在文件下载时候通常文件名是中文时会出现乱码问题,有两种解决方案
第一种 (在页面对代码进行编码) 不推荐使用
jsp代码
<%@page import="java.net.URLEncoder"%>
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>文件下载</title>
</head>
<body>
<a href="/chapter12/DownloadServlet?filename=timg.jpg">文件下载-----文件名是英文</a>
<br><br><br><br><br>
<a href="/chapter12/DownloadServlet?filename=<%=URLEncoder.encode("解决办法.docx", "utf-8")%>">文件下载----文件名是中文第一种方案</a>
<br><br><br><br><br>
</body>
</html>
DownloadServlet代码
package com.zch.upload;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
*
* @ClassName: DownloadServlet.java
* @Description: 文件的下载
* @author 萌城小小小少年
* @version V1.0
* @Date 2019年2月15日 下午7:23:35
*
*/
public class DownloadServlet extends HttpServlet {
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse
* response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 处理响应中文的乱码问题
response.setContentType("text/html;charset=utf-8");
// 1.获取下载文件的名称
String filename = request.getParameter("filename");
//处理get请求的中文乱码问题
filename=new String(filename.getBytes("iso-8859-1"),"utf-8");
// 2.获取文件的mime类型
String fileType = getServletContext().getMimeType(filename);
// 设置两个头
response.addHeader("Content-Type", fileType);
//通过页面编码解决中文乱码
//response.addHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(filename,"utf-8"));
// 4.文件的下载
String folder = "/download/";
// 4.1获取文件的字节输入流
InputStream in = getServletContext().getResourceAsStream(folder + filename);
// 4.2获取文件的字节输出流
OutputStream out = response.getOutputStream();
// 5.流的对接
byte[] buffer = new byte[1024];
int len = 0;
while ((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
// 关闭流
out.close();
in.close();
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse
* response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}
这种方法不推荐使用,因为不适用所有的浏览器,比如火狐有时候会出现以下问题
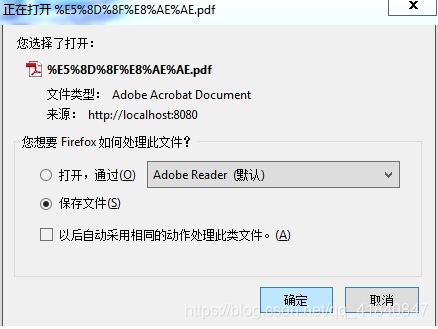
第二种方案(推荐使用)
jsp代码
<%@page import="java.net.URLEncoder"%>
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>文件下载</title>
</head>
<body>
<a href="/chapter12/DownloadServlet?filename=timg.jpg">文件下载-----文件名是英文</a>
<br><br><br><br><br>
<a href="/chapter12/DownloadServlet?filename=<%=URLEncoder.encode("解决办法.docx", "utf-8")%>">文件下载----文件名是中文第一种方案</a>
<br><br><br><br><br>
<a href="/chapter12/DownloadServlet?filename=解决办法.docx">文件下载----文件名是中文第二种方案</a>
</body>
</html>
DownUtil代码 (这段代码为模板代码,不需要记忆理解即可)
package com.zch.upload;
import sun.misc.*;
import java.io.UnsupportedEncodingException;
import java.net.URLEncoder;
import javax.servlet.http.HttpServletRequest;
public class DownUtils {
public static String filenameEncoding(String filename, HttpServletRequest request) throws UnsupportedEncodingException {
// 获得请求头中的User-Agent
String agent = request.getHeader("User-Agent");
// 根据不同的客户端进行不同的编码
if (agent.contains("MSIE")) {
// IE浏览器
filename = URLEncoder.encode(filename, "utf-8");
} else if (agent.contains("Firefox")) {
// 火狐浏览器
BASE64Encoder base64Encoder = new BASE64Encoder();
filename = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?=";
} else {
// 其它浏览器
filename = URLEncoder.encode(filename, "utf-8");
}
return filename;
}
}
DownloadServlet代码
package com.zch.upload;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
*
* @ClassName: DownloadServlet.java
* @Description: 文件的下载
* @author 萌城小小小少年
* @version V1.0
* @Date 2019年2月15日 下午7:23:35
*
*/
public class DownloadServlet extends HttpServlet {
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse
* response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 处理响应中文的乱码问题
response.setContentType("text/html;charset=utf-8");
// 1.获取下载文件的名称
String filename = request.getParameter("filename");
//处理get请求的中文乱码问题
filename=new String(filename.getBytes("iso-8859-1"),"utf-8");
// 2.获取文件的mime类型
String fileType = getServletContext().getMimeType(filename);
String name=DownUtils.filenameEncoding(filename, request);
// 设置两个头
response.addHeader("Content-Type", fileType);
response.addHeader("Content-Disposition", "attachment;filename=" +name);
// 4.文件的下载
String folder = "/download/";
// 4.1获取文件的字节输入流
InputStream in = getServletContext().getResourceAsStream(folder + filename);
// 4.2获取文件的字节输出流
OutputStream out = response.getOutputStream();
// 5.流的对接
byte[] buffer = new byte[1024];
int len = 0;
while ((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
// 关闭流
out.close();
in.close();
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse
* response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}