今天新学习了一个敏感词匹配的算法,记录一下。
原文地址:https://blog.csdn.net/qq_36827957/article/details/74357283
1、用途:
主要用于敏感词匹配。
2、原理:
以王八蛋和王八羔子两个敏感词来进行描述,首先构建敏感词库,该词库名称为SensitiveMap,这两个词的二叉树构造为:
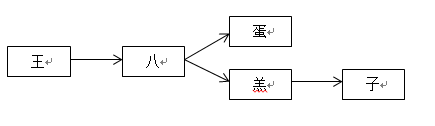
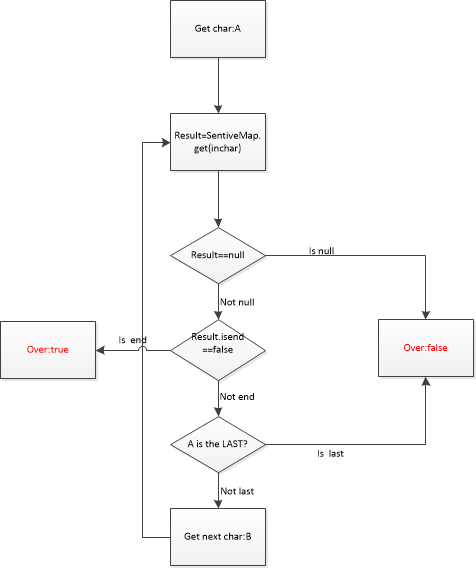
以上面例子构造出来的SensitiveMap为敏感词库进行示意,假设这里输入的关键字为:王八不好,流程图如下:
3.代码编写
3.1构造敏感词实现代码

3.2实现敏感词查询代码

4.优化思路
4.1敏感词中间填充无意义字符问题
对于“王*八&&蛋”这样的词,中间填充了无意义的字符来混淆,在我们做敏感词搜索时,同样应该做一个无意义词的过滤,当循环到这类无意义的字符时进行跳过,避免干扰。
4.2敏感词用拼音或部分用拼音代替
两种解决思路:一种是最简单是遇到这类问题,先丰富敏感词库进行快速解决。第二种是判断时将敏感词转换为拼音进行对比判断。
不过目前这两种方案均不能彻底很好的解决该问题,此类问题还需进一步研究。
4.3效率问题
由于敏感词的在构造词库时耗时长,建议将构造后的敏感词库进行缓存。在敏感词新增和删除时进行词库的更新。