版权声明:原创 https://blog.csdn.net/qq_41058594/article/details/88303892
前几天由于没钱了想挣点外快,经同学介绍,有个打字接单挣钱的,于是乎我就加进去,做了两三天,也就挣了50多,第一次是手写的,纯手动打字,表示很累!最后我就灵机一动,写个脚本吧,用python脚本来帮我识别其内容,然后输入到world文件里边,并设置好字体,字体大小…
该过程是这样的
首先导入类,把前提准备好:
import configparser # 配置文件模块 读写配置文件
import docx
from aip import AipOcr # 文字识别模块
from docx.shared import Pt
全局变量:
QQname = input('请输入你要输入的QQname:')
number = input('请输入你要输入的number:')
time = input('请输入你要输入的time:')
money = input('请输入你要输入的money:')
ceshi = []
start = []
我采用的是百度的图片内容识别api:
没有app_id,api_key,secret_key的得去百度注册获得:
并用记事本制作启动文件passwd.ini:
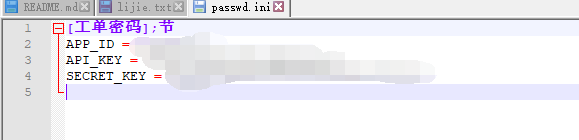
保存该文件,然后打开pycharm或者你的python的idle来编写代码:
构建类 BaiDuAPI 来规范代码:
class BaiDuAPI(object):
#特殊 构造函数 初始化函数
def __init__(self,filePath):
target = configparser.ConfigParser()
target.read(filePath,encoding='utf-8-sig')
app_id = target.get('工单密码','APP_ID')
api_key = target.get('工单密码', 'API_KEY')
secret_key = target.get('工单密码', 'SECRET_KEY')
self.client = AipOcr(app_id,api_key,secret_key)
识别后输出内容到 world:
def picture2Text(self,filePath):
# 读取图片
images = self.getPicture(filePath)
texts = self.client.basicGeneral(images)
file=docx.Document()
file.styles['Normal'].font.name = u'宋体'
file.styles['Normal'].font.size = Pt(10.5)#五号字体
for word in texts['words_result']:
paragraph = file.add_paragraph(word.get('words',''))
ph_format =paragraph.paragraph_format
ph_format.line_spacing=Pt(12)
#print(word.get('words',''))
ceshi.append(word.get('words',''))
print(ceshi)
file.save("{}.docx".format(QQname+'_'+number+'_'+time+'_'+money))
从 passwd.ini 读出内容用于激发识别 API:
def getPicture(self,filePath):
with open(filePath,'rb') as fp:
return fp.read()
主函数:
if __name__ == '__main__':
print('---------正在检测-----------')
baiduapi = BaiDuAPI('passwd.ini')
baiduapi.picture2Text('2.png')
print('---------检测完成-----------')
这就是我上次python接单代码
!!!!!!!!!言归正传--------
python API识别图片之后运用爬虫对内容进行翻译--------实例:PDF英文文档翻译



一言不合上代码:
# encoding:utf-8
import os
from tkinter import *
from tkinter import filedialog
import urllib.request
import configparser # 配置文件模块 读写配置文件
import docx
from aip import AipOcr # 文字识别模块
from docx.shared import Pt
import urllib.parse
import urllib.request
#======================
b = 0 #确定点击次数
#打开文件UI界面
class FileDownload:
def __init__(self, master):
self.filename=StringVar()
self.filename.set('选择要打开的文件信息')
self.src_dir=''
self.urls=[]
# tkinter刚开始不熟悉,布局麻烦,这里使用的网格布局,row,column 的index,定位cell
open_btn=Button(master, text="打开文件",width=15,height=3,borderwidth=2,
command=self.openfile)
show_btn=Button(master, text="确定",width=4,height=3,borderwidth=2,
command=self.show_inp)
open_btn.grid(row=0,column=0,ipadx=5,ipady=3,padx=10,pady=3)
show_btn.grid(row=0,column=5,ipadx=5,ipady=3,padx=10,pady=3)
self.file_label=Label(master,textvariable=self.filename,wraplength=250,fg='green',bg='white',)
self.file_label.grid(row=0,column=1,rowspan=2,ipadx=200,ipady=15,padx=10,pady=2)#,padx=20,pady=10,
self.text=Text(master,width=100,height=100,bg='grey',fg='blue')
self.text.grid(row=3,columnspan=6,ipadx=40,ipady=100)
def openfile(self):
global click
# 系统默认打开用户的桌面文件
default_dir=os.path.join(os.path.expanduser("~"), 'Desktop')
fname = filedialog.askopenfilename(title='选择打开的文件', filetypes=[('All Files', '*')],
initialdir=(os.path.expanduser(default_dir)))
print('打开的文件',fname)
baiduapi.picture2Text('{}'.format(fname))
click = True
def show_inp(self):
#print(click)
k = 0 #文件选择次数
global b
b += 1
print('没选择文件之前 b:',b)
try :
if click == True:#选择文件
k += 1
print(k)
if k == 1 and b == 1:
print(inp_list)
for i in inp_list:
self.text.insert(INSERT, '{}'.format(youdao(i)+'\n'))
# del inp_list[-len(inp_list):]
del inp_list[-len(inp_list):]
if b>k:
print('此时的b,k','{},{}'.format(b,k))
b,k = 0,0
click == False
else:
b = 0
print('必须选择文件!')
print(k,b)
except:
print('不知道哪里出错了!')
# a = baiduapi.picture2Text('1.png')
# for i in a:
# self.text.insert(INSERT, '{}'.format(i+'\n'))
#========识别部分==========
class BaiDuAPI(object):
#特殊 构造函数 初始化函数
def __init__(self,filePath):
target = configparser.ConfigParser()
target.read(filePath,encoding='utf-8-sig')
app_id = target.get('工单密码','APP_ID')
api_key = target.get('工单密码', 'API_KEY')
secret_key = target.get('工单密码', 'SECRET_KEY')
self.client = AipOcr(app_id,api_key,secret_key)
def picture2Text(self,filePath):
# inp_list = []
# 读取图片
images = self.getPicture(filePath)
texts = self.client.basicGeneral(images)
file=docx.Document()
# file.styles['Normal'].font.name = u'宋体'
# file.styles['Normal'].font.size = Pt(10.5)#五号字体
for word in texts['words_result']:
paragraph = file.add_paragraph(word.get('words',''))
ph_format =paragraph.paragraph_format
ph_format.line_spacing=Pt(12)
inp = word.get('words','')
print(inp)
inp_list.append(inp)
print(inp_list)
# file.save("{}.docx".format(QQname+'_'+number+'_'+time+'_'+money))
def getPicture(self,filePath):
with open(filePath,'rb') as fp:
return fp.read()
#=====================!
#========>翻译部分
def youdao(words):
# 构建url
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
# 构建请求头
headers = {
"User-Agent" : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
}
# 构建请求体
format_data = {
'i': words,
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':'1526368137702',
'sign':'f0cd13ef1919531ec9a66516ceb261a5',
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTIME',
'typoResult':'true'
}
# 进行url编码
format_data = urllib.parse.urlencode(format_data).encode("utf-8")
# 获取request文件(传入了data参数,就是post请求)
request = urllib.request.Request(url, data = format_data, headers = headers )
# 打开请求文件
response = urllib.request.urlopen(request)
# 读取文件内容
content = response.read()
content = eval(content)
ret = content["translateResult"][0][0]['tgt']
print(ret)
return ret
#======================!
if __name__=='__main__':
inp_list = []
click = False
tker = Tk()
baiduapi = BaiDuAPI('passwd.ini')
tker.title("pdf翻译器")
tker.columnconfigure(0, weight=3)
tker.geometry('700x480') # 设置主窗口的初始大小640x480
app = FileDownload(tker)
tker.mainloop()
当然本程序识别率我还没有计算,然后其中呢有一点点小bug,希望大家测试过后基于反馈,届时可以和我交流一下~!
我接下来做一下识别准确率和利用 opencv搞一下,有时间再 Tensorflow搞一下。
对了,需要翻译的图片得手动截图哦!
有什么改进的地方,欢迎评论…