NLP进阶之(六)Word2Vec+FastText+Glove
1. WordEmbedding(seq2seq)
自上世纪90年代开始,特征空间模型就应用于分布式语言理解中,在当时,许多模型用连续型表征来表示词语,包括潜在语义分析(Latent Semantic Analysis)和潜在狄拉克雷分配(Latent Dirichlet Allocation)模型,这篇文章详细介绍了词向量方法在那个时期的发展。Bengio等人在2003年首先提出了词向量的概念,当时是将其余语言模型的参数一同训练得到。Collobert和Weston则第一次正式使用预训练的词向量。
词向量意义在于将语言数学化——词向量就是一种将自然语言数学化的方法。词向量方法是无监督式学习的少数几个成功应用之一。它的优势在于不需要人工标注语料,直接使用未标注的文本训练集作为输入。输出的词向量可以用于下游的业务处理。
一般来说,神经网络将词表中的词语作为输入,输出一个低维度的向量表示这个词语,然后用反向传播的方法不断优化参数,输出的低维向量是神经网络的第一层参数,这一层通常也称为Embedding Layer。
生成的词向量模型一般分为两种,一种是word2vec,这类模型的目的就是生成词向量,另一种模型是将词向量作为副产物产生,两者的区别在于计算量不同。若词表非常庞大,用深层结构模型训练词向量需要许多计算资源。这也是直到2013年词向量才开始被广泛用于NLP领域的原因。
1.1 Word2Vec
Word2Vec是词嵌入(word embedding)的一种,其中,Word2Vec提供了两套模型,第一种是Skip-gram,另一种是CBOW,其在语言数字化的过程中有以下几种变换:
- One-hot Encoding
- 分布式表示(Distributed Representation)
- 潜在语义分析(Latent Semantic Analysis, LSA)
- SVD分解
- 隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)
- 神经网络、深度学习
- 潜在语义分析(Latent Semantic Analysis, LSA)
1.2 Skip-gram和CBOW
- Skip-gram 是用一个词作为输入,来预测其周围的上下文
- CBOW是拿一个词的上下文作为输入,来预测这个词本身,是一个CBOW模型。
目前基于迭代的方法获取词向量大多是基于语言模型训练得到的,对于一个不合理的句子,希望语言模型能够给予一个较大的概率,同理,对于一个不合理的句子,给与一个较小的概率评估,具体的形式化如下:
第一个公式,一元语言模型,假设当前词的概率只与自己有关,第二个公式:二元语言模型,假设当前词的概率和当前一个词有关。因此我们可以从训练集的构建上更好的理解和区别CBOW和Skip-gram的模型。 - 每个训练样本为一个二元组 ,其中 为特征, 为标签
- 假设上下文窗口的大小
context_window =5,即: ,或者说skip_window=2,有context_window = skip_window*2 + 1 CBOW的训练样本为:Skip-gram的训练样本为:- 一般来说,
skip_window <= 10 - 除了两套模型,
Word2Vec还提供了两套优化方案,分别基于Hierarchical Softmax (层次SoftMax)和Negative Sampling (负采样)
1.2.1 基于层次Softmax的CBOW(Continuous Bag of Word Model)模型
CBOW是给一定上下文预测目标词的概率分布,例如,给定{The, cat, (), over, the, puddle}预测中心词是jumped的概率,模型的结构如下:

我们假设当前输入的权重参数矩阵为X,当前所有词所组成的字典为V,我们可以得到以下的更新公式:
对于CBOW模型来说,我们就是要实现概概率最大化的参数输出。
下面举这个例子:
- 【输入层】将
context(w)中的词映射为m维词向量,共2c个 - 【投影层】将输入层的
2c个词向量累加求和,得到新的m维词向量 - 【输出层】输出层对应一棵哈夫曼树,以词表中词作为叶子节点,各词的出现频率作为权重——共
N个叶子节点,N-1个非叶子节点。

- 对比
N-gram神经语言模型的网络结构- 【输入层】前者使用的是
w的前n-1个词,后者使用w两边的词(这是后者词向量的性能优于前者的主要原因) - 【投影层】前者通过拼接,后者通过累加求和
- 【隐藏层】后者无隐藏层
- 【输出层】前者为线性结构,后者为树形结构
- 【输入层】前者使用的是
- 模型改进
- 从对比中可以看出,CBOW 模型的主要改进都是为了减少计算量——取消隐藏层、使用层Softmax代替基本Softmax
【示例】N-gram模型迭代方法
隐层的激活函数其实是线性的,相当于没做任何处理,这也是Word2Vec简化之前语言模型的读到之处,我们要训练这个神经网络,用的是反向传播算法,本质上是链式求导,在此不展开说明。
当这个模型训练完成后,最后得到的其实是神经网络的权重,比如现在链式求导中输入的一个x的one-hot encoder为[1,0,0,…,0],对应于这个词语为吴彦祖,则在输入层到隐藏层的权重里,只有对应的1这个未知的权重被激活,这些权重的个数,跟隐藏层节点数是一致的,从而这些权重组成了一个向量
来表示
,因为每个词语的one-hot encoder里面1的位置是不同的,所以,这个向量
就可以用来唯一表示
。
然而,word2vec对这个模型进行了改进,首先,对于输入层到隐藏层的映射没有采取神经网络的线性变换加激活函数的方法,而是采用了简单的对所有输入词向量求和并取平均的方法,采用简单的对所有输入词向量求和并取平均的方法。比如输入的是三个4维词向量:(1,2,3,4),(9,6,11,8),(5,10,7,12),那么我们word2vec所映射后的词向量为(5,6,7,8)。前面两种都是使用这种向量和的方式。
1.2.1.1 层次 SoftMax 的正向传播
- 层次
Softmax实际上是把一个超大的多分类问题转化成一系列二分类问题 - 示例:求

从根节点到“足球”所在的叶子节点,需要经过 4 个分支,每次分支相当于一次二分类(逻辑斯蒂回归,二元Softmax)。
这里设0为正类,1为负类
而
就是每次分类正确的概率之积,即
这里每个非叶节点对应参数
1.2.1.2 为什么层次 SoftMax 能加速
- Softmax 大部分的计算量在于分母部分,它需要求出所有分量的和
- 而层次 SoftMax 每次只需要计算两个分量,因此极大的提升了速度
1.2.2 基于层次 Softmax 的 Skip-gram模型
- 这里保留了【投影层】,但实际上只是一个恒等变换

- 从模型的角度看:
CBOW与Skip-gram模型的区别仅在于 的构造方式不同,前者是context(w)的词向量累加;后者就是 的词向量 - 虽然
Skip-gram模型用中心词做特征,上下文词做类标,但实际上两者的地位是等价的
下图就是Skip-gram的网络结构,x就是上面所提到的one-hot encoder形式输入,y就是这个字典V个词上输出的概率,我们希望跟真实的y的one-hot encoder一样。

1.2.2.1 Skip-ngram模型更新
对于Skip-ngram模型也需要设定一个目标函数,随后采用优化方法来求得该模型的最佳参数解,目标函数如下:

目标函数用在
出现的情况下,上下文出现这些单词的概率,最后得到上面的公式进行梯度下降。
1.3 负采样
层次 Softmax还不够简单,于是提出了基于负采样的方法进一步提升性能- 负采样
(Negative Sampling)是NCE(Noise Contrastive Estimation)的简化版本 - CBOW 的训练样本是一个 二元对;对于给定的 , 就是它的正样本,而其他所有词都是负样本。
- 如果不使用负采样,即
N-gram神经语言模型中的做法,就是对整个词表Softmax和交叉熵 - 负采样相当于选取所有负例中的一部分作为负样本,从而减少计算量
Skip-gram模型同理
1.3.1 负采样算法
-
负采样算法,即对给定的
w,生成相应负样本的方法 -
最简单的方法是随机采样,但这会产生一点问题,词表中的词出现频率并不相同
- 如果不是从词表中采样,而是从语料中采样;显然,那些高频词被选为负样本的概率要大于低频词
- 在词表中采样时也应该遵循这个
-
因此,负采样算法实际上就是一个带权采样过程

以下是其相对应的描述
我们来进行负采样,得到neg个负例。词汇表的大小为V那么我们就将一段长度为1的线段分为V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段唱,低频词对应的线段短(根据词频采样,出现的次数越多,负采样的概率越大)。每个词 的线段长度由下式所决定: -
采样前,我们将这段长度为1的线段划分成 等份,这里
M>>V,这能够保证每个词对应的线段都会划分成对应的小块,而 份中每一份会落在某一个词对应的线段上(如下图),对应的未知就是采样的负例词。
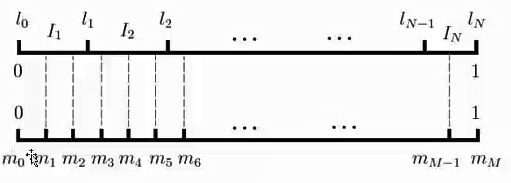
先对这个L进行均等分, 代表的是每个单词,那么每个单词就不应该是均等的,故 , 都应该是不均等的,那么投影到下面区间是不一样的,虚线条数是不均等的。那么怎么进行带权重的负采样呢,这里频率比较高的词就会被更高的采样 -
采样时,每次生成一个 之间的整数 ,则 就对应一个样本;当采样到正例时,跳过(拒绝采样)。
-
特别的,
Word2Vec在计算len(w)时做了一些改动——为count(·)加了一个指数
1.3.1.1 低频词的处理
- 对于低频词,会设置阈值(默认为5),对于出现频次低于该阈值的词会直接舍弃,同时训练集中也会被删除
1.3.1.2 高频词的处理
- 高频词提供的信息相对较少,为了提高低频词的词向量质量,有必要对高频词进行限制
- 高频词对应的词向量在训练时,不会发生明显的变化,因此在训练是可以减少对这些词的训练,从而提升速度
- Sub-sampling技巧
- 源码中使用 Sub-sampling 技巧来解决高频词的问题,能带来 2~10 倍的训练速度提升,同时提高低频词的词向量精度
- 给定一个词频阈值
,将
以
的概率舍弃,
的计算如下

- Word2Vec中的Sub-sampling
- 显然,Sub-Sampling 只会针对 出现频次大于 的词
- 特别的,Word2Vec 使用如下公式计算
,效果是类似的
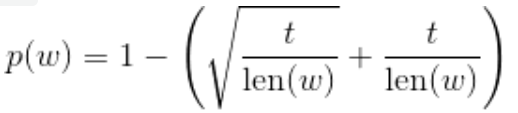
1.3.1.2 自适应学习率
- 预先设置一个初始的学习率 (默认 0.025),每处理完 (默认 10000)个词,就根据以下公式调整学习率
- 随着训练的进行,学习率会主键减小,并趋向于 0
- 为了方式学习率过小,Word2Vec 设置了一个阈值 (默认 0.0001 * );当学习率小于 ,则固定为 。
参数初始化
- 词向量服从均匀分布
[-0.5/m, 0.5/m],其中 为词向量的维度 - 所有网络参数初始化为
0
2. FastText
FastText是从Word2Vec的CBOW模型演化而来的;- 从网络的角度来看,两者的模型基本一致;区别仅在于两者的输入和目标函数不同;

FastText与CBOW的相同点:- 包含三层:输入层、隐含层、输出层(Hierarchical Softmax)
- 输入都是多个单词的词向量
- 隐藏层(投影层)都是对多个词向量的叠加平均
- 输出都是一个特定的 target
- 从网络的角度看,两者基本一致
2.1 FastText与Word2Vec的区别
- CBOW 的输入是中心词两侧
skip_window内的上下文词;FastText 除了上下文词外,还包括这些词的字符级N-gram特征 - 注意,字符级N-gram只限制在单个词内,以英文为例
// 源码中计算 n-grams 的声明,只计算单个词的字符级 n-gram
compute_ngrams(word, unsigned int min_n, unsigned int max_n);
# > https://github.com/vrasneur/pyfasttext#get-the-subwords
>>> model.args.get('minn'), model.args.get('maxn')
(2, 4)
# 调用源码的 Python 接口,源码上也会添加 '<' 和 '>'
>>> model.get_all_subwords('hello') # word + subwords from 2 to 4 characters
['hello', '<h', '<he', '<hel', 'he', 'hel', 'hell', 'el', 'ell', 'ello', 'll', 'llo', 'llo>', 'lo', 'lo>', 'o>']
>>> # model.get_all_subwords('hello world') # warning
- 值得一提的是,因为 FastText 使用了字符级的
N-gram向量作为额外的特征,使其能够对未登录词也能输出相应的词向量; - 具体来说,未登录词的词向量等于其
N-gram向量的叠加
2.2 gensim.models.FastText使用示例
- 构建
FastText以及获取词向量
# gensim 示例
import gensim
import numpy as np
from gensim.test.utils import common_texts
from gensim.models.keyedvectors import FastTextKeyedVectors
from gensim.models._utils_any2vec import compute_ngrams, ft_hash
from gensim.models import FastText
# 构建 FastText 模型
sentences = [["Hello", "World", "!"], ["I", "am", "huay", "."]]
min_ngrams, max_ngrams = 2, 4 # ngrams 范围
model = FastText(sentences, size=5, min_count=1, min_n=min_ngrams, max_n=max_ngrams)
# 可以通过相同的方式获取每个单词以及任一个 n-gram 的向量
print(model.wv['hello'])
print(model.wv['<h'])
"""
[-0.03481839 0.00606661 0.02581969 0.00188777 0.0325358 ]
[ 0.04481247 -0.1784363 -0.03192253 0.07162753 0.16744071]
"""
print()
# 词向量和 n-gram 向量是分开存储的
print(len(model.wv.vectors)) # 7
print(len(model.wv.vectors_ngrams)) # 57
# gensim 好像没有提供直接获取所有 ngrams tokens 的方法
print(model.wv.vocab.keys())
"""
['Hello', 'World', '!', 'I', 'am', 'huay', '.']
"""
print()
2.3 获取单个词的ngrams表示
- 利用源码中
compute_ngrams方法,gensim提供了该方法的Python接口
sum_ngrams = 0
for s in sentences:
for w in s:
w = w.lower()
# from gensim.models._utils_any2vec import compute_ngrams
ret = compute_ngrams(w, min_ngrams, max_ngrams)
print(ret)
sum_ngrams += len(ret)
"""
['<h', 'he', 'el', 'll', 'lo', 'o>', '<he', 'hel', 'ell', 'llo', 'lo>', '<hel', 'hell', 'ello', 'llo>']
['<w', 'wo', 'or', 'rl', 'ld', 'd>', '<wo', 'wor', 'orl', 'rld', 'ld>', '<wor', 'worl', 'orld', 'rld>']
['<!', '!>', '<!>']
['<i', 'i>', '<i>']
['<a', 'am', 'm>', '<am', 'am>', '<am>']
['<h', 'hu', 'ua', 'ay', 'y>', '<hu', 'hua', 'uay', 'ay>', '<hua', 'huay', 'uay>']
['<.', '.>', '<.>']
"""
assert sum_ngrams == len(model.wv.vectors_ngrams)
print(sum_ngrams) # 57
print()
2.4 计算一个未登录词的词向量
- 未登录词实际上是已知
n-grams向量的叠加平均
# 因为 "a", "aa", "aaa" 中都只含有 "<a" ,所以它们实际上都是 "<a"
print(model.wv["a"])
print(model.wv["aa"])
print(model.wv["aaa"])
print(model.wv["<a"])
"""
[ 0.00226487 -0.19139008 0.17918809 0.13084619 -0.1939924 ]
[ 0.00226487 -0.19139008 0.17918809 0.13084619 -0.1939924 ]
[ 0.00226487 -0.19139008 0.17918809 0.13084619 -0.1939924 ]
[ 0.00226487 -0.19139008 0.17918809 0.13084619 -0.1939924 ]
"""
print()
- 只要未登录词能被已知的 n-grams 组合,就能得到该词的词向量
word_unk = "aam"
ngrams = compute_ngrams(word_unk, min_ngrams, max_ngrams) # min_ngrams, max_ngrams = 2, 4
word_vec = np.zeros(model.vector_size, dtype=np.float32)
ngrams_found = 0
for ngram in ngrams:
ngram_hash = ft_hash(ngram) % model.bucket
if ngram_hash in model.wv.hash2index:
word_vec += model.wv.vectors_ngrams[model.wv.hash2index[ngram_hash]]
ngrams_found += 1
if word_vec.any(): #
word_vec = word_vec / max(1, ngrams_found)
else: # 如果一个 ngram 都没找到,gensim 会报错;个人认为把 0 向量传出来也可以
raise KeyError('all ngrams for word %s absent from model' % word_unk)
print(word_vec)
print(model.wv["aam"])
"""
[ 0.02210762 -0.10488641 0.05512805 0.09150169 0.00725085]
[ 0.02210762 -0.10488641 0.05512805 0.09150169 0.00725085]
"""
# 如果一个 ngram 都没找到,gensim 会报错
# 其实可以返回一个 0 向量的,它内部实际上是从一个 0 向量开始累加的;
# 但返回时做了一个判断——如果依然是 0 向量,则报错
# print(model.wv['z'])
"""
Traceback (most recent call last):
File "D:/OneDrive/workspace/github/DL-Notes-for-Interview/code/工具库 /gensim/FastText.py", line 53, in <module>
print(model.wv['z'])
File "D:\program\work\Python\Anaconda3\envs\tf\lib\site-packages\gensim\models \keyedvectors.py", line 336, in __getitem__
return self.get_vector(entities)
File "D:\program\work\Python\Anaconda3\envs\tf\lib\site-packages\gensim\models \keyedvectors.py", line 454, in get_vector
return self.word_vec(word)
File "D:\program\work\Python\Anaconda3\envs\tf\lib\site-packages\gensim\models \keyedvectors.py", line 1989, in word_vec
raise KeyError('all ngrams for word %s absent from model' % word)
KeyError: 'all ngrams for word z absent from model'
"""
3. Glove
3.1 Glove与Word2Vec的区别
4. 其他实践
一般 embedding 维度的选择
- 经验公式
embedding_size = n_categories ** 0.25 - 在大型语料上训练的词向量维度通常会设置的更大一些,比如
100~300
5. 小结
- 我们可以在解码器的每个时间步使用不同的背景变量,并对输入序列中不同时间步编码的信息分配不同的注意力。
- 广义上,注意力机制模型的输入包括查询项以及一一对应的键项和值项。
- 注意力机制可以采用更为高效的矢量化计算。
5.1 参考链接
[1]: Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.