自己分析的第一个数据挖掘项目
首先导入数据
- 导入相应的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
- 导入数据
data = pd.read_csv("C:/Users/97185/Desktop/test/data.csv")
data.head()
data.shape
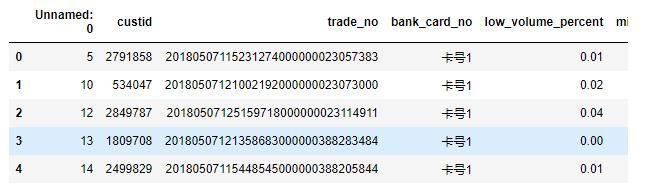
(4754, 90)
- 查看目标变量及特征类型的查看
data['status'].value_counts()
0 3561
1 1193
Name: status, dtype: int64
data['status'].astype(int).plot.hist()

data.dtypes.value_counts()
float64 70
int64 13
object 7
dtype: int64
data.select_dtypes('object').apply(pd.Series.nunique, axis=0)
trade_no 4754
bank_card_no 1
reg_preference_for_trad 5
source 1
id_name 4309
latest_query_time 207
loans_latest_time 232
dtype: int64
- 删除无关变量
data = data.drop(['loans_latest_time', 'latest_query_time'], axis=1)
data = data.drop(['trade_no', 'bank_card_no', 'source'], axis=1)
data = data.drop(['custid'], axis=1)
data.shape
data.head()
5. 检查缺失值
# Function to calculate missing values by column# Funct
def missing_values_table(df):
# Total missing values
mis_val = df.isnull().sum()
# Percentage of missing values
mis_val_percent = 100 * df.isnull().sum() / len(df)
# Make a table with the results
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# Rename the columns
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
# Sort the table by percentage of missing descending
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
# Print some summary information
print ("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
# Return the dataframe with missing information
return mis_val_table_ren_columns
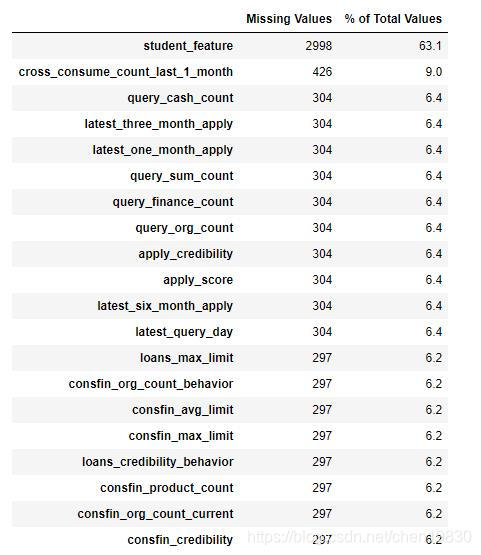
missing_values = missing_values_table(data)
missing_values.head(20)
Your selected dataframe has 84 columns.
There are 72 columns that have missing values.
f, ax = plt.subplots(figsize=(12, 9))
sns.barplot(x=missing_values.index, y=missing_values['Missing Values'])
plt.ylabel('Features', fontsize=15)
plt.xlabel('Percent of missing values', fontsize=15)
plt.title('percent missing data by feature', fontsize=15)
plt.xticks(rotation=90)

data['student_feature'].describe()
count 1756.000000
mean 1.001139
std 0.033739
min 1.000000
25% 1.000000
50% 1.000000
75% 1.000000
max 2.000000
Name: student_feature, dtype: float64
data['student_feature'] = data['student_feature'].fillna(1)
data['cross_consume_count_last_1_month'].describe()
count 4328.000000
mean 0.642329
std 2.343228
min 0.000000
25% 0.000000
50% 0.000000
75% 1.000000
max 69.000000
Name: cross_consume_count_last_1_month, dtype: float64
data['cross_consume_count_last_1_month'] = data['cross_consume_count_last_1_month'].fillna(data['cross_consume_count_last_1_month'].mean())
data['query_cash_count'].describe()
count 4450.000000
mean 3.784719
std 2.599244
min 0.000000
25% 2.000000
50% 3.000000
75% 5.000000
max 16.000000
Name: query_cash_count, dtype: float64
data['query_cash_count'] = data['query_cash_count'].fillna(lambda x: x.fillna(x.mode()[0]))
cols = ['latest_six_month_apply', 'latest_one_month_apply', 'query_sum_count', 'query_sum_count', 'query_finance_count', 'query_org_count']
for col in cols:
data[col] = data[col].fillna(data[col].mean())
cols = missing_values.index
for col in cols:
data[col] = data[col].fillna(data[col].mean())
missing_values = missing_values_table(data)
missing_values.head()
Your selected dataframe has 4396 columns.
There are 0 columns that have missing values.
data_label = data['status']
data = data.drop(['status'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(data, data_label, test_size=.3, random_state=2018)
print("Training Size:{}".format(X_train.shape))
print('Testing Size:{}'.format(X_test.shape))
Training Size:(3327, 4395)
Testing Size:(1427, 4395)