之前看了AtomicInteger的使用,代码。我们再看下atomic包下的其他类。我们先对其进行简单的分类:
第一类:使用原子的方式更新基本类型
AtomicInterger
AtomicBoolean
AtomicLong
在之前的文章介绍过AtomicInterger:https://blog.csdn.net/java_yes/article/details/83864042
而AtomicBoolean、AtomicLong和AtomicInterger原理基本一样。就不过多介绍。
第二类:通过原子的方式更新数组里的某个元素
AtomicIntegerArray
举例:
static int[] values = new int[10];
static AtomicIntegerArray atomicIntegerArray =new AtomicIntegerArray(values);
使用普通int数组:
@Test
public void integerArrayTest() throws InterruptedException {
for (int i = 0; i < 1000000; i++) {
new Thread() {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
for (int j = 0; j < 10; j++) {//所有元素+1
values[j]++;
}
}
}
}.start();
}
for (int i = 0; i < 10; i++) {
System.out.print(values[i] + " ");
}
}
结果:
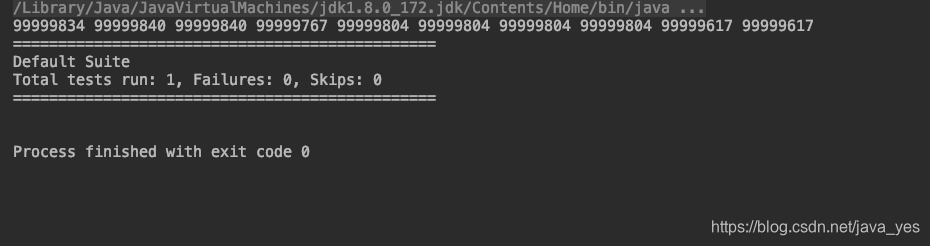
使用AtomicIntegerArray:
@Test
public void atomicIntegerArrayTest() throws InterruptedException {
for (int i = 0; i < 1000000; i++) {
new Thread() {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
for (int j = 0; j < 10; j++) {//所有元素+1
atomicIntegerArray.getAndIncrement(j);
}
}
}
}.start();
}
for (int i = 0; i < 10; i++) {
System.out.print(atomicIntegerArray.get(i) + " ");
}
}

需要注意的是,数组value通过构造方法传递进去,然后AtomicIntegerArray会将当前数组复制一份,所以当AtomicIntegerArray对内部的数组元素进行修改时,不会影响传入的数组。
AtomicLongArray
AtomicReferenceArray
第三类:原子更新引用
AtomicReference:原子更新引用类型
举例:
import org.testng.annotations.Test;
import java.util.concurrent.atomic.AtomicReference;
public class AtomicReferenceTest {
private static int threadCount = 10;
public static AtomicReference<User> atomicUserRef = new AtomicReference<User>();
@Test
private void atomicReferenceTest() throws InterruptedException {
new Thread() {
@Override
public void run() {
for (int i = 1; i < 10; i++) {
User oldUser = atomicUserRef.get();
atomicUserRef.compareAndSet(oldUser, new User("name" + i, i));
}
}
}.start();
Thread.sleep(1000);
System.out.println(atomicUserRef.get().getName());
System.out.println(atomicUserRef.get().getOld());
}
static class User {
private String name;
private int old;
public User(String name, int old) {
this.name = name;
this.old = old;
}
public String getName() {
return name;
}
public int getOld() {
return old;
}
}
}
结果:

AtomicStampedReference:原子更新引用类型里的字段
AtomicMarkableReference:原子更新带有标记位的引用类型
第四类:原子更新字段
AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
AtomicLongFieldUpdater:原子更新长整型字段的更新器。
AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于原子的更新数据和数据的版本号,可以解决使用CAS进行原子更新时可能出现的ABA问题。

第五类:.原子类型累加器
LongAccumulator
LongAdder
DoubleAccumulator
DoubleAdder
参考:https://blog.csdn.net/hanchao5272/article/details/79689366
先解释一下这个类是干嘛的
根据类前面的注释,大概翻译一下:
一个或多个变量,它们一起维护使用提供的函数更新的运行的long值。当跨线程争用更新accumulate时,变量集可以动态增长以减少争用。方法get(或者,等效longValue)在维护更新的变量之间返回当前值。
当多个线程更新一个公共值时,LongAccumulator通常优于AtomicLong,LongAccumulator用于收集统计信息,而不是用于细粒度同步控制。在低更新竞争下,这两个类具有相似的特性。但是,在高争用情况下,LongAccumulator预期吞吐量显著较高,而代价是较高的空间消耗。
线程内或线程间的累积顺序没有保证,也不能依赖,因此LongAccumulator仅适用于累积顺序无关的函数。提供的累加器函数应该是无副作用的,因为当尝试的更新由于线程之间的争用而失败时,可以重新应用该函数。LongAccumulator以当前值作为第一个参数,以给定的更新作为第二个参数。例如,为了维持运行的最大值,您可以提供{@code.::max}以及{@code…MIN_VALUE}作为标识。
这个类扩展Number类,但没有定义诸如equals、hashCode和compareTo之类的方法,因为期望实例发生变化,因此作为集合键没有用。
内部实现
原子类型累加器其实是应用了热点分离思想,这一点可以类比一下ConcurrentHashMap的设计思想。
热点分离简述:
将竞争的数据进行分解成多个单元,在每个单元中分别进行数据处理。
各单元处理完成之后,通过Hash算法进行计算求和,从而得到最终的结果。
热点分离优缺点:
热点分离的设计减小了锁的粒度,提高了高并发环境下的吞吐量。
热点分离的设计需要划分额外的空间进行单元数据的存储,增大空间消耗。
基本方法
下面以LongAdder为例,对原子类型累加器的基本方法进行学习:
- LongAdder():累加器只有一个无参的构造器,会构造一个sum=0的实例对象。
- increment():自增。increment():自增。
- decrement():自减。decrement():自减。
- add(delat):增量计算。add(delat):增量计算。
- sum():计算sum的和。sum():计算sum的和。
- reset():重置sum为0。reset():重置sum为0。
- sumThenReset():计算sum的和并且重置sum为0。sumThenReset():计算sum的和并且重置sum为0。
- intValue():获取sum的int形式(向下转型)。intValue():获取sum的int形式(向下转型)。
- floatValue():获取sum的float形式(向上转型)。floatValue():获取sum的float形式(向上转型)。
- doubleValue():获取sum的double形式(向上转型)。 doubleValue():获取sum的double形式(向上转型)。