.上一篇博客中讲述了爬虫的数据存储在TXT,JSON,CSV中,这篇博客接着讲数据存储在MySQL中。
在python2中,基本使用Mysqldb连接数据库,但是这个库不支持python3,所以采用pymysql。
一:安装pymysql
pip install pymysql
二:使用数据库
1.创建连接
import pymysql
conn = pymysql.connect(host = "localhost",user = "root",password = "yanzhiguo",port = 3306,database = "student")
只有具备这些参数,才能连接数据库
2.创建游标
cur = conn.cursor()3.执行sql语句
sql = "select * from goods"
cur.execute(sql)4.提交
conn.commit()5.关闭游标
cur.close()6.关闭连接
conn.close()注意:存在中文的时候,连接需要添加charset='utf8',否则中文显示乱码
执行commit()方法才能事项数据插入到数据库
对于执行操作,加上异常处理的框架使代码更具健壮性
try: cursor.esecute(sql) conn.commit() except: conn.rollback()
对于数据的增加,删除,更新都可以直接利用SQL的原生语句来执行,但是对于数据的查询有所不一样
数据查询中有三个函数:
fetchone():拿取一个数据,返回元组形式
fetchall():拿取全部数据,返回二重元组
fetchmany:(n):拿取n个数据,返回二重元组
实例:
import pymysql
conn = pymysql.connect(host = "localhost",user = "root",password = "yanzhiguo140710",port = 3306,database = "student")
cur = conn.cursor()
sql = "select * from goods"
cur.execute(sql)
print(cur.fetchall())
conn.commit()
cur.close()
conn.close()结果是:
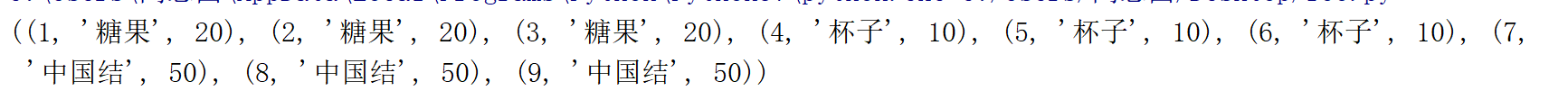
这里需要注意一个问题,查询的内部有一个指针来指向查询的位置,可以理解为文件的指针,随着指针的偏移来获取数据。
其实这个python库很好用,关键是要熟练的掌握SQL才行,关于pymysql的介绍就到这,有兴趣的小伙伴可以一起交流哦!