Flume 海量日志收集利器
关于日志收集
服务器日志收集
- 服务器日志是大数据系统中最主要的数据来源之一
- 服务器日志可能包含的信息
- 访问信息
- 系统信息
- 其他业务信息
- 基于服务器日志的应用
- 业务仪表盘:PV、UV等
- 线上查错:错误日志查询
- 系统监控:调用链、接口访问统计等
- 其他数据应用
- 服务器日志的特点:
- 不间断,流式产生
- 数据量大,信息量大
- 源头分散
日志采集系统的一般架构
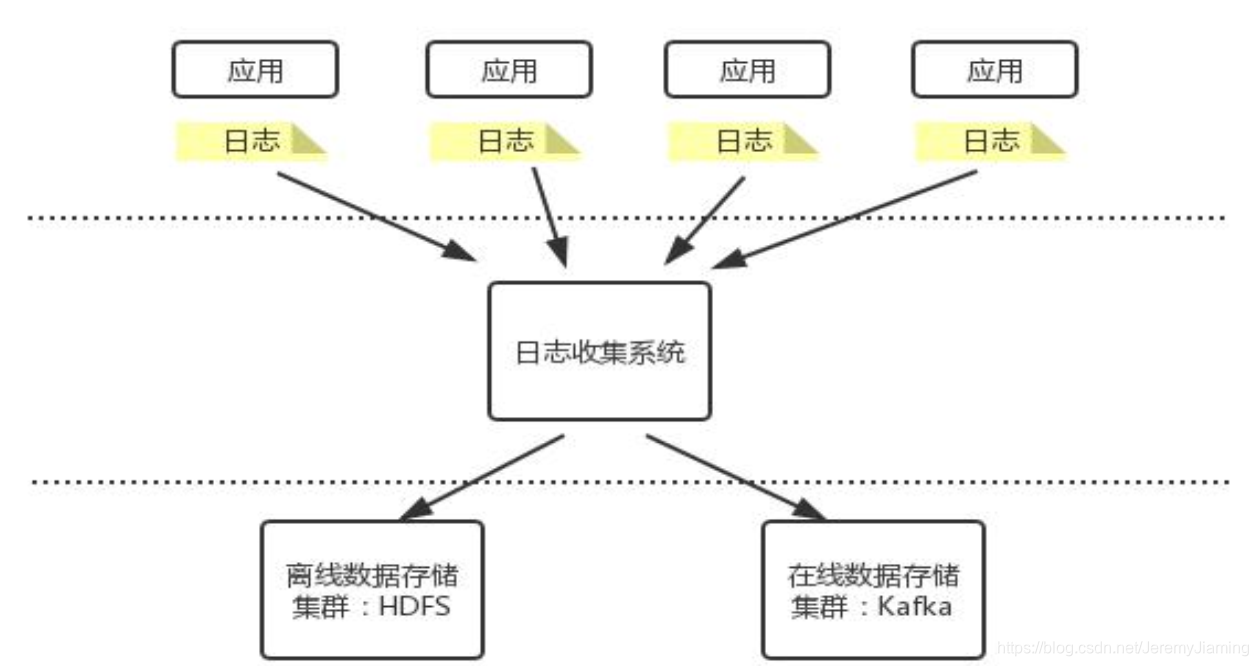
日志采集系统的设计要求
- 系统可用性:采集系统自身的健壮性
- 可扩展性:可以随着应用系统的规模及数据量的增加而线性扩展
- 可靠性:不会丢失数据
- 灵活性:支持多种数据源;支持多种处理方式;支持多种采集目的地;支持对数据的预处理
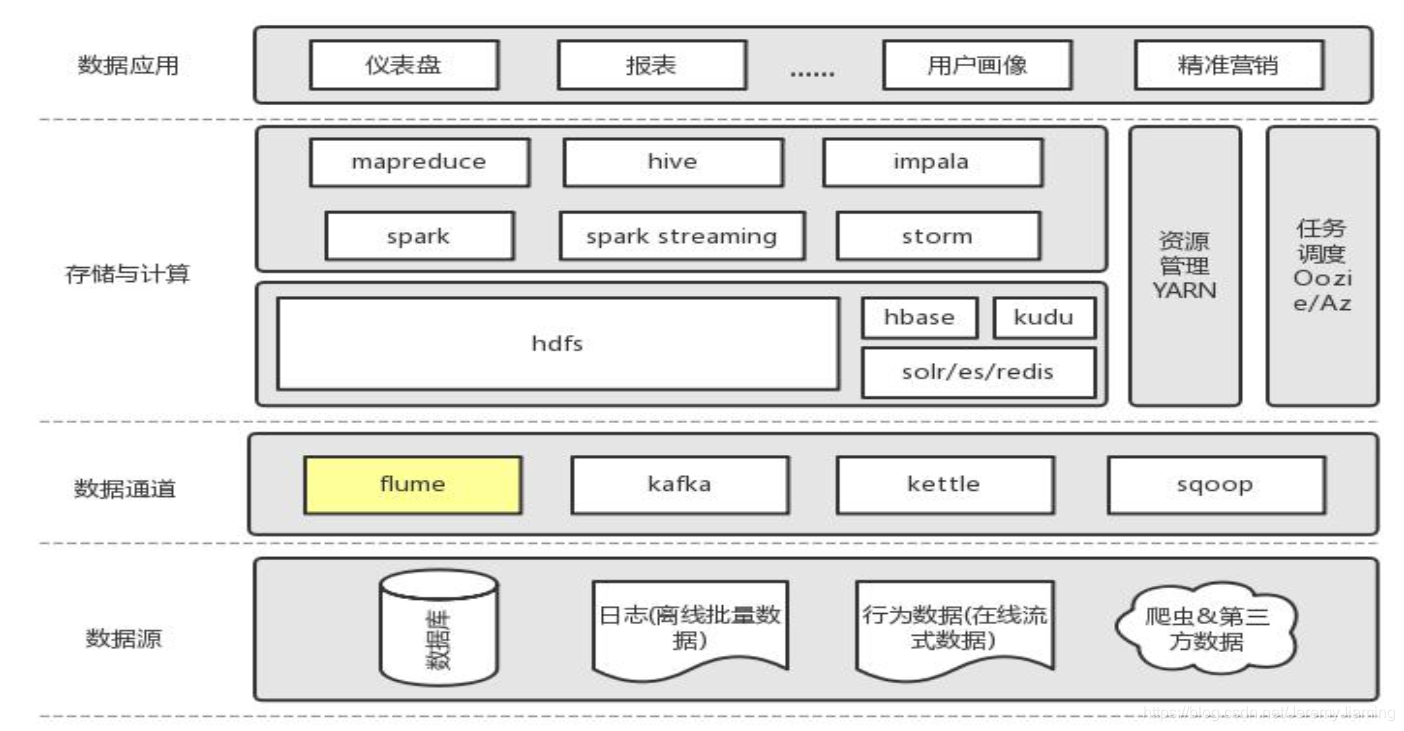
Flume简介
是什么?
一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Cloudera公司出品。
角色
版本
- Flume OG(original generation,2009年7月):分布式日志收集系统,有Master概念,依赖于Zookeeper,分为agent,collector,storage三种角色
- Flume NG(next generation,2011年10月):代码重构,功能精简,去掉master,collector角色,专注数据的收集与传递
Flume组成、安装与配置
组成
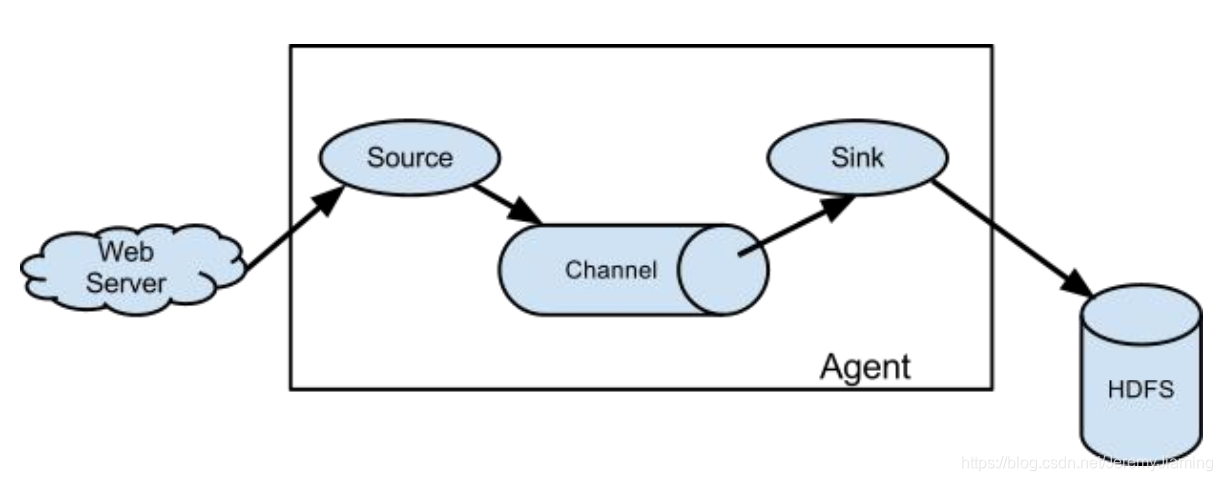 Flume Flow:
Flume Flow:
- Flow: 数据采集流程
- Event: 消息处理的最小单位, 带有一个可选的消息头。实际中event粒度一般较小,降低消息传送失败的成本。 大小由source端决定。
- Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink
- Source: 以event为单位接收信息,并确保信息被推送(push)到channel
- Channel: 缓存信息, 确保信息在被sink处理前不会丢失
- Sink:从channel中拉取(pull)并处理信息
- Interceptor: event拦截器, 可以修改或丢弃event。ex: ip:interceptor,time:interceptor,过滤爬虫用户(etl)。
处理流程:
source以event为单位从数据源接收信息, 然后保存到一个或多个channel中(可以经过一个或多个interceptor的预处理) , sink从channel中拉取并处理信息(保存, 丢弃或传递到下一个agent) , 然后通知channel删除信息。
安装
依赖:
- jdk1.8
步骤:
- 下载安装包
- 解压
- 配置flume-env.sh : 设置JAVA_HOME
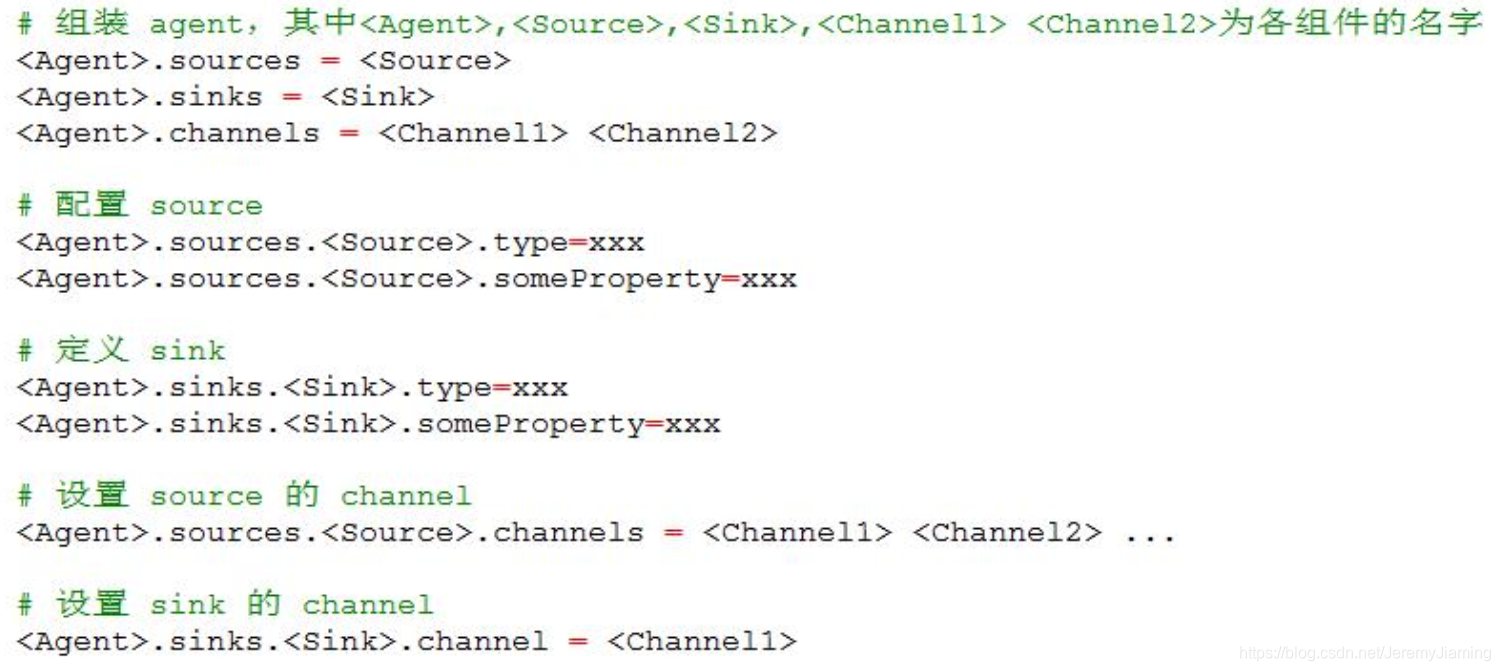
- 配置 agent: conf/flume-conf.properties
- 启动: $FLUME_HOME/bin/flume-ng agent -n a1 -c conf -f xxx.properties
配置模板
演示
具体的安装过程网上有很多,需要注意的是flume依赖的jdk为1.7及以上。但是如果linux的jdk版本不是1.7及以上也不必修改系统的jdk,只需再次安装jdk高版本后,在flume配置文件中指定jdk高版本路径即可。
接下来,通过一个小例子,测试一下。
效果:
flow从指定端口获得数据,存入channel,sink从channel中拉取数据,打印输出。
分析:
通过阅读官网document选取source、channel、sink的类型。
source选取netcat类型,其中加粗的属性为必填属性;channel选取memory类型;sink选取logger类型。
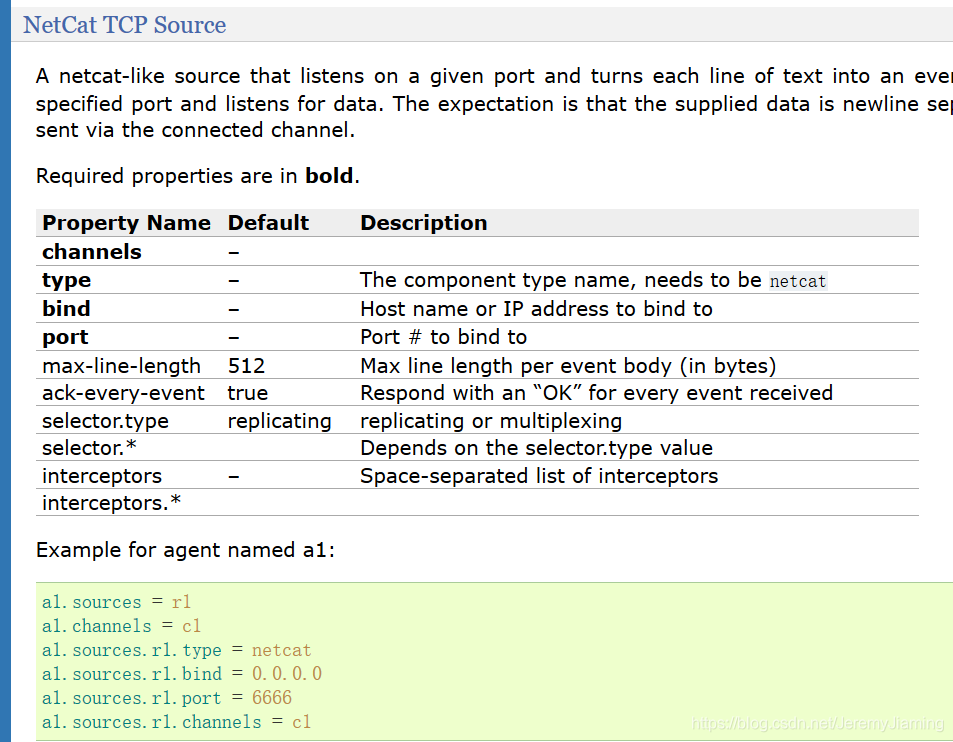 根据官网写出flume agent配置信息如下:
根据官网写出flume agent配置信息如下:
a1.sources = s1
a1.sinks = k1
a1.channels = c1
a1.sources.s1.type = netcat
a1.sources.s1.bind = localhost
a1.sources.s1.port = 6666
a1.sources.s1.channels = c1
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
运行flume:
执行如下代码,-Dflume.root.logger=DEBUG,console 为的是将日志信息输出在命令台。
flume-ng agent -n a1 -c ./ -f ./flume-sample-20190305.properties -Dflume.root.logger=DEBUG,console
运行效果:
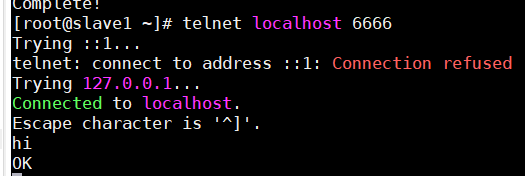
执行telnet,向端口号输出‘hi’后,控制台输出以下信息,证明flume运行成功。

工作原理解析
Flow类型
注意:一个source可以对应多个channel,而sink与channel通常是一对一的。
channel与sink一对一是因为:
- 假如一个channel对应多个sink,要考虑并发问题,会使得架构变得很复杂。
- 一个channel对应一个sink后,可以根据sink的目标源的需求急迫性,为各channel分配不同大小的内存。
顺序流
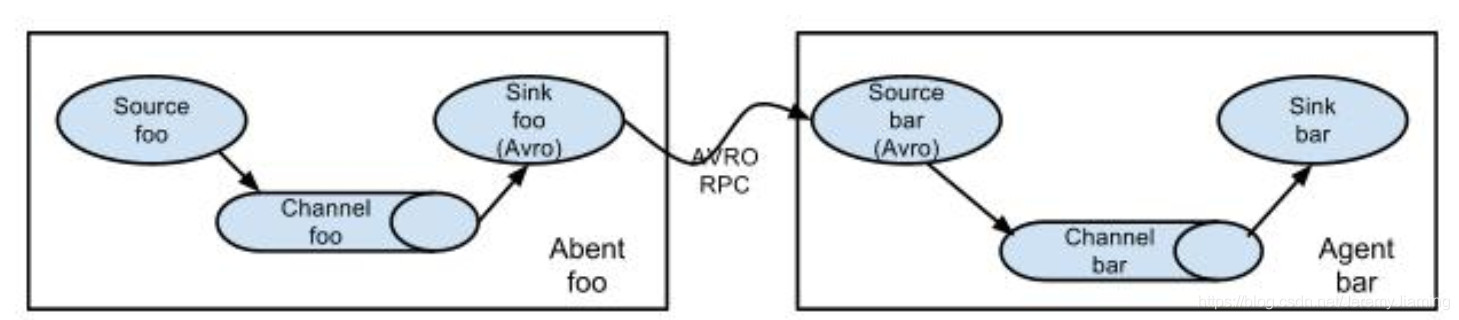
多对一聚合
一对多路由
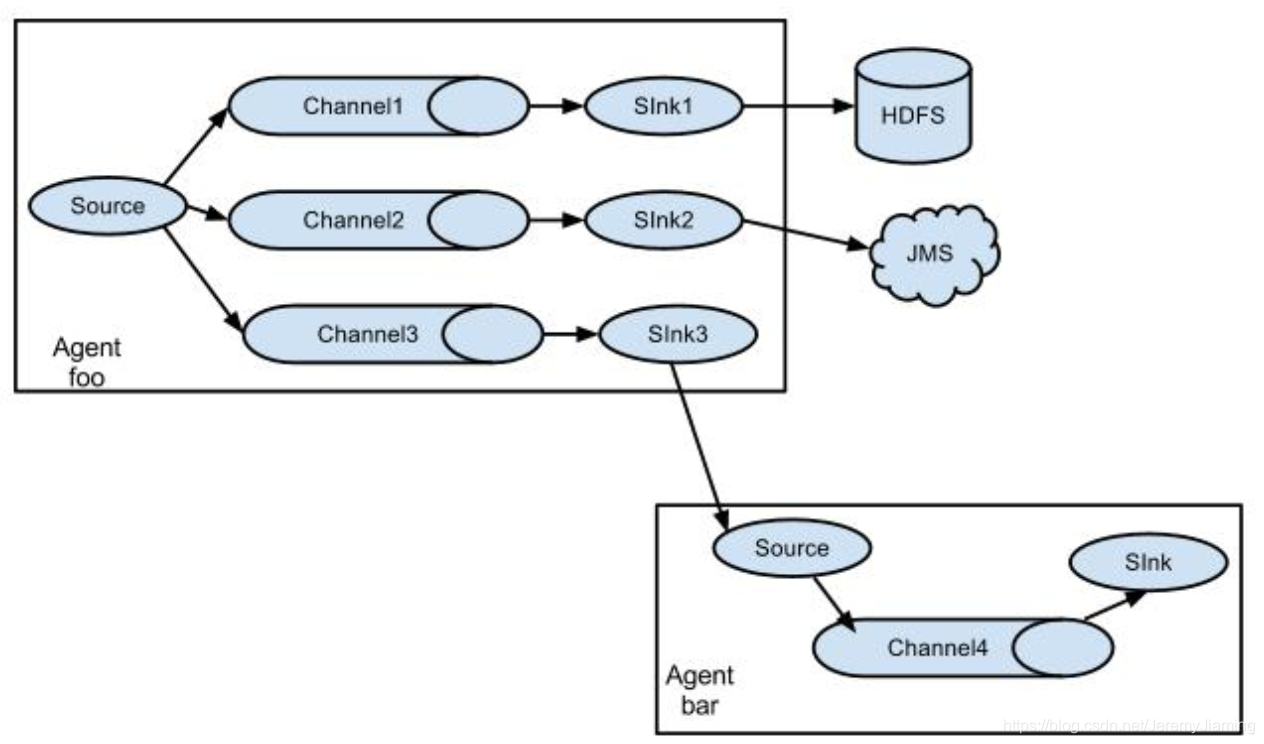
配置

负载均衡
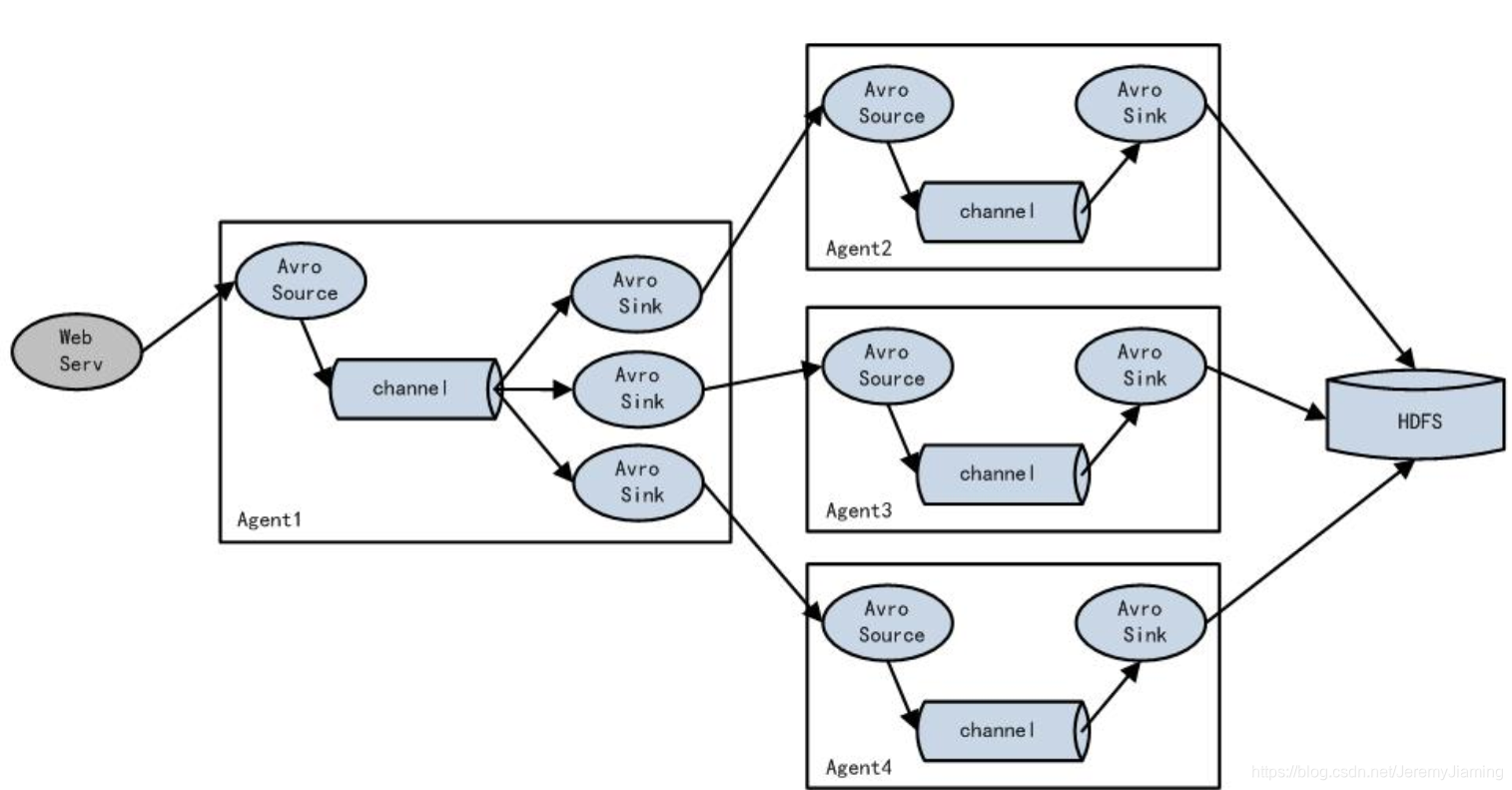 配置
配置

工作流程
- source开始接收消息
- 调用Channel Proccessor.processorEvent
- 调用Interceptor Chain做event的预处理
- 根据Channel Selector选择channel
- sink端调用Channel的take方法,获取event
上一张Flume源码类图,可以帮助大家分析Flume源码。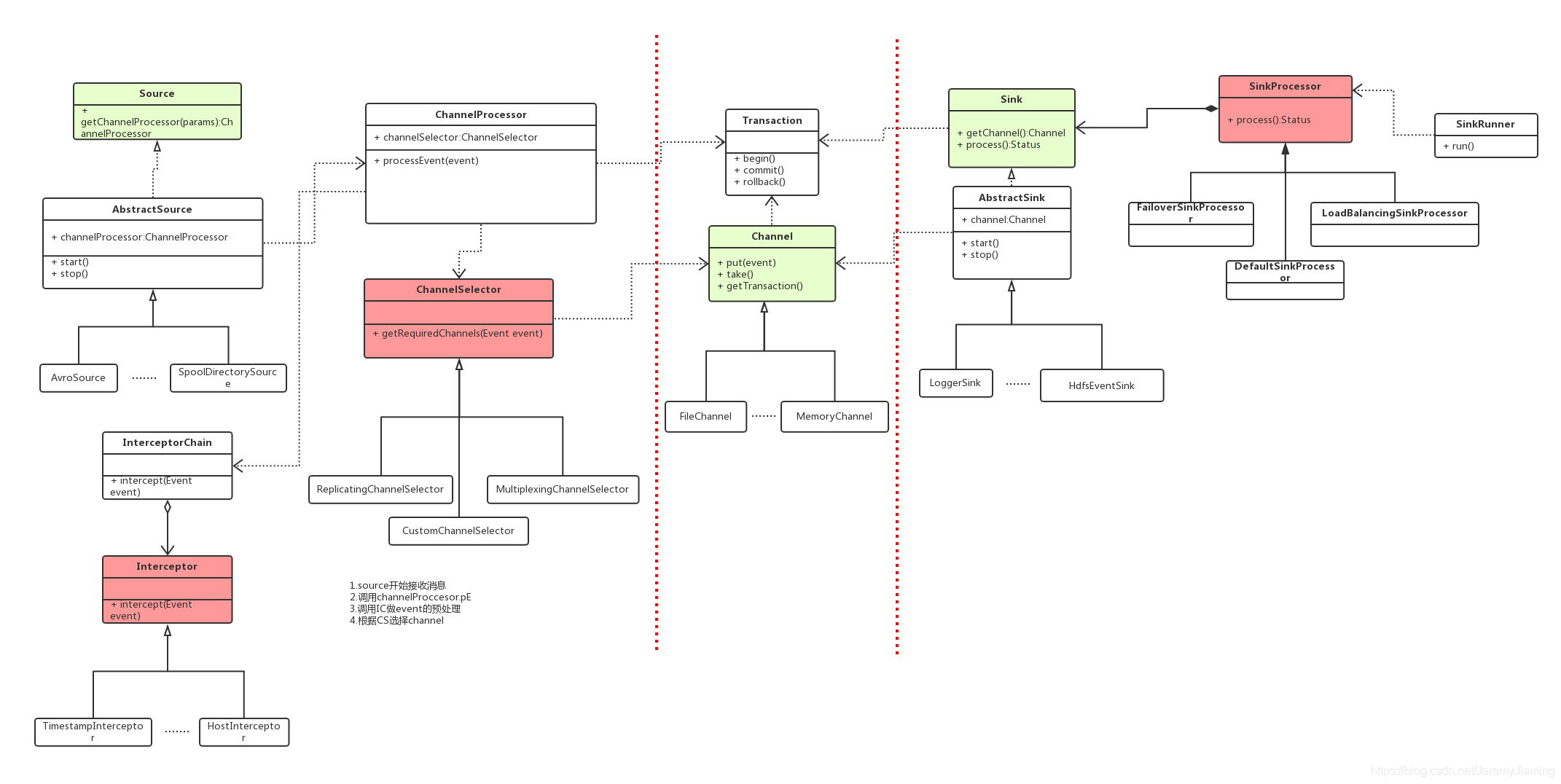
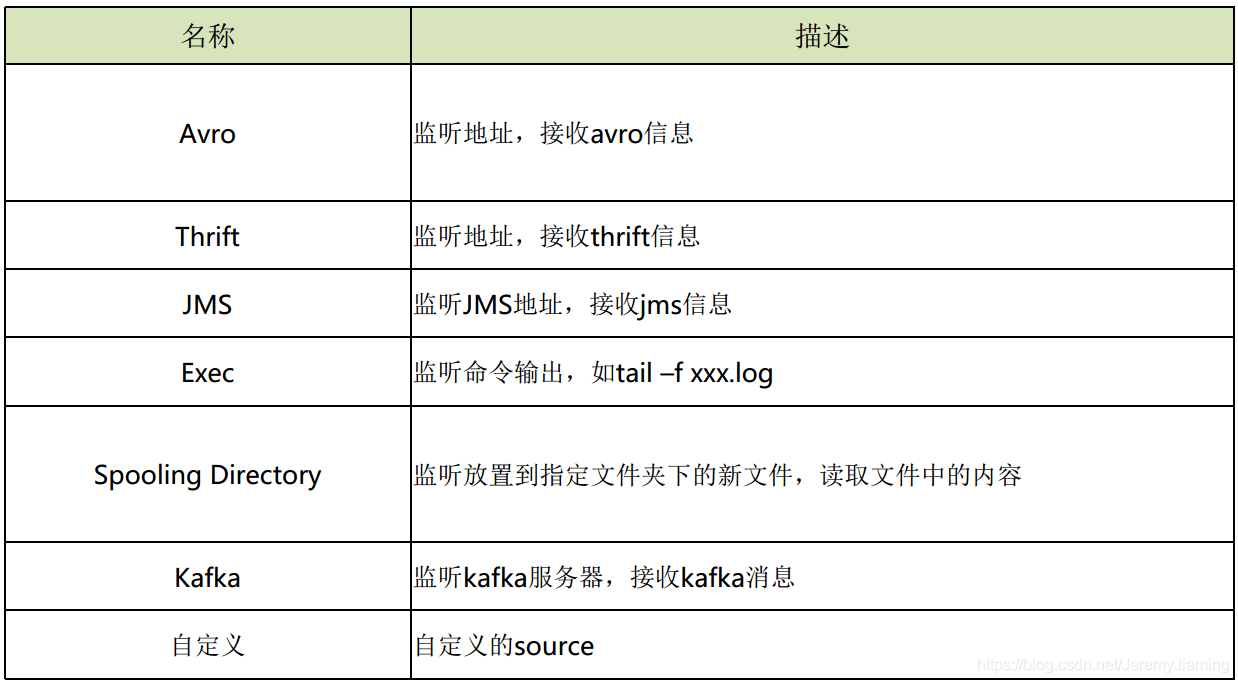
Source
Channel
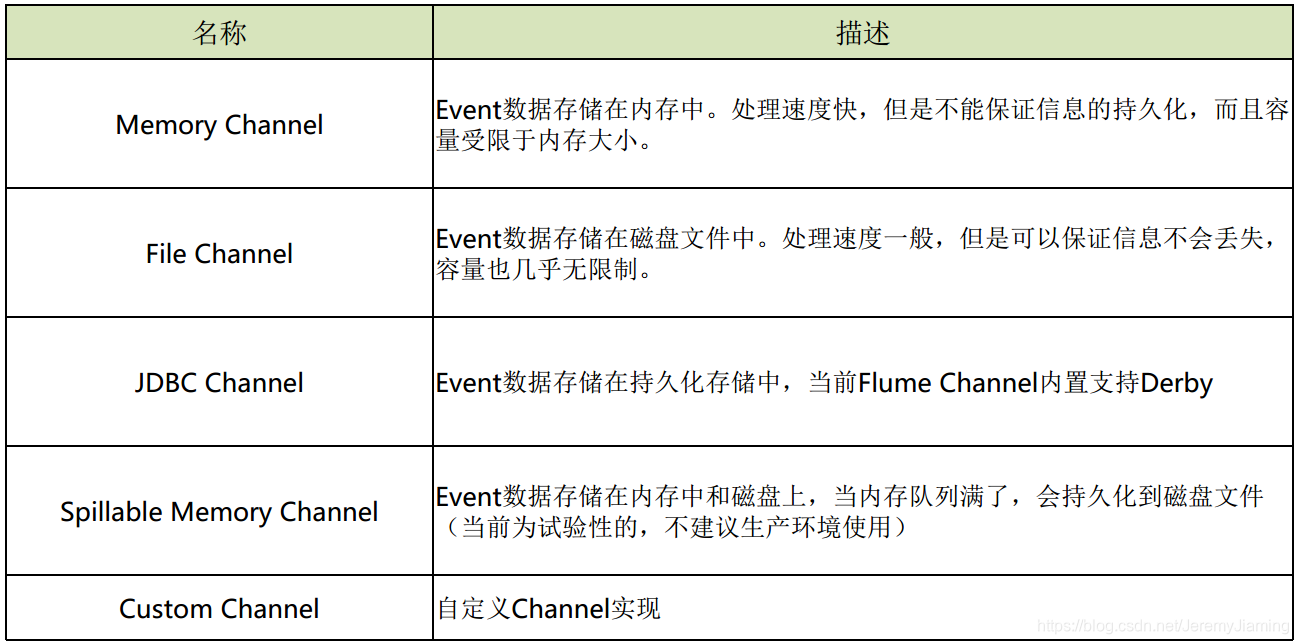
Sink
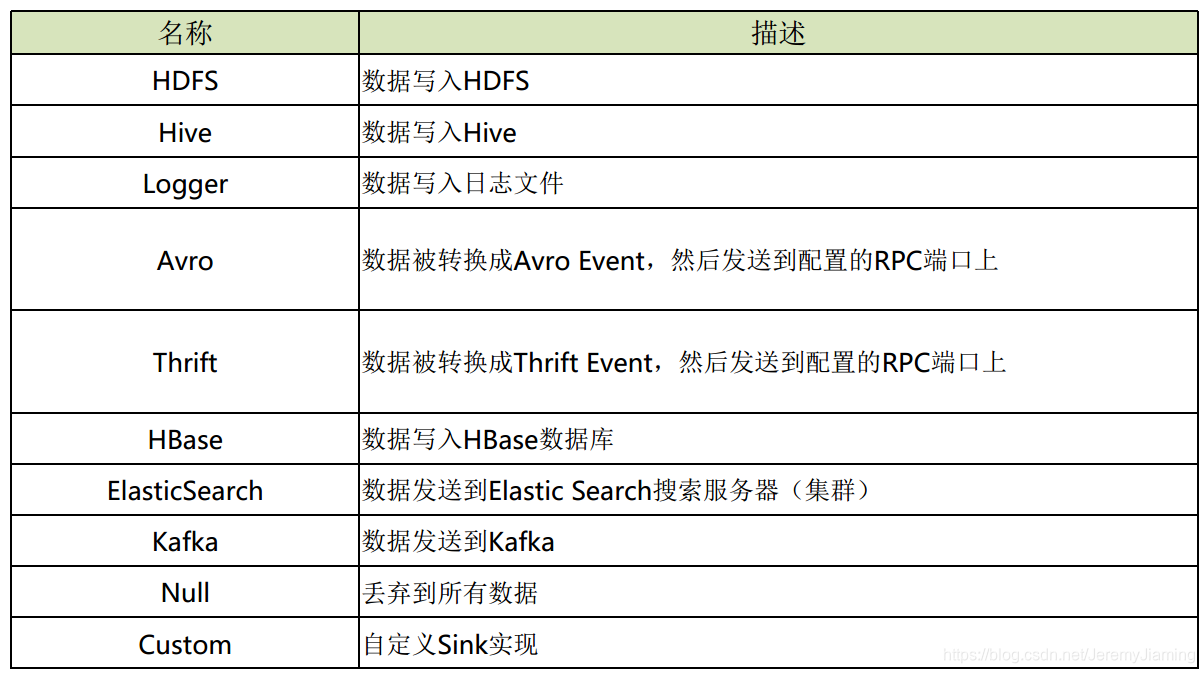
常见应用场景
场景一:离线日志收集
场景描述:
收集服务器的用户访问日志,保存到Hadoop集群总,用于离线的计算与分析。
Flume方案:
在服务器端配置flume agent, 其中:
- Source采用Spooling Directory Source
- Channel采用Memory Channel
- Sink采用HDFS Sink
场景二:实时日志收集
场景描述:
收集服务器的系统日志,发送给实时计算引擎进行实时处理。
Flume方案:
在服务器端配置flume agent, 其中:
- Source采用Spooling Directory Source或 Exec Source(tail –f xxx)
- Channel采用Memory Channel
- Sink采用Kafka Sink
场景三:系统日志收集
场景描述:
收集服务器的系统日志,保存到搜索引擎中,用于线上日志查询。
Flume方案:
在服务器端配置flume agent, 其中:
- Source采用Spooling Directory Source
- Channel采用File Channel
- Sink采用ElasticSearch Sink
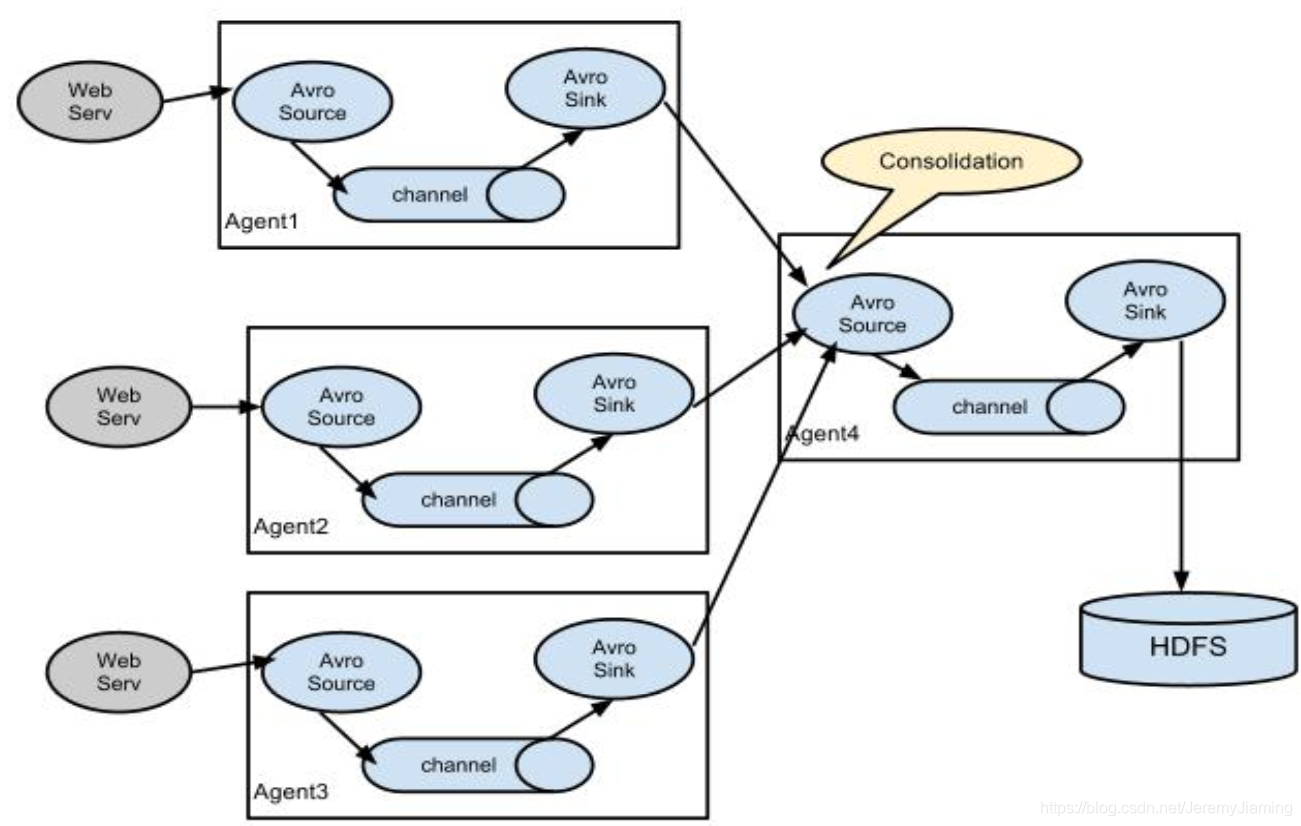
部署架构图
 架构图从左至右可分为三层:
架构图从左至右可分为三层:
采集层、汇总层、存储层。
中间汇总到Avro Source是因为:
- 当存储层(HDFS,ELK)做升级和维护时,如果没有中间层,势必会在Agent层出现数据的堆积,容易造成线上系统的紊乱。相比于日志的采集来说,线上应用的正常运转更为重要。
- 如果没有汇总层,路由就要配置到每一个Agent。实际生产中,Agent的节点数很可能上百,会给后期的路由维护带来很大麻烦。所以选择在汇总层统一配置路由信息。
实例演示
我的另一篇博文:《实践:Flume同步信息到HDFS》
https://blog.csdn.net/JeremyJiaming/article/details/88312656
日志采集系统的设计要求
- 系统可用性:采集系统自身的健壮性
- 可扩展性:可以随着应用系统的规模及数据量的增加而线性扩展
- 可靠性:不会丢失数据
- 灵活性:支持多种数据源;支持多种处理方式;支持多种采集目的地;支持对数据的预处理
其他方案
- Logstash(ELK)
- Scribe
- Chukwa
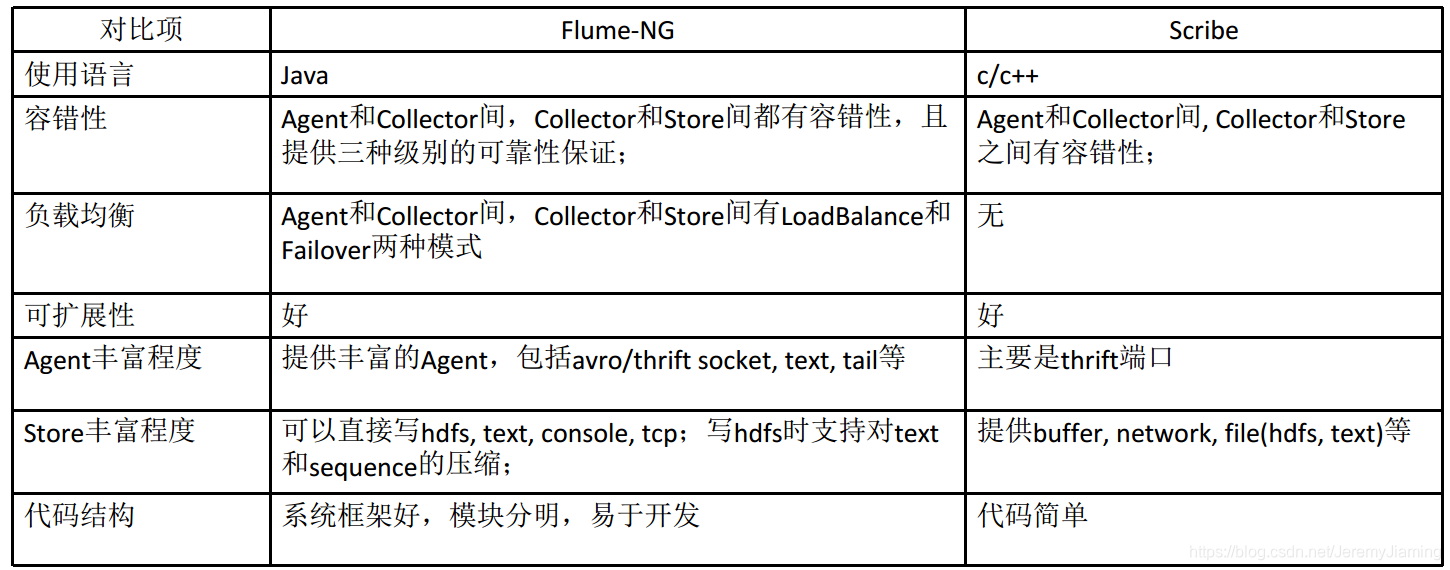
Flume与Scribe对比
Flume与Kafka
- flume是一个即插即用的数据收集组件,只需添加一些配置即可使用;更易使用
- kafka是一个高性能的分布式消息队列,需要自己编写生产端和消费段代码,扩展性和稳定性更好(支持高可用,并发)
经验分享
配置相关
- Agent的配置中使用统一的命名规则
- 在启动命令中添加“no-reload-conf”参数为true来取消自动加载配置文件功能
- 基于配置中心读取统一的配置文件
- 调大HdfsSink的batchSize, 增加吞吐量, 减少hdfs的flush次数
- 适当调大HdfsSink的callTimeout, 避免不必要的超时错误
架构相关
- 将 日志采集系统系统分成三层: 采集、 汇总和存储, 采集只管将数据发送 到汇总层, 处理逻辑由汇总层统一处理。 好处是简化采集点的管理
- 采集点(source)不要直接接入应用系统中, 以免由于日志收集系统问题影响应用系统
反思
- flume的组成部分有哪些?
- flume如何保证消息的可靠性?
- 有哪些日志收集的场景, 一般采用什么方案?
- 安装flume,部署flume agent, 实现如下场景:
- 将指定目录中不断增加的日志收集到hdfs中并测试大数据量下的收 集效率
- 由一个agent收集信息后发给第二个agent, 由第二个agent将信息写 入目的地
- 同一种source源, 同一种source源,根据信息的属性(比如IP地址) 将数据发送到不 同的channel