1.随机森林
随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法
每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想
若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想(关于bagging的一个有必要提及的问题:bagging的代价是不用单棵决策树来做预测,具体哪个变量起到重要作用变得未知,所以bagging改进了预测准确率但损失了解释性。)
2.随机森林的特点
- 较好的准确率
- 有效的运行大数据集
- 处理高维特征,不需要降维
- 能够评估各个特征在分类问题上的重要性
- 在生成过程中,能够获取到内部生成误差的一种无偏估计
3基础知识
- 某个类(xi)的信息可以定义如下:
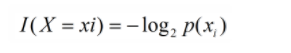
I(x)用来表示随机变量的信息,p(xi)指是当xi发生时的概率
熵是用来度量不确定性的,熵越大,不确定性越大,特征选择的不好。
信息增益是决策树中用来选择特征的指标,信息增益越大,特征选择的越好。
- 决策树
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。常见的决策树算法有C4.5、ID3和CART。
- 集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
4 随机森林的生成
1)如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
2)如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时,从这m个特征中选择最优的;
3)每棵树都尽最大程度的生长,并且没有剪枝过程。
根节点包含样品全集
1 信息增益

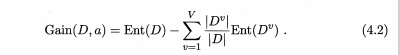
例如:

在上表中,总共有17个样例:正例即是好瓜 p1=8/17,反例是坏瓜,占据9/17;
于是根据式子4.1,该根节点的信息熵为:

我们要计算出当前属性集合{色泽,根蒂,敲声,纹理,脐部,触感}中每个属性的信息增益.以属性"色泽"为例,它有 3个可能的取值: {青绿,乌黑,浅白}.若使用该属性进行划分,则可得到 3个子集,分别记为: D1(青绿), D2 (乌黑), D3(浅白)。
子集D1包含编号为 {1 4, 6, 10, 13, 17} 6个样例,其中正例占 p1=3/6,反例占p2=3/6;
子集D2包含编号为 {2 3, 7, 8, 9, 15} 6个样例,其中正例占 Pl = 4/6,反例占有P2 =2/6;
子集D3包含编号为 {5 11, 12, 14, 16}5 个样例,其中正例占 pl=1/5 ,反例占有p2=4/5;
根据式 (4.1) 可计算出用"色泽"划分之后所获得3个分支结点的信息熵为:

更具式子4.2可以计算出属性色泽的信息增益为:

类似的,可以计算出其他五类的属性的信息增益结果:
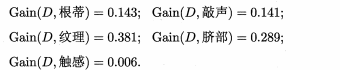
在这六类当中,纹理的属性信息增益最大,所以,它被选为划分的属性。

有因为纹理中包含了三个属性,分别是清晰,模糊,稍糊三类;
然后,决策树学习算法将对每个分支结点做进一步划分.以图 4.3 中第一个分支结点( "纹理=清晰" )为例,该结点包含的样例集合 中有编号为 {1,2, 3, 4, 5, 6, 8, 10, 15} 9个样例 正例=7/9,反例=2/9;可用属性集合为{色泽,根蒂,敲声,脐部,触感}.基于 D1计算出各属性的信息增益:

第一步,先计算在基于清晰纹理上为根节点,计算信息熵:

按照上面的思路,依次计算出剩余四个属性的信息熵。

最终生成这样的决策树
