第一步 从官网 http://yann.lecun.com/exdb/mnist/ 下载MNIST 数据库 然后解压缩
第二步 读入数据并测试 借鉴博客[1]
下载的文件为二进制文件 格式如下
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
读取也就是之前我们要读取4个 32 bit integer
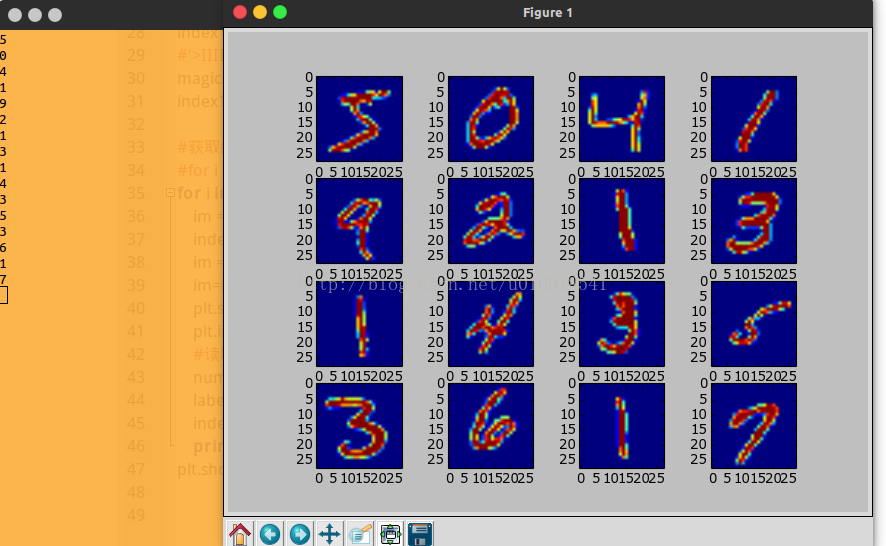
测试读取前16个数字数字 并同时输入标签
# -*- coding: utf-8 -*-
import struct
import matplotlib.pyplot as plt
import operator
import numpy as np
# 读取trainingMat
filename = 'train-images.idx3-ubyte'
binfile = open(filename , 'rb')
buf = binfile.read()
index = 0
#'>IIII'使用大端法读取四个unsigned int32
magic, numImages , numRows , numColumns = struct.unpack_from('>IIII' , buf , index)
index += struct.calcsize('>IIII')
#读取labels
filename1 = 'train-labels.idx1-ubyte'
binfile1 = open(filename1 , 'rb')
buf1 = binfile1.read()
index1 = 0
#'>IIII'使用大端法读取两个unsigned int32
magic1, numLabels1 = struct.unpack_from('>II' , buf , index)
index1 += struct.calcsize('>II')
#获取经过PCA 处理过的traingMat 和 label
#for i in range(trainingNumbers):
for i in range(16):
im = struct.unpack_from('>784B' ,buf, index)
index += struct.calcsize('>784B')
im = np.array(im)
im=im.reshape(28,28)
plt.subplot(4,4,i+1)
plt.imshow(im)
#读取标签
numtemp = struct.unpack_from('1B' ,buf1, index1)
label = numtemp[0]
index1 += struct.calcsize('1B')
print label
plt.show()
加入PCA算法 与 KNN算法 ,这两个算法原理不再重复,函数来源于机器学习实战那本书 完整算法代码如下
# -*- coding: utf-8 -*-
from numpy import *
import numpy as np
import struct
import matplotlib.pyplot as plt
import operator
#定义一个全局特征转换变量 这个变量是在PCA中求出的
global redEigVects
def pca(dataMat, topNfeat=9999999):
global redEigVects
meanVals = mean(dataMat, axis=0)
meanRemoved = dataMat - meanVals #remove mean
covMat = cov(meanRemoved, rowvar=0)
eigVals,eigVects = linalg.eig(mat(covMat))
eigValInd = argsort(eigVals)#sort, sort goes smallest to largest
eigValInd = eigValInd[:-(topNfeat+1):-1] #cut off unwanted dimensions
redEigVects = eigVects[:,eigValInd] #reorganize eig vects largest to smallest
#得到低维度数据
lowDDataMat = meanRemoved * redEigVects#transform data into new dimensions
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat
def KNN(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) #axis=0, 表示列。axis=1, 表示行。
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 读取trainingMat
filename = 'train-images.idx3-ubyte'
binfile = open(filename , 'rb')
buf = binfile.read()
index = 0
#'>IIII'使用大端法读取四个unsigned int32
magic, numImages , numRows , numColumns = struct.unpack_from('>IIII' , buf , index)
index += struct.calcsize('>IIII')
'''
# 输出大端数
print magic
print numImages
print numRows
print numColumns
'''
#读取labels
filename1 = 'train-labels.idx1-ubyte'
binfile1 = open(filename1 , 'rb')
buf1 = binfile1.read()
index1 = 0
#'>IIII'使用大端法读取两个unsigned int32
magic1, numLabels1 = struct.unpack_from('>II' , buf , index)
index1 += struct.calcsize('>II')
#设置训练数目为2500个
trainingNumbers=2500
#降维后的维度为7个维度 降维后的数据为40维度
DD=40
#初始化traingMat
trainingMatO=zeros((trainingNumbers,28*28))
#初始化标签
trainingLabels=[]
#获取经过PCA 处理过的traingMat 和 label
#for i in range(trainingNumbers):
for i in range(trainingNumbers):
im = struct.unpack_from('>784B' ,buf, index)
index += struct.calcsize('>784B')
im = np.array(im)
trainingMatO[i]=im
#读取标签
numtemp = struct.unpack_from('1B' ,buf1, index1)
label = numtemp[0]
index1 += struct.calcsize('1B')
trainingLabels.append(label)
#PCA
trainingMat,reconMat=pca(trainingMatO,DD)
'''
**************************************************
'''
# 读取testMat
filename3 = 't10k-images.idx3-ubyte'
binfile3 = open(filename3 , 'rb')
buf3 = binfile3.read()
index3 = 0
#'>IIII'使用大端法读取四个unsigned int32
magic3, numImages3 , numRows3 , numColumns3 = struct.unpack_from('>IIII' , buf3 , index3)
index3 += struct.calcsize('>IIII')
#读取labels
filename4 = 't10k-labels.idx1-ubyte'
binfile4 = open(filename4, 'rb')
buf4 = binfile4.read()
index4= 0
#'>IIII'使用大端法读取两个unsigned int32
magic4, numLabels4 = struct.unpack_from('>II' , buf4 , index4)
index4 += struct.calcsize('>II')
'''
**************************************************
'''
#测试数据
testNumbers=300
#测试维度
errCount=0
#获取经过PCA 处理过的testMat 和 label
for i in range(testNumbers):
im3 = struct.unpack_from('>784B' ,buf3, index3)
index3 += struct.calcsize('>784B')
im3 = np.array(im3)
#新进来的数据 进行降维处理
meanVals = mean(im3, axis=0)
meanRemoved = im3 - meanVals #remove mean
#这个时候使用的降维特征变量为上边给训练数组得出的特征量
testingMat=meanRemoved*redEigVects
#读取标签
numtemp4 = struct.unpack_from('1B' ,buf4, index4)
label4 = numtemp4[0]
index4 += struct.calcsize('1B')
#.getA() 函数的意思是 获取该矩阵 好像PCA算法返回的是一个对象 所以此处提取了一下矩阵数组
classifierResult = KNN(testingMat.getA(), trainingMat.getA(), trainingLabels, 10)
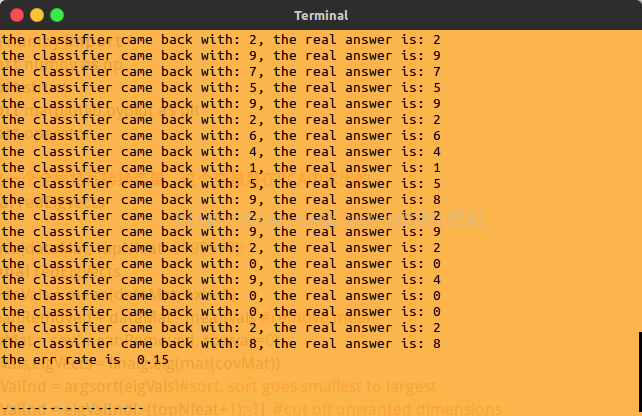
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, label4)
if classifierResult is not label4:
errCount=errCount+1
print 'the err rate is ',float(errCount)/testNumbers
效果如下
借鉴博客
[1]http://www.cnblogs.com/x1957/archive/2012/06/02/2531503.html python 读取Mnist
[2]http://blog.codinglabs.org/articles/pca-tutorial.html pca简单的数学原理
[3] 机器学习实战 书籍 第二章KNN 第十三章PCA降维