整理了之前做的项目.还需要不断地优化.
Review:
一个重要的问题就是: 如何利用有限视点位置的全景视频来高效的渲染与显示用户新视点位置的视频内容?
- 基于深度信息的图像绘制技术,即DIBR技术
在 项目记录: 3DOF+实时渲染 之 虚拟视点合成 中介绍过了 3DOF+的概念以及相关的一些算法.
3DOF+渲染系统
在上述的调研的基础上,我们设计并搭建一套 3DOF+视频的渲染平台,利用极少视点位置的视频信息高效且准确渲染观看用户实际视点位置观看的视频内容。
- 基于深度图像的全景虚拟视图合成算法研究
基于深度图像的虚拟视图绘制技术(DIBR) 是预测虚拟视点视频内容的一种
最重要的技术, 其利用 3D-Warping 投影、 视图融合以及空洞填补等技术可直接
生成虚拟视点处的图像。传统的 DIBR 技术针对的是普通平面视频,而对于全景
视频,由于其映射方式不同于平面视频,现有的算法无法直接应用于全景视频,
需要根据其特有的映射关系定制全景视频的虚拟视图合成算法。 - 基于 GPU 硬件加速的快速合成算法研究
传统的平面视频分辨率较低, DIBR 算法绘制速度快。 但高质量的头戴式 VR全景视频, 其分辨率至少为 4K, 则处理全景视频需要大量的计算资源和极大的时间复杂度, 所以需要一种快速的合成算法来实现全景的虚拟视图的计算。
系统模块框图

- 我负责整个渲染系统的搭建与算法的实现.
- 系统主要四个模块:
- VR头盔运动跟踪模块
- 参考视图的选择模块
- 虚拟视图合成模块
- 渲染显示模块
VR头盔运动跟踪模块
- 该模块主要就是需要求解出用户新视点的位置和用户当前的视角朝向.为下一步参考视图的选择提供准备.
参考视图的选择模块
- 输入的视频源的模型
- 根据这些信息和用户当前的朝向信息求解出两个最邻近的参考视图作为
虚拟视图合成模块的输入
虚拟视图合成模块
这个平台主要将采用 NVIDIA 所推出的一种整合技术方案 CUDA(Compute Unified Device Architecture),将每一个参考视图作为一个网格(Grid) 分成若干个块(Block),每一个像素映射成为一个线程(Thread),并发地进行计算。 映射关系如图所示。
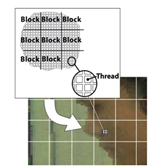
- 选择了最近邻的两个参考视图. 在GPU上实现了虚拟视图合成算法.大致的过程如下所示:

渲染显示模块
- 将合成的虚拟视图进行渲染显示. 运用的技术是CUDA和OpenGL互操作.
项目中的难点
- 系统的搭建:
- 视频源问题: 由于MPEG提供的3DOF+的全景测试序列较少. 只有三组. 我们选择了用
Facebook X24相机拍摄的分辨率为 2048x2048的纹理以及深度图. 其中纹理图为8bit. 而深度图为16bit. - 在进行参考视图合成之前,我们是利用 NVIDIA VIDEO SDK 进行了硬解码. 由于参考视图选择为两幅图像,所以需要两个硬解码器完成解码工作. 带来了 两个硬解码器上下文的问题.
- 视频源问题: 由于MPEG提供的3DOF+的全景测试序列较少. 只有三组. 我们选择了用
- 实时性的问题:
- 一开始,在进行系统设计的时候,使用的多线程来加速. 相当于把一幅图像切成了 多幅片段 分别进行计算. 然而计算量实在比较大.所以想到了采用
GPU进行加速.
- 一开始,在进行系统设计的时候,使用的多线程来加速. 相当于把一幅图像切成了 多幅片段 分别进行计算. 然而计算量实在比较大.所以想到了采用
- OpenGL上下文问题:
- OpenGL是一个状态机. 在多线程环境下. 每一个时刻,其上下文只能由一个线程所有拥有.我们的线程中采用了多线程的设计.一个线程负责做绘制操作.另一个线程负责合成虚拟视图. 都会访问OpenGL的纹理空间. 所以需要注意这个上下文问题.