零基础学nlp【1】 多任务训练
论文: Luong M T, Le Q V, Sutskever I, et al. Multi-task sequence to sequence learning[J]. arXiv preprint arXiv:1511.06114, 2015.](https://arxiv.org/pdf/1511.06114.pdf)
整体思路
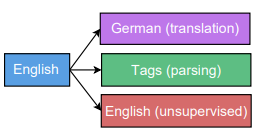
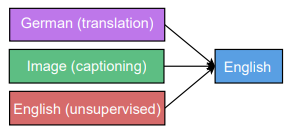
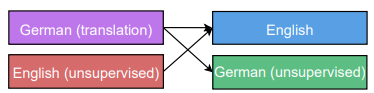
多任务训练如图所示,分别是单对多,多对单,多对多。举个例子,在单对多任务训练中,采用相同的encoder不同的decoder,训练encoder的时候交叉使用不同的task对encoder进行训练,可以看做encoder融合了不同task所需的信息。在这样的多任务训练模式下,作者发现通过调节次要task 的mixing ratio(比如主要任务是翻译,每训练100次翻译任务后用文本分析任务训练10次,则mixing ratio是0.1)可以使主要任务在测试集上得到更好的效果。
细节
- 通过多任务训练,使模型效果提升,作者通过三种结构(one-to-many,many-to-one,many-tomany)以及task大小的配比(large task with small task、large task with medium task、large task with large task)验证了这种方法的效果。主要结论是合适的mixing_ratio(大约0.1)可以提升性能
- 作者使用了4层lstm网络,每层lstm有1000个cell,发现效果比以前的一篇论文好,证明了网络大对于seq2seq模型是有效的。
- 作者也考虑了在多任务中添加无监督学习的任务,主要包括有skip-thought任务和autoencoding任务具体含义在名词解释中。
名词解释
- MTL: 多任务训练(multi-task learning)
- skip-thought object:一种无监督训练方法,把一句句子分为三部分,用中间的部分作为输入预测之后的部分和之前的部分。
- autoencoding:一种无监督训练方式,encoder输入句子,得到向量后在decoder预测输出还是句子本身。
- BLEU:机器翻译质量评测算法(Bilingual Evaluation Understudy) 具体可以参考这里
- F1:用于分类效果判断
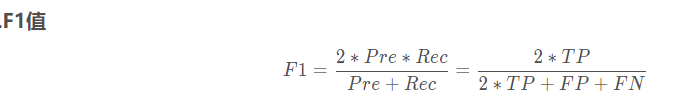
其中
True Positive(TP):将正类预测为正类数
True Negative(TN):将负类预测为负类数
False Positive(FP):将负类预测为正类数
False Negative(FN):将正类预测为负类数- 用到的数据集:
- MT(machine translation)机器翻译,数据集WMT
- caption:看图写标题
- parsing: 分析,类似于给标签,数据集 PTB,HC