开什么玩笑,没有大量的数据,人工智能就是人工智障,
里面涉及的东西较多,初学者可以调用百度的接口,免费的
抱歉做了一次标题党

借助百度AI识别语音
先申请百度的ai的使用账号,注意勾选的项目的类型
百度AI开放平台-全球领先的人工智能服务平台-百度AI开放平台
http://ai.baidu.com/
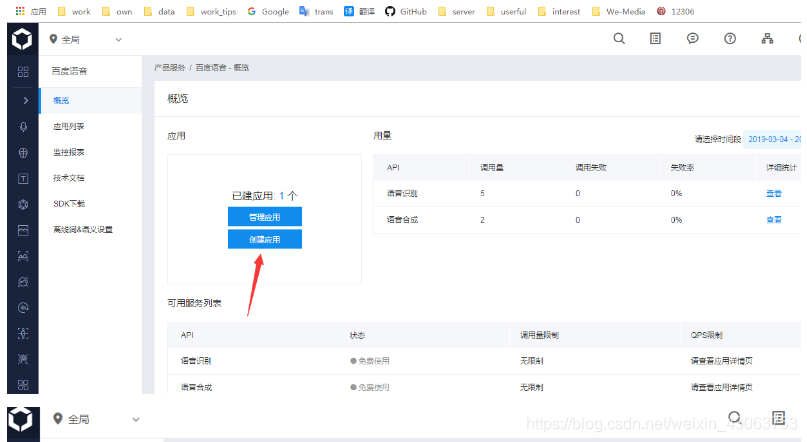
点击创建应用
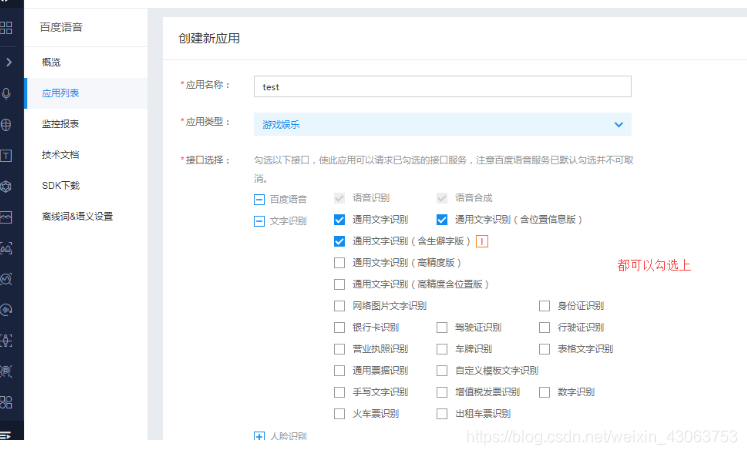
有一些需要填写设备的,就不用勾选了,目前还用不到
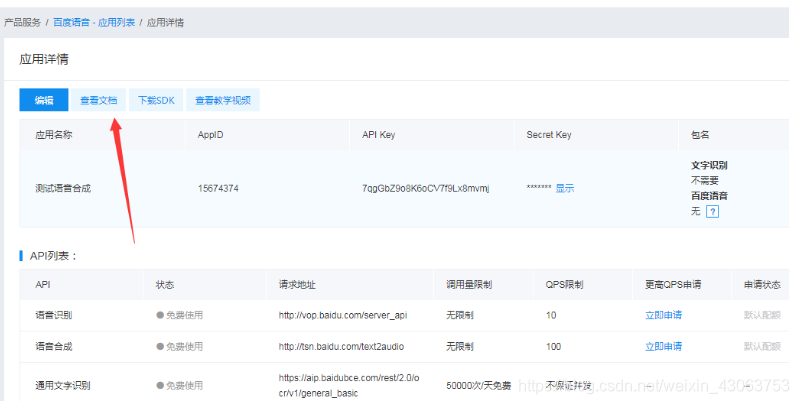
秘钥在这里
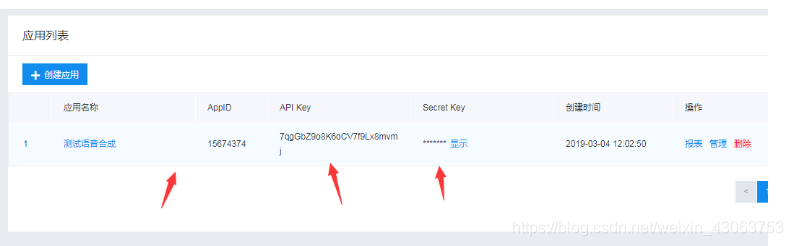
进入应用详情
支持Python版本:2.7.+ ,3.+
安装使用Python SDK有如下方式:
- 如果已安装pip,执行pip install baidu-aip即可。
- 如果已安装setuptools,执行python setup.py install即可。
新建AipSpeech
AipSpeech是语音合成的Python SDK客户端,为使用语音合成的开发人员提供了一系列的交互方法。
参考如下代码新建一个AipSpeech:
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
在上面代码中,常量APP_ID在百度云控制台中创建,常量API_KEY与SECRET_KEY是在创建完毕应用后,系统分配给用户的,均为字符串,用于标识用户,为访问做签名验证,可在AI服务控制台中的应用列表中查看。
配置AipSpeech
如果用户需要配置AipSpeech的网络请求参数(一般不需要配置),可以在构造AipSpeech之后调用接口设置参数,目前只支持以下参数:
接口 说明
setConnectionTimeoutInMillis 建立连接的超时时间(单位:毫秒
setSocketTimeoutInMillis 通过打开的连接传输数据的超时时间(单位:毫秒)
接口说明
语音合成
接口描述
基于该接口,开发者可以轻松的获取语音合成能力
请求说明
- 合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。文本长度不可超过限制
举例,要把一段文字合成为语音文件:
result = client.synthesis('你好百度', 'zh', 1, {
'vol': 5,
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('auido.mp3', 'wb') as f:
f.write(result)
参数 类型 描述 是否必须
tex String 合成的文本,使用UTF-8编码, 请注意文本长度必须小于1024字节 是
cuid String 用户唯一标识,用来区分用户, 填写机器 MAC 地址或 IMEI 码,长度为60以内 否
spd String 语速,取值0-9,默认为5中语速 否
pit String 音调,取值0-9,默认为5中语调 否
vol String 音量,取值0-15,默认为5中音量 否
per String 发音人选择, 0为女声,1为男声, 3为情感合成-度逍遥,4为情感合成-度丫丫,默认为普通女 否
返回样例:
// 成功返回二进制文件流
// 失败返回
{
"err_no":500,
"err_msg":"notsupport.",
"sn":"abcdefgh",
"idx":1
}
错误信息
错误返回格式
若请求错误,服务器将返回的JSON文本包含以下参数:
- error_code:错误码。
- error_msg:错误描述信息,帮助理解和解决发生的错误。
错误码
1语音合成
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis("""
轻轻的我走了,
正如我轻轻的来;
我轻轻的招手,
作别西天的云彩。 """, 'zh', 1, {
'vol': 5,#音量,取值0-15,默认为5中音量
'spd':6,# 语速,取值0-9,默认为5中语速
"pit":6,#音调,取值0-9,默认为5中语调
"per":4,#发音人选择, 0为女声,1为男声,3为情感合成-度逍遥,4为情感合成-度丫丫,默认为普通女
})
print(result)
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('auido.mp3', 'wb') as f:
f.write(result)
2语音识别
百度的语音识别的接口只能识别pcm wav格式的数据,并且数据录音只能在60s以内
因此需要借助其他工具将录音的音频文件装化为pcm的格式的文件
能将任意格式转化为pcm的
先下载安装ffmpeg
1.FFmpeg:
链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg
密码:w6hk
进到bin目录下 复制当前的路径,添加到path的环境变量里,输入ffmpeg出现一堆提示 说明搞对了
如果使用pycharm的话,需要重启一下pycharm
2.baidu-aip:
pip install baidu-aip
ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm
语音识别代码
import os
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm")
with open(f"{filePath}.pcm", 'rb') as fp:
return fp.read()
# 识别本地文件
res=client.asr(get_file_content('新录音.m4a'), 'pcm', 16000, {
'dev_pid': 1537,
})
print(res)
print(res.get('result')[0])
录音可以调用电脑的录音机,没有麦不能录音的朋友,可以使用手机录音,通过QQ等各种方式发到电脑,放到项目的同级目录下
简单的NLP
注意(以下代码很简陋)
我们的预想,定义一个函数,接收百度识别出来的文本,进行简单的判断(文本相似度),然后返回自定义的结果
若是都处理不了,接入图灵机器人http://www.tuling123.com
接入文档在这里https://www.kancloud.cn/turing/www-tuling123-com/718227
import os
from aip import AipSpeech,AipNlp
""" 你的 APPID AK SK """
APP_ID = '15674374'
API_KEY = '7qgGbZ9o8K6oCV7f9Lx8mvmj'
SECRET_KEY = 'kyvKM1Zovm0q0zNDnRzG9rtn6upz0xip'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm")
with open(f"{filePath}.pcm", 'rb') as fp:
return fp.read()
# 识别本地文件
res=client.asr(get_file_content('新录音.m4a'), 'pcm', 16000, {
'dev_pid': 1537,
})
print("语音识别的结果",res)
nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
def chat(text):
sim1=nlp_client.simnet(text,'你谁啊')
if sim1.get("score") >=0.58:
return '你好啊,我叫小石头'
sim2=nlp_client.simnet(text,'你今年多大了')
if sim2.get("score") >=0.58:
return '我今年18岁'
from tulin import questions
return questions(text)
word=chat(res.get('result')[0])
result = client.synthesis(word, 'zh', 1, {
'vol': 5,#音量,取值0-15,默认为5中音量
'spd':6,# 语速,取值0-9,默认为5中语速
"pit":6,#音调,取值0-9,默认为5中语调
"per":4,#发音人选择, 0为女声,1为男声,3为情感合成-度逍遥,4为情感合成-度丫丫,默认为普通女
})
print('语音合成的结果',result)
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('auido.mp3', 'wb') as f:
f.write(result)
os.system('auido.mp3')
调用图灵的机器人
import requests
url='http://openapi.tuling123.com/openapi/api/v2'
dic={
"reqType":0,
"perception": {
"inputText": {
"text": "你叫什么名字"
},
},
"userInfo": {
"apiKey": "5e17f0ab68604d8524e59c50473b08cc",#这里填写的是你的机器人的id
"userId": "132"#这里填的你自定义的用户id
}
}
# res=requests.post(url,json=dic)
# print(res)# <Response [200]>
# print(res.json())#{'intent': {'code': 4000}, 'results': [{'groupType': 0, 'resultType': 'text', 'values': {'text': '请求参数缺失或格式错误!'}}]}
"""
<Response [200]>
{'emotion': {'robotEmotion': {'a': 0, 'd': 0, 'emotionId': 0, 'p': 0}, 'userEmotion': {'a': 0, 'd': 0, 'emotionId': 0, 'p': 0}}, 'intent': {'actionName': '', 'code': 10004, 'intentName': ''}, 'results': [{'groupType': 0, 'resultType': 'text', 'values': {'text': '聪明又善解人意的小娜娜就是我了'}}, {'groupType': 0, 'resultType': 'text', 'values': {'text': '那你叫什么名字呢?'}}]}
"""
def questions(qus):
dic["perception"]['inputText']['text']=qus
res = requests.post(url, json=dic)
return res.json().get("results")[0].get('values').get("text")
if __name__ == '__main__':
qus='你多大了?'
ret=questions(qus)
print(ret)
欢迎关注
