个数据元素都和一组唯一的下标值对应。
数组是一种随机存储结构,可随机存储数组中的任意数据元素。
3.用顺序存储结构存储数组
由于数组一般不进行插入或删除操作,也就是说,一旦建立了数组,则结构中的数据元素个数和元素之间的关系就不再发生变动,变动的只能是数据元素的值。因此,采用顺序存储结构表示数组是自然而然的事了。
在C#中,数组实际上是对象。System.Array是所有数组类型的抽象基类型。当在程序中声明并创建了一个数组后,该数组就是一个Array类型的实例。
压缩存储:就是对矩阵中值相同的元素只分配一个存储空间,对零元素不分配空间。对于需要压缩存储的矩阵可分为特殊矩阵和稀疏矩阵。
特殊矩阵
含义:那些具有相同值元素或零元素在矩阵中分布有一定规律的矩阵。常见特殊矩阵有:对角矩阵,三对角矩阵,下三角矩阵,上三角矩阵,对称矩阵
特殊矩阵示意图:

特殊矩阵的压缩存储:(不懂!)

稀疏矩阵
含义:零元素数据远多于非零元素数目,且零元素分布无规律的矩阵
由于非零元素分布没有任何规律,所以在进行压缩存储的时候需要存储非零元素值a(ij)的同时还要存储非零元素在矩阵中的位置,即非零元素所在的行号i和列号j,这样就构成了一个三元组(i,j, aij)的线性表。
以下三元组的线性表为:(0,0,2),(0,4,6),(0,7,7),(1,2,1),(2,2,2),(2,6,3),(3,5,8),(4,3,5),(5,1,9)


三元组可以采用顺序表表示方法,也可以采用链式表示方法。
用顺序表存储稀疏矩阵的三元组:
namespace 用顺序表存储稀疏矩阵的三元组
{
struct tupletype<T>
{
public int i;//行号
public int j;//列号
public T v;//元素值
public tupletype (int i,int j,T v)
{
this.i = i;
this.j = j;
this.v = v;
}
}
class spmatrix<T>
{
private int maxnum;//非零元素的最大个数
private int md;//行数值
private int nd;//列数值
private int td;//非零元素的实际个数
private tupletype<T>[] data;//存储三元组的值
public int Maxnum { get => maxnum; set => maxnum = value; }
public int Md { get => md; set => md = value; }
public int Nd { get => nd; set => nd = value; }
public int Td { get => td; set => td = value; }
public tupletype<T>[] Data { get => data; set => data = value; }
//初始化三元组顺序表
public spmatrix() { }
public spmatrix (int maxnum,int md,int nd)
{
this.Maxnum = maxnum;
this.md = md;
this.nd = nd;
data = new tupletype<T>[Maxnum];
}
/// <summary>
/// 设置三元组表元素的值
/// </summary>
/// <param name="i"></param>
/// <param name="j"></param>
/// <param name="v"></param>
public void setData(int i,int j,T v)
{
data[td] = new tupletype<T>(i, j, v);
td++;
}
/// <summary>
/// 转置矩阵算法。未懂!
/// </summary>
/// <returns></returns>
public spmatrix <T> Transpose()
{
spmatrix<T> N = new spmatrix<T>();
N.maxnum = maxnum;
N.nd = md;
N.md = nd;
N.td = td;
N.data = new tupletype<T>[N.td];
if (td != 0)
{
int q = 0; //控制转置矩阵的下标
for (int col = 0; col < nd; col++) //扫描矩阵的列
{
for (int p = 0; p < td; p++) //p控制被转置矩阵的下标
{
if (data [p].j ==col )
{
N.data[q].i = data[p].j;
N.data[q].j = data[p].i;
N.data[q].v = data[p].v;
q++;
}
}
}
}
return N;
}
}
}
用十字链表存储稀疏矩阵的三元组:
用一维数组来描述稀疏矩阵所存在的缺点是,当创建这个一维数组时,必须知道稀疏阶段中的非零元素总数,虽然在输入矩阵时,这个数是已知的,但随着矩阵加法减法和乘法操作的执行,非零元素的数目会发生变化,因此如果不实际计算很难精确的知道非零元素的数目,但如果采用链式存储结构,就可以避免这种情况。
十字链表节点分为三类,一类是表结点,它有5个域组成,其中i和j存储的是结点所在的行和列,right和down存储的是指向十字链表中,该结点所有行和列的下一个节点的指针,v用于存放元素值;另一类结点为行头和列头结点,这个结点也由域组成,其中行和列的值均为0,没有实际意义,right和down的域用于在行方向和列方向上指向表结点,next用于指向下一个行或列的表头结点,最后一类结点称为总表头结点,这类结点与表头之类的结构和形式一样,只是他的i和j存放的是矩阵的行和列数。
十字链表结点结构:
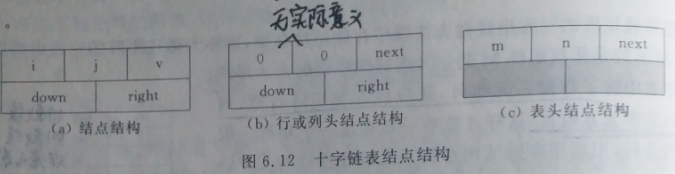
十字链表中的每一行和每一年的链表。都是一个循环链表,都有一个表头结点。
一个稀疏矩阵的十字链表示意图:
