3.1 编写函数test(password, earning, age)用于检测输入错误。要求输入密码password第一个符号不能是数字,工资earnings的范围是0—20000,工作年龄的范围是18—70。若三项检查都通过则返回True。
代码:
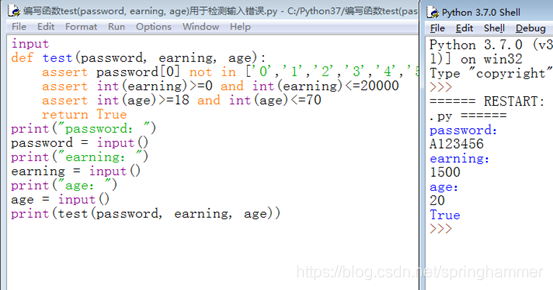
input
def test(password, earning, age):
assert password[0] not in ['0','1','2','3','4','5','6','7','8','9']
assert int(earning)>=0 and int(earning)<=20000
assert int(age)>=18 and int(age)<=70
return True
print("password:")
password = input()
print("earning:")
earning = input()
print("age:")
age = input()
print(test(password, earning, age))
结果:
3.2 输入某年某月某日,判断这一天是这一年的第几天。
代码:
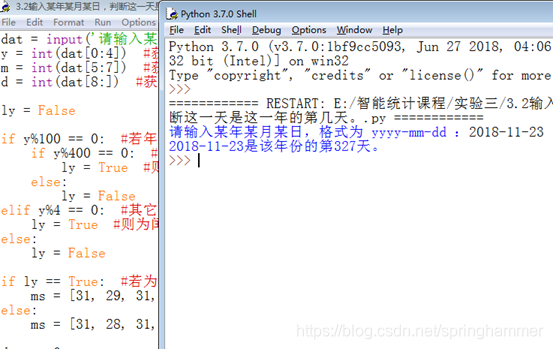
dat = input('请输入某年某月某日,格式为 yyyy-mm-dd :')
y = int(dat[0:4]) #获取年份
m = int(dat[5:7]) #获取月份
d = int(dat[8:]) #获取日
ly = False
if y%100 == 0: #若年份能被100整除
if y%400 == 0: #且能被400整除
ly = True #则是闰年
else:
ly = False
elif y%4 == 0: #其它情况下,若能被4整除
ly = True #则为闰年
else:
ly = False
if ly == True: #若为闰年,则2月份有29天
ms = [31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
else:
ms = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
days = 0
for i in range(1, 13): #从1到12逐一判断,以确定月份
if i == m:
for j in range(i-1): #确定月份i之后,则将ms列表中的前i-1项相加
days += ms[j]
print('%s是该年份的第%s天。' % (dat, (days + d))) #最后再加上“日”,即是答案
结果:
3.3 创建文本文件
创建文本文件FarewellCambridge.txt。内容包含以下语句:
Very quietly I take my leave
As quietly as I came here
Quietly I wave good-bye
To the rosy clouds in the western sky
The golden willows by the riverside
Are young brides in the setting sun
Their reflections on the shimmering waves
统计单词总数目以及各个单词出现的次数(注意:直接将上述语句拷贝到程序中,不需要自己录入)。
代码:
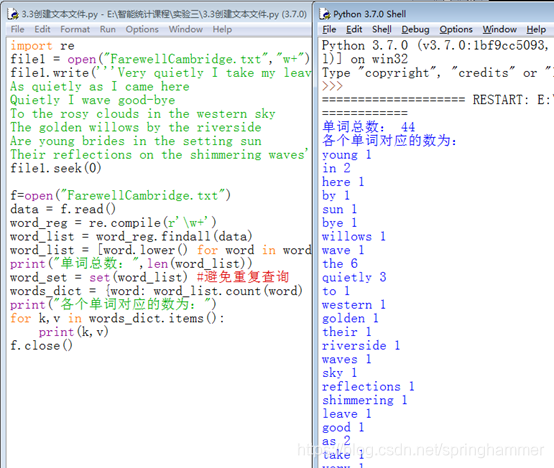
import re
file1 = open("FarewellCambridge.txt","w+")
file1.write('''Very quietly I take my leave
As quietly as I came here
Quietly I wave good-bye
To the rosy clouds in the western sky
The golden willows by the riverside
Are young brides in the setting sun
Their reflections on the shimmering waves''')
file1.seek(0)
f=open("FarewellCambridge.txt")
data = f.read()
word_reg = re.compile(r'\w+')
word_list = word_reg.findall(data)
word_list = [word.lower() for word in word_list] #转小写
print("单词总数:",len(word_list))
word_set = set(word_list) #避免重复查询
words_dict = {word: word_list.count(word) for word in word_set}
print("各个单词对应的数为:")
for k,v in words_dict.items():
print(k,v)
f.close()
结果:
3.4 读取文本文件
对于上一题建立的文本文件,使用read()读文件,将其中所有小写字母变成大写字母,大写字母变成小写字母,并在屏幕上显示。
代码:
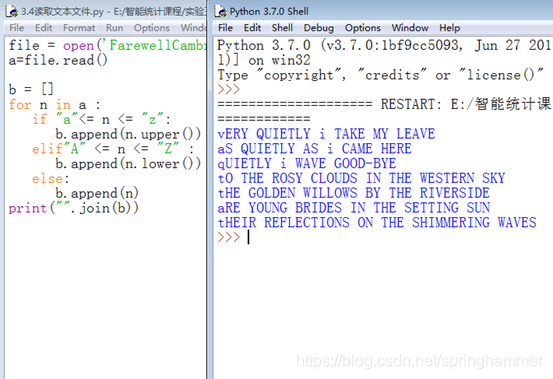
file = open('FarewellCambridge.txt','r')
a=file.read()
b = []
for n in a :
if "a"<= n <= "z":
b.append(n.upper())
elif"A" <= n <= "Z" :
b.append(n.lower())
else:
b.append(n)
print("".join(b))
结果:
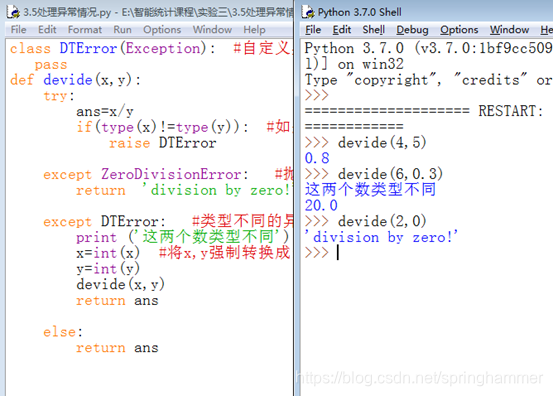
3.5 处理异常情况
编写函数devide(x, y),x为被除数,y为除数,x,y均要求为整数。另外要求:
1、被零除时,调用异常处理输出"division by zero! ";
2、判断x,y不是整数时,强制转换为整数再调用本函数,如果x,y是整数则不用转换;
3、若没有异常则输出计算结果。
代码:
class DTError(Exception): #自定义异常,没有这个类定义 ,下面的DTError就会报错
pass
def devide(x,y):
try:
ans=x/y
if(type(x)!=type(y)): #如果两个数类型不同,raise语句抛出(自定义)异常
raise DTError
except ZeroDivisionError: #抛出除数为0的异常
return 'division by zero!'
except DTError: #类型不同的异常
print ('这两个数类型不同') #先提示类型不同
x=int(x) #将x,y强制转换成int,再次调用函数
y=int(y)
devide(x,y)
return ans
else:
return ans
结果:
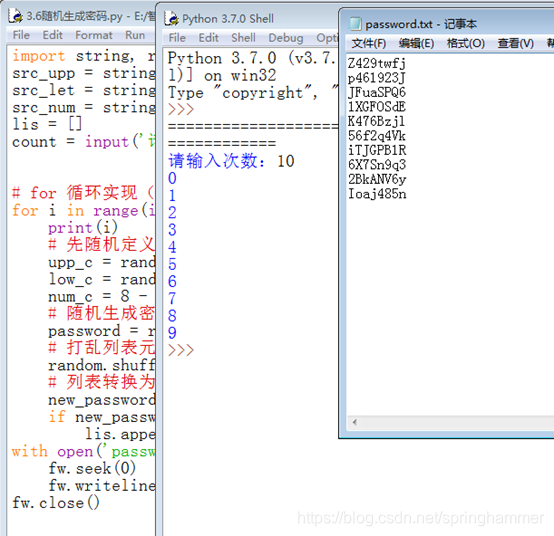
3.6 随机生成密码
利用26个英文字母和10个数字组成的列表随机生成10个8位密码,并存储在文件passwords.txt中。
代码:
import string, random
src_upp = string.ascii_uppercase
src_let = string.ascii_lowercase
src_num = string.digits
lis = []
count = input('请输入次数:').strip()
# for 循环实现(产生密码数可能不足)
for i in range(int(count)):
print(i)
# 先随机定义3种类型各自的个数(总数为8)
upp_c = random.randint(1, 6)
low_c = random.randint(1, 8-upp_c - 1)
num_c = 8 - (upp_c + low_c)
# 随机生成密码
password = random.sample(src_upp, upp_c)+random.sample(src_let, low_c)+random.sample(src_num, num_c)
# 打乱列表元素
random.shuffle(password)
# 列表转换为字符串
new_password = ''.join(password)+'\n'
if new_password not in lis:
lis.append(new_password)
with open('password.txt', 'w') as fw:
fw.seek(0)
fw.writelines(lis)
fw.close()
结果:
3.7 读取程序并转换
读取一个python源程序文件(*.py格式),将文件中所有除了保留字以外的小写字母变成大写字母,生成的新文件仍然能被python环境执行。
代码:
# -*- coding :utf-8 -*-
import keyword
f= open('test.py','r', encoding='UTF-8')
content = f.read()
f.close()
table = ['range','print','list','set','keyword','kwlist','end']
fs = '' #用于存储改变后的内容
temp = '' #临时字符串,用于判断和处理
for ch in content:
if ch.isalpha(): #如果是字母,则加到temp后面,用于后面处理
temp +=ch
else: #如果不是字母,表示一个连续的字母构成的字符串结束,此时ch非字母
if (not keyword.iskeyword(temp)) and (temp not in table): #如果不是保留字和内置方法,将其变成大写
temp = temp.upper()
fs+=temp #将temp添加到fs
fs+=ch #添加 非字母ch 注意不能和 fs+=temp 位置颠倒
temp = '' #清空临时字符串,用于下次使用
f = open('test','w')
f.write(fs)
f.close()
测试代码:
import random # 随机数产生10个整数(0-100),放入一个列表中,统计出现次数最多的数字.
number = [] # 1.存放随机数列表
for i in range(0, 10): # 2.循环10次
num = random.randint(0,100) # 3.生成0-100之间的随机整数
number.append(num) # 4.添加到列表中
print(number)
转换后代码:
import random # 随机数产生10个整数(0-100),放入一个列表中,统计出现次数最多的数字.
NUMBER = [] # 1.存放随机数列表
for I in range(0, 10): # 2.循环10次
NUM = RANDOM.RANDINT(0,100) # 3.生成0-100之间的随机整数
NUMBER.APPEND(NUM) # 4.添加到列表中
print(NUMBER)
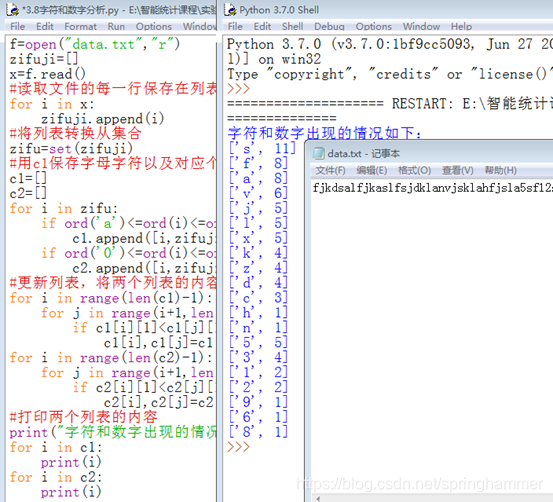
3.8 字符和数字分析
读取文本文件中的字符和数字,统计各个字符和数字出现频率,按照字符和数字出现频率分别降序打印字母和数字。
代码:
f=open("data.txt","r")
zifuji=[]
x=f.read()
#读取文件的每一行保存在列表中
for i in x:
zifuji.append(i)
#将列表转换从集合
zifu=set(zifuji)
#用c1保存字母字符以及对应个数,c2保存数字字符及其对应个数
c1=[]
c2=[]
for i in zifu:
if ord('a')<=ord(i)<=ord('z') or ord('A')<=ord(i)<=ord('Z') :
c1.append([i,zifuji.count(i)])
if ord('0')<=ord(i)<=ord('9'):
c2.append([i,zifuji.count(i)])
#更新列表,将两个列表的内容按照字符对应个数的大小从大到小排序
for i in range(len(c1)-1):
for j in range(i+1,len(c1)):
if c1[i][1]<c1[j][1]:
c1[i],c1[j]=c1[j],c1[i]
for i in range(len(c2)-1):
for j in range(i+1,len(c2)):
if c2[i][1]<c2[j][1]:
c2[i],c2[j]=c2[j],c2[i]
#打印两个列表的内容
print("字符和数字出现的情况如下:")
for i in c1:
print(i)
for i in c2:
print(i)
结果
我想能看到这里的同学,无外乎两种人:来拷贝代码的人 和 来拷贝代码的人。
但,在拷贝走的时候,你要想清楚一件事,把代码拷走之后有个蛋用,搞明白对你来说才是最重要的。
好了,就酱紫。
老铁,这要是都不赞,说不过去吧!!!
最后对自己说:
你现在所遭遇的每一个不幸,都来自一个不肯努力的曾经。