环球宝贝代孕好不好?█微/信 同号█:138★0226★9370█ ████ █代孕包成功█ ★█代孕包男孩█ ★█环球宝贝代孕,环球宝贝助孕
对操作系统中的各种缓存进行一下梳理:
(一)高速缓冲存储器cache
1、cache的工作原理
高速缓冲存储器利用程序访问的局部性原理,把程序中正在使用的部分存放在一个高速的、容量较小的cache中,使CPU的访存操作大多数针对cache进行,从而使程序的执行速度大大提高。
当CPU发出读请求时,如果访存地址在cache中命中,就将此地址转换成cache地址,直接对cache进行读操作,与主存无关;如果cache不命中,则仍需访问主存,将此字所在的块一次从主存调入cache中。若此时cache已满,则需根据某种替换算法(如最久未使用算法(LRU)、先进先出算法(FIFO)、最近最少使用算法(LFU)、非最近使用算法(NMRU)等),用这个块替换掉cache中原来的某块信息。值得注意的是,CPU与cache之间的数据交换以字为单位,而cache和主存之间的数据交换则是以cache块为单位的。
CPU对cache的写入更改了cache的内容,故需选择某种策略使得cache内容和主存内容保持一致,主要为:
全写法(cache-through):当CPU对cache写命中时,必须把数据同时写入cache和主存。当某一块需要替换时,不必把这一块写回主存,将新调入的块直接覆盖即可。这种方法实现简单,能随时保持主存数据的正确性,缺点是增加了访存次数,降低了cache的效率。
写回法(cache-back):当CPU对cache写命中时,只修改cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。这种方法减少了访存次数,但存在不一致的隐患。采用这种策略时,每个cache行必须设置一个标志位(脏位),以反映此块是否被CPU修改过。
如果写不命中,还需考虑是否调块至cache的问题,非写分配法只写入内存,不进行调块,非写分配法通常与全写法合用。写分配法除了要写入主存外,还要将该块从主存调入至cache,通常与写回法合用。
下图转载自: https://blog.csdn.net/wangwei222/article/details/79748597


2、cache和主存的映射方式
(1)直接映射: 主存数据块只能装入cache中的唯一位置。若这个位置已有内容,则产生块冲突,原来的块被无条件地替换出去(无需使用替换算法)。直接映射实现简单,但不够灵活。直接映射的关系可定义为:
j= i mod c // j为cache块号,i为主存块号,c是cache中的总块数
下图转载自: https://www.cnblogs.com/yutingliuyl/p/6773684.html
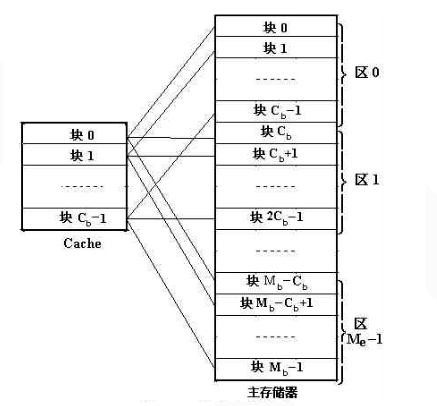
(2)全相联映射:可以把主存数据块放入cache的任何位置,比较灵活,冲突概率低,但地址变换速度慢,实现成本高,查找时需全部遍历一遍。下图中左边为主存,右边为cache
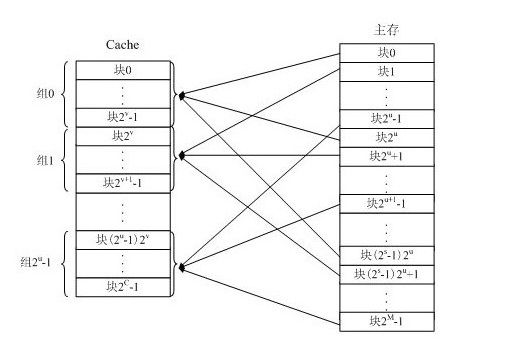
(3)组相联映射:将cache分成大小相同的组,主存中的一个数据块可以装入到一个组内的任何一个位置,即组间采取直接映射,组内采用全相联,每组有多少块就称为几路组相联,可用下式表示:
j = i mod q // j为缓存块号, i为主存块号, q为cache组数,当q为1时为全相联映射, q为cache块数时为直接映射
图源: https://www.cnblogs.com/jasmine-Jobs/p/6959261.html
(二)地址转换后援缓冲器TLB
下述内容参考:https://www.cnblogs.com/alantu2018/p/9000777.html
上述cache为在得到物理地址之后,对访问内存的一个加速,而系统虚拟地址需要通过页表转换为物理地址,页表一般都很大,并且存放在内存中,所以处理器引入MMU后,读取指令、数据需要访问两次内存:首先通过查询页表得到物理地址,然后访问该物理地址读取指令、数据。为了减少因为MMU导致的处理器性能下降,引入了TLB,TLB是Translation Lookaside Buffer的简称,可翻译为“地址转换后援缓冲器”,也可简称为“快表”。简单地说,TLB就是页表的Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。只有在TLB无法完成地址翻译任务时,才会到内存中查询页表(还有的说是查找时快表和慢表,即放在主存中的页表同时进行,若快表中有此逻辑页号,则将其对应的物理页号送入主存地址寄存器,并使慢表的查找作废),这样就减少了页表查询导致的处理器性能下降。
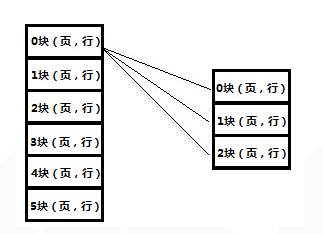
TLB中的项由两部分组成:标识和数据。标识中存放的是虚地址的一部分,而数据部分中存放物理页号、存储保护信息以及其他一些辅助信息。虚地址与TLB中项的映射方式有三种:全关联方式、直接映射方式、分组关联方式。直接映射方式是指每一个虚拟地址只能映射到TLB中唯一的一个表项。假设内存页大小是8KB,TLB中有64项,采用直接映射方式时的TLB变换原理如下图所示:

因为页大小是8KB,所以虚拟地址的0-12bit作为页内地址偏移。TLB表有64项,所以虚拟地址的13-18bit作为TLB表项的索引。假如虚拟地址的13-18bit是1,那么就会查询TLB的第1项,从中取出标识,与虚拟地址的19-31位作比较,如果相等,表示TLB命中,反之,表示TLB失靶。TLB失靶时,可以由硬件将需要的页表项加载入TLB,也可由软件加载,具体取决于处理器设计。TLB命中时,此时翻译得到的物理地址就是TLB第1项中的标识(即物理地址13-31位)与虚拟地址0-12bit的结合。在地址翻译的过程中还会结合TLB项中的辅助信息判断是否发生违反安全策略的情况,比如:要修改某一页,但该页是禁止修改的,此时就违反了安全策略,会触发异常。
TLB表项更新可以有TLB硬件自动发起,也可以有软件主动更新
1. TLB miss发生后,CPU从RAM获取页表项,会自动更新TLB表项
2. TLB中的表项在某些情况下是无效的,比如进程切换,更改内核页表等,此时CPU硬件不知道哪些TLB表项是无效的,只能由软件在这些场景下,刷新TLB。
在linux kernel软件层,提供了丰富的TLB表项刷新方法,但是不同的体系结构提供的硬件接口不同。比如x86_32仅提供了两种硬件接口来刷新TLB表项:
1. 向cr3寄存器写入值时,会导致处理器自动刷新非全局页的TLB表项
2. 在Pentium Pro以后,invlpg汇编指令用来使指定线性地址的单个TLB表项无效。
TLB内部存放的基本单位是TLB表项,TLB容量越大,所能存放的TLB表项就越多,TLB命中率就越高,但是TLB的容量是有限的。目前 Linux内核默认采用4KB大小的小页面,如果一个程序使用512个小页面,即2MB大小,那么至少需要512个TLB表项才能保证不会出现 TLB Miss的情况。但是如果使用2MB大小的大页,那么只需要一个TLB表项就可以保证不会出现 TLB Miss的情况。对于消耗内存以GB为单位的大型应用程序,还可以使用以1GB为单位的大页,从而减少 TLB Miss的情况。
(三)页缓存和块缓存
上述缓存机制为所需数据已经在物理内存中,而页缓存和块缓存则是在进行磁盘io时使用的。
(1)页缓存:针对以页为单位的所有操作,页缓存实际上负责了块设备的大部分缓存工作。页缓存的任务在于获得一些物理内存页,以加速在块设备上按页为单位执行的操作。
(2)块缓存:以块为操作单位,在进行io操作时,存取的单位是设备的各个块而不是整个内存页,尽管也长度对所有文件系统是相同的,但是块长度取决于特定的文件系统或其设置,因而块缓存必须能够处理不同长度的块。
待添加。