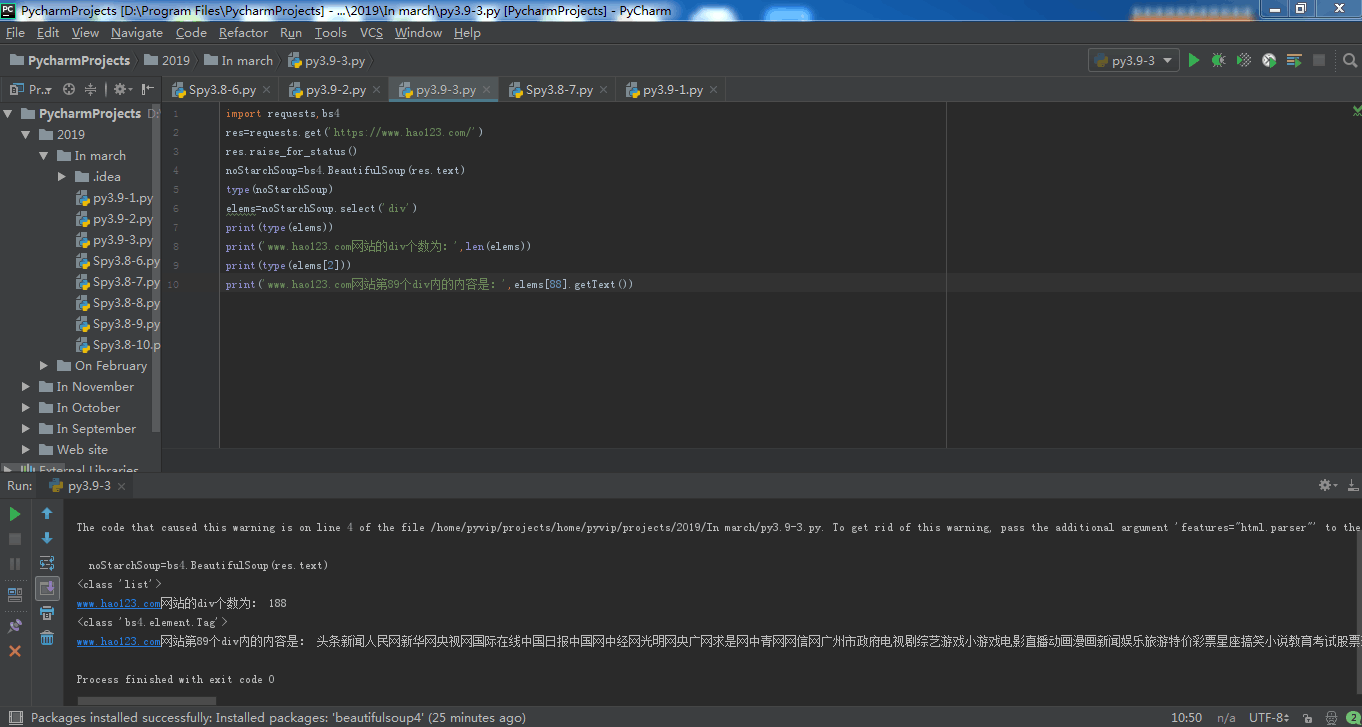
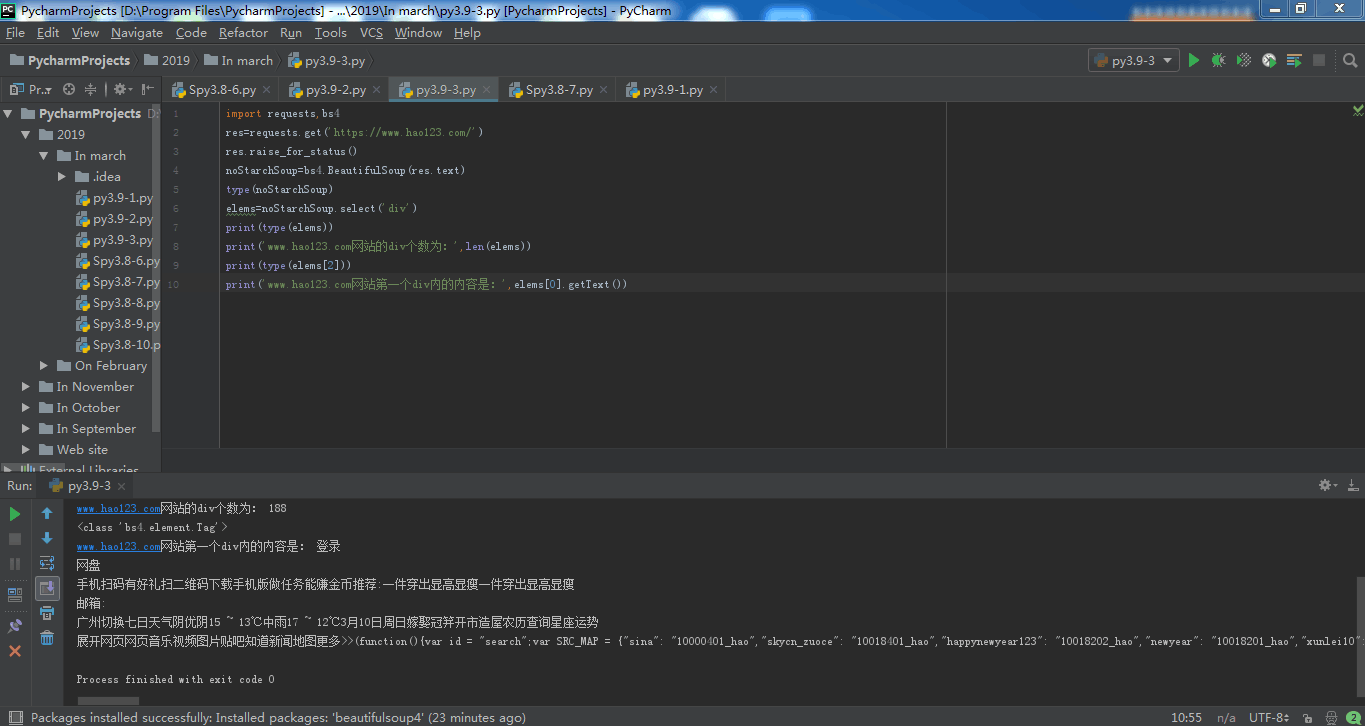
import requests,bs4
res=requests.get('https://www.hao123.com/')
res.raise_for_status()
noStarchSoup=bs4.BeautifulSoup(res.text)
type(noStarchSoup)
elems=noStarchSoup.select('div')
print(type(elems))
print('www.hao123.com网站的div个数为:',len(elems))
print(type(elems[2]))
print('www.hao123.com网站第89个div内的内容是:',elems[88].getText())