熵
在信息论中,熵(entropy)是表示随机变量不确定性的度量,如果一个事件是必然发生的,那么他的不确定度为0,不包含信息。假设
X是一个取有限个值的离散随机变量,其概率分布为:
P(X=xi)=pi
则随机变量
X的熵定义为:
H(X)=−i=1∑npilog(pi)
通常上式中
log的底数为2或
e(自然对数),这时熵的单位分别称作比特(bit)或纳特(nat)。并且通过上述定义可知,熵的取值只依赖于
X的分布,而与
X的具体值无关。
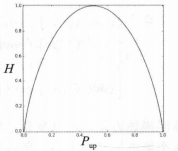
以
P=0.5的二项分布为例,熵
H随概率
p变化的曲线如下所示:
条件熵
设有随机变量
(X,Y),其联合概率分布为:
P(X=xi,Y=yj)=pij, i=1,2,...,n; j=1,2,...,m
条件熵(conditional entropy)表示在已知随机变量
X的条件下随机变量
Y的不确定性,定义为
X给定条件下
Y的条件概率分布的熵对
X的数学期望:
H(Y∣X)=i=1∑npiH(Y∣X=xi),pi=P(X=xi),i=1,2,...,n.
在计算条件熵时,需要先分别计算
X取不同值时变量
Y的熵,即
H(Y∣X=xi),总共
n个(假设
X有
n种不同取值),然后求其对
X的期望。
互信息
互信息,在机器学习(决策树算法)中也称为信息增益。特征
A对训练数据集
D的信息增益
g(D,A),定义为集合
D的经验熵
H(D)与特征
A给定的条件下
D的经验条件熵
H(D∣A)之差,即:
g(D∣A)=H(D)−H(D∣A)
联合熵
联合熵度量的是一个联合分布的随机系统的不确定度,同样以联合概率分布
(X,Y)为例,
P(X=xi,Y=yj)=pij, i=1,2,...,n; j=1,2,...,m,则联合熵
H(X,Y)的定义为:
H(X,Y)=−i=1∑nj=1∑mpijlog(pij)
联合熵具有以下性质(对于变量数目大于2的情况同样成立):
- 联合熵大于其中任一变量独立的熵:
H(X,Y)>max{H(X),H(Y)}
- 联合熵小于所有变量独立熵之和:
H(X,Y)<H(X)+H(Y)
-
H(X,Y)=H(Y∣X)+H(X)=H(X∣Y)+H(Y)
-
g(Y∣X)=H(X)+H(Y)−H(X,Y)