目标网站
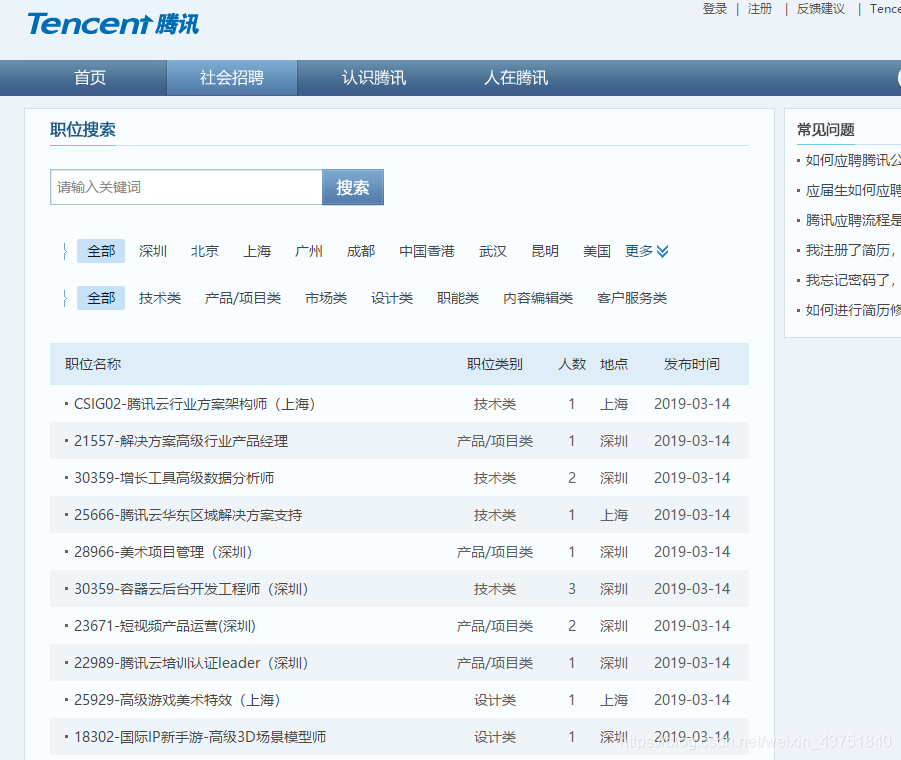
目标数据
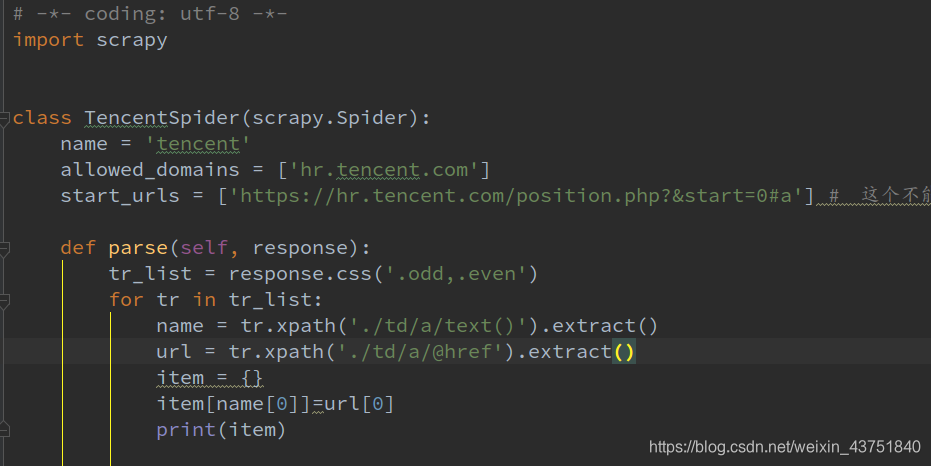
首先新建一个爬虫

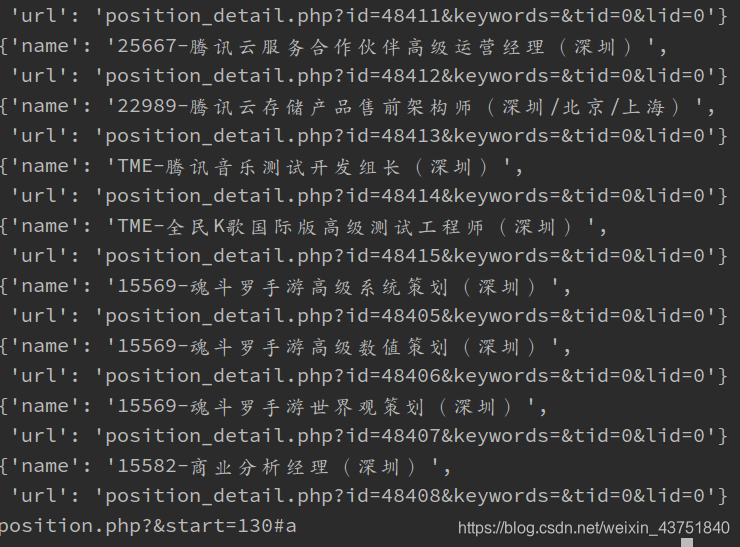
初步提取职位名称和对应的url
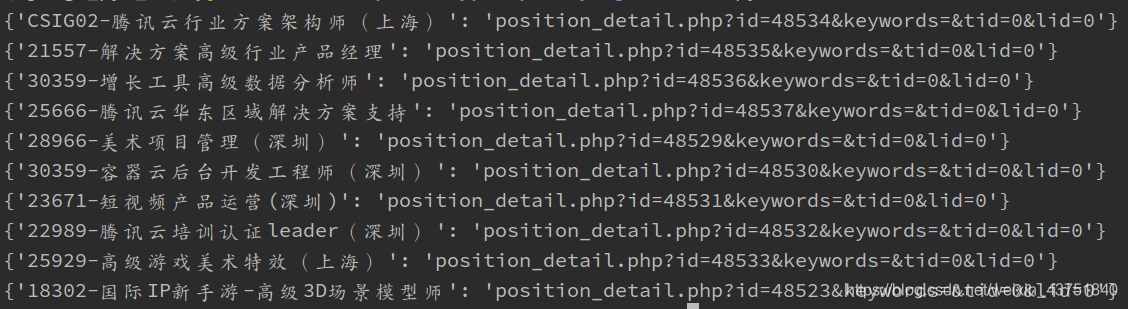
打印结果
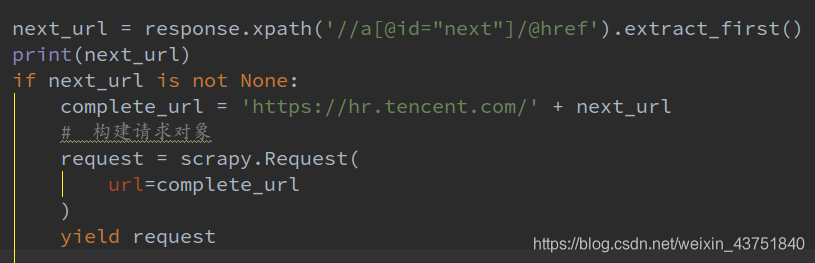
发送下一页的url,发送请求,请求成功后继续调用pase函数解析
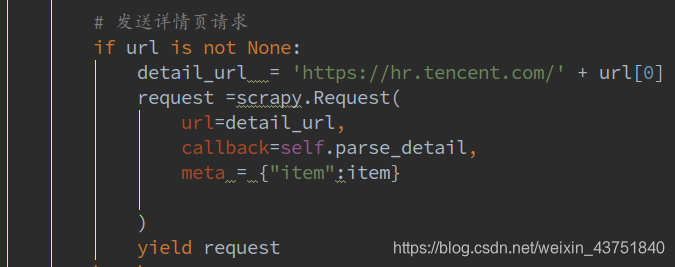
发送详情页请求
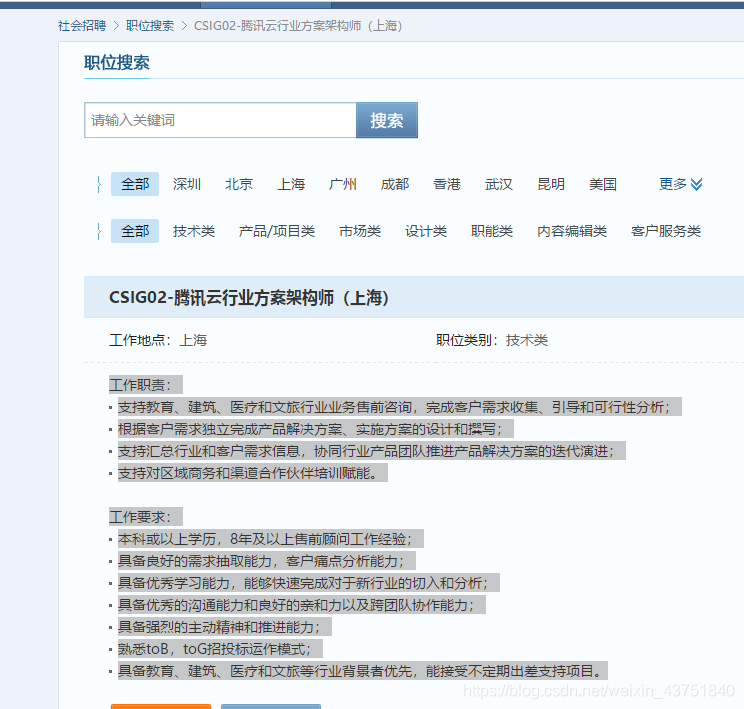
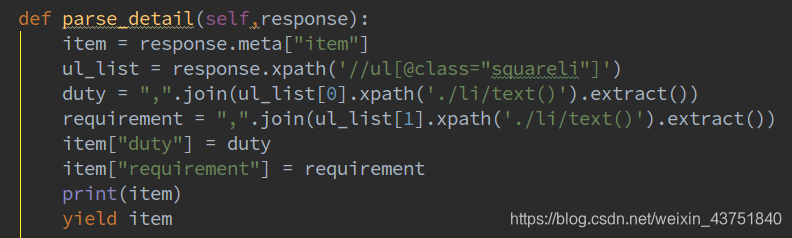
解析详情页

打印结果:
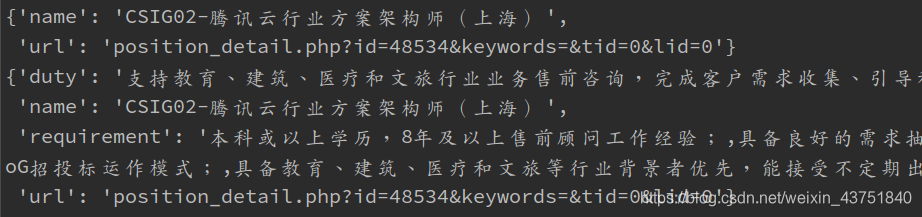
接下来重写一个管道,让数据保存到mongodb
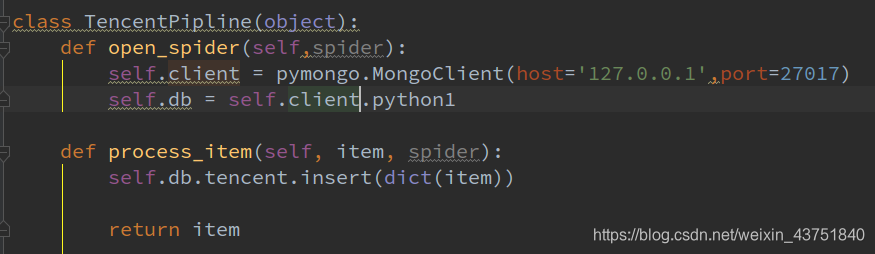
setting中配置管道

运行爬虫

查看数据库
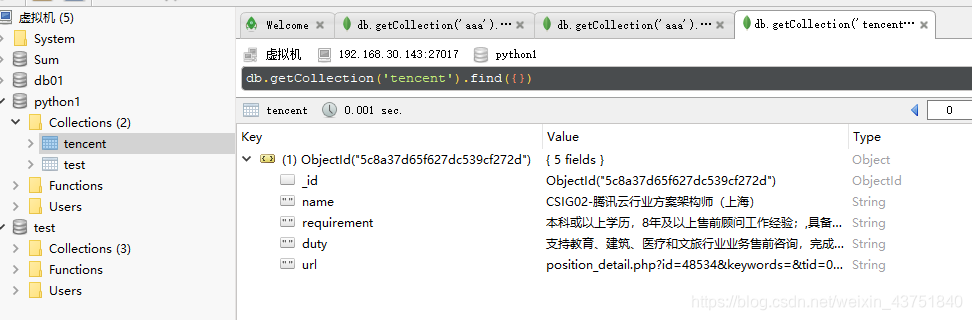
数据已存入
继续让爬虫跑完
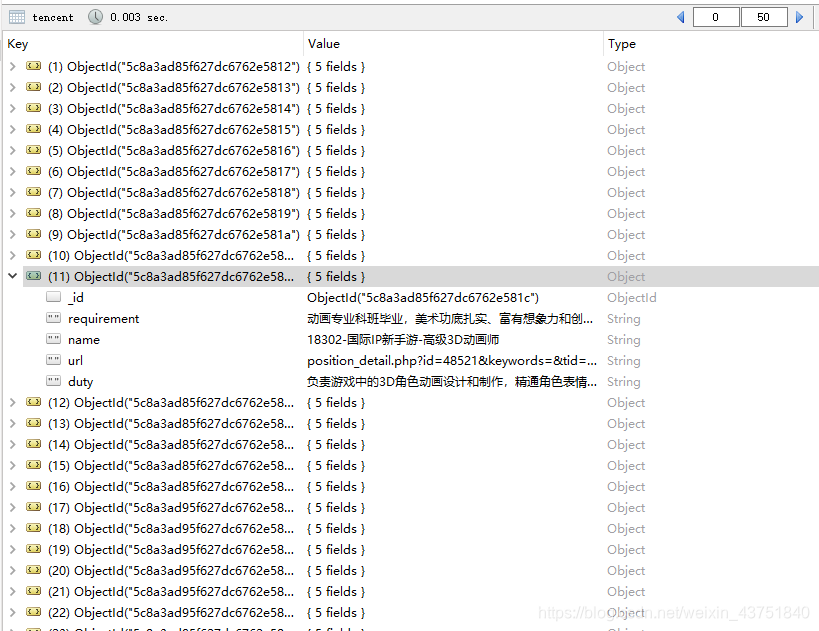
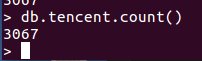
一共3067条数据
一下是完整代码:
tencent2.py 爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from ..items import TencentItem
class TencentSpider(scrapy.Spider):
name = 'tencent2'
allowed_domains = ['hr.tencent.com']
base_url = 'https://hr.tencent.com/position.php?&start={}#a'
start_urls = [] # 这个不能用首页地址,一定要加参数访问,不然得不到值
for start in range(0,3080,10):
start_urls.append(base_url.format(start))
def parse(self, response):
tr_list = response.css('.odd,.even')
for tr in tr_list:
name = tr.xpath('./td/a/text()').extract()
url = tr.xpath('./td/a/@href').extract()
item = TencentItem()
item["name"] = name[0]
item["url"] = url[0]
# print(item)
# 发送详情页请求
if url is not None:
detail_url = 'https://hr.tencent.com/' + url[0]
request =scrapy.Request(
url=detail_url,
callback=self.parse_detail,
meta = {"item":item}
)
yield request
def parse_detail(self,response):
item = response.meta["item"]
ul_list = response.xpath('//ul[@class="squareli"]')
duty = ",".join(ul_list[0].xpath('./li/text()').extract())
requirement = ",".join(ul_list[1].xpath('./li/text()').extract())
item["duty"] = duty
item["requirement"] = requirement
# print(item)
yield item
item.py 模型文件
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
url = scrapy.Field()
duty = scrapy.Field()
requirement = scrapy.Field()
pipelines.py 管道文件
import pymongo
class TencentPipline(object):
def open_spider(self,spider):
self.client = pymongo.MongoClient(host='127.0.0.1',port=27017)
self.db = self.client.python1
def process_item(self, item, spider):
self.db.tencent.insert(dict(item))
return item
settings.py 配置文件
LOG_LEVEL = 'WARNING'
ITEM_PIPELINES = {
'testproject.pipelines.TencentPipline': 300,
}