简介:
假期自学了elasticsearch搭建与使用,写个博客记录一下
另外我电脑是linux,我懒得再说windows各种配置方法了,不过都是大同小异
1.软件的简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2.软件的下载与安装
(1).下载与安装 elasticsearch-rtf
可以到github去clone下载,不过我下载的是elasticsearch-rtf 版本,因为相对于原版,这个版本集成了一些中文插件,方便我们使用,不用再下载额外的插件了
下载地址:点我
根据readme说明,在终端上输入
git clone git://github.com/medcl/elasticsearch-rtf.git -b master --depth 1
就能下载了,这个当然前提是需要下载git了,我就不具体讲怎么下载和安装git了,这些都是基础
另外这是一个java项目 需要下载 jdk 而且需要jdk8的版本 这里是大于等于8,关于怎么下载及配置jdk也是自己百度吧,然后进行下一步
然后 进入 项目目录/bin/ 执行elasticsearch 这个脚本文件, 可以这样执行./elasticsearch
不出意外的话会报错(如果你没有报错,并且正常运行了可以跳过下面说明)
报错解决
1.中文路径的问题,当时也是坑了我很久,这个项目不要放在中文路径下
2.版本问题需要下载一个较新版本的然后替换对应的jar包中的 class类,具体说明请看这里
当然你要是看不懂的话,可以直接下载我打包好替换完的jar包,点这里(注意这里是5.1.1版本的)
直接替换 lib目录下的 elasticsearch-5.1.1.jar 包就可以了。
然后启动
正常在浏览器打开网址 http://127.0.0.1:9200/ 显示
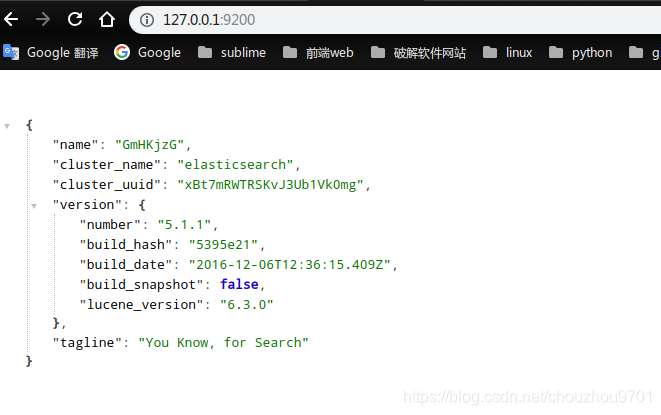
启动成功!
(2).下载与安装 kibana
kibana现在对于我来说就是测试 RESTful web 接口的,或许其他一写功能我还没用到。注意一个问题就是下载 的版本要与我们的 elasticsearch-rtf 一致,这样会少很多错误,下载地址 这里
第一个组合框选择 kibana 第二个选择对应elasticsearch-rtf的版本
进入 项目目录\bin 运行./kibana
就能启动kibana了
在浏览器中打开 http://localhost:5601/ 查看kibana
(3).下载与安装 elasticsearch-head
我对 elasticsearch-head 的理解是,相当于 mysql 的navicat ,一个数据库的管理吧,也是web端的,或许说像phpmyadmin 更合适,只不过 elasticsearch 用的是自己的一个数据存储集合
下载地址 这里
下载完成后你需要 安装node 在 linux 上
sudo apt-get install npm
就可以下载node了,这条命令会自动下载 npm 也就是node的包管理,也会下载node,另外关于npm换淘宝源的什么,就直接百度吧,然后进入 kibana 的项目目录
npm install
npm run start
具体可看其 github 上的readme 文件说明
启动成功后可以 在浏览器打开 http://localhost:9100
查看运行状态,集群显示未连接(这里是elasticsearch对于安全的考虑,不允许连接)
所以这里我们要修改一下 elasticsearch-rtf 的配置文件 在 项目目录\config\elasticsearch.yml 这个文件
在文件结尾写入以下内容
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: "X-Requested-With, Content-Type, Content-Length, X-User"
写入完成后,重新启动 elasticsearch-rtf 然后 看 elasticsearch-head 状态连接成功了
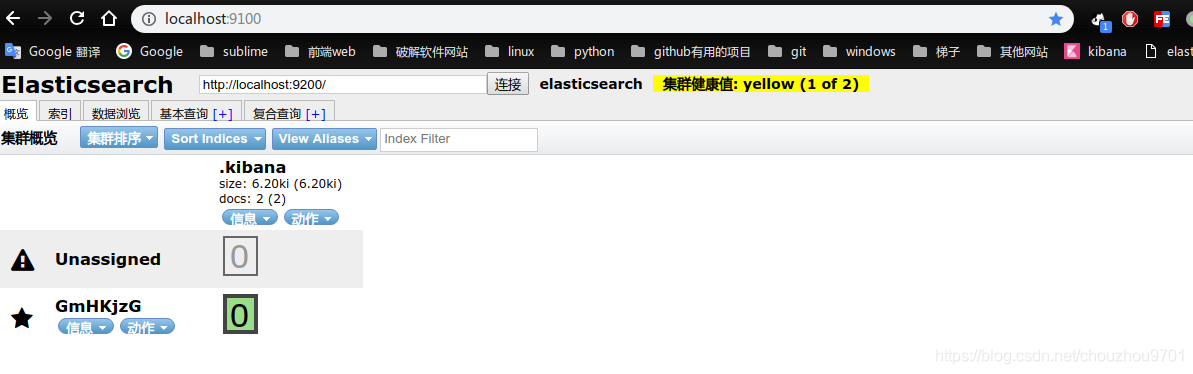
这里有一个 .kibana 的索引 我们不用管它,这个是kibana生成的
至此环境全部配置完成!!
3.RESTful web接口的测试
这个一小节可以说是内容最多的了,也是最重要的,如果你想熟练的使用elasticsearch,那么语法有很多需要去记忆
先说一下大致的测试流程
[在 kibana 写测试接口的语句] -----> [在elasticsearch-head中查看效果]
当然其实在kibana中也可以看到返回的结果,只是没有 elasticsearch-head 中的直观
(1)elasticsearch数据库基础概念
在插入数据前我们需要先理解几个概念方便后面进行
1.1 集群:一个或者多个节点组织在一起
多个服务器集成到一起
1.2 节点:一个节点是集群中的一个服务器,由一个名字来标识,默认是一个随机的漫画角色名字(漫威)
1.3 分片:将索引划分为多分的能力,允许水平分割和扩展容量,多个分片响应请求,提高性能和吞吐量
注:索引相当于关系数据库中的数据库
数据量大的时候,将一个索引分到多个服务器来响应请求
1.4 副本:创建分片的一份或多份的能力,在一个节点失败其余节点可以顶上
相当于数据的备份,防止其中一个节点上数据响应不到,将同一个数据分布到多个服务器上
1.5 elasticsearch与mysql关系型数据库的类比
| elasticsearch | mysql |
|---|---|
| index(索引) | 数据库 |
| type(类型) | 表 |
| documents(文档) | 行 |
| fields | 列 |
1.6 倒排索引:由属性值来确定记录的位置
举个例子:
| 文章 | 内容 |
|---|---|
| 文章A | 好好学习python |
| 文章B | 学习django |
| 文章C | 学习python和django |
在文章插入之前进行分析分词
| 关键词 | 出现的关键词的文章 |
|---|---|
| python | 文章A,文章C |
| django | 文章B |
| 学习 | 文章A,文章B,文章C |
(2)测试第一个接口
首先启动 kibana 这个软件
然后进入这个界面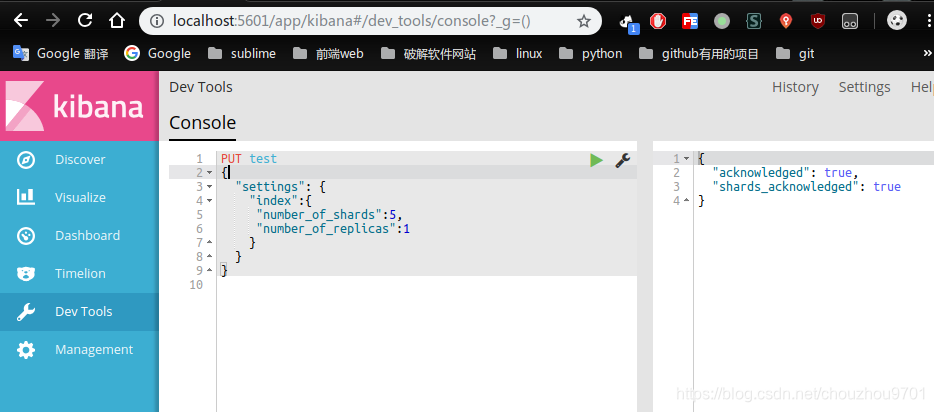
在这个界面输入
PUT test
{
"settings": {
"index":{
"number_of_shards":5,
"number_of_replicas":1
}
}
}
然后执行这句话,返回的响应是一个json格式的内容
{
"acknowledged": true,
"shards_acknowledged": true
}
说明成功
简单解释一下提交数据这几个值的意思
这个语句是新建一个索引(数据库)
number_of_shards是分片的数量
number_of_replicas是副本的数量
这两个概念前面已经介绍了,通过上面这条语句就新建好了一个索引,然后可以在 elasticsearch-head 中看到这个数据库的信息
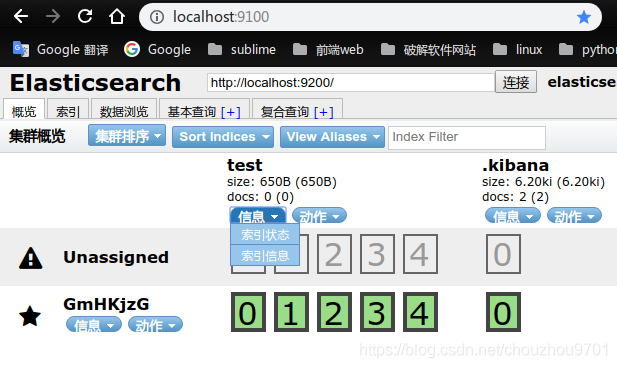
可以在 信息 里面查看这个数据库的状态及信息,也可以在 动作 里面进行删除这个索引
下面这些 是一些有用的查询索引的信息 可以输入 试试有什么不同
GET test/_settings
GET _all/_settings
GET .kibana,test/_settings
GET _settings
(3)对已经存在的索引进行结构上的修改
PUT lagou/_settings
{
"number_of_replicas":1
}
执行后我们可以看到返回响应成功,说明修改副本成功
但是如果你想修改切片数量的话就会失败,如果想修改切片那就只能删除索引然后重新建立了
持续更新中。。。。