其实PCA算法与SVD算法目标是一致的,就是简化数据,去噪,PCA有个缺点,可能会缺少重要信息。
PCA有一个核心思想: 方差最大的方向表示数据中最重要的信息。所以PCA算法是在原数据上从新建立一个坐标,新坐标是按照方差最大的方向上建立。
程序上是
1. 需要数据归一化
2. 计算协方差
3. 计算协方差的特征值和特征向量(新的坐标轴)
4. 根据特征值从大到小,保留部分特征
5. 使用保留的特征对应的特征向量对元数据进行降维
协方差是衡量两个变量的变化趋势
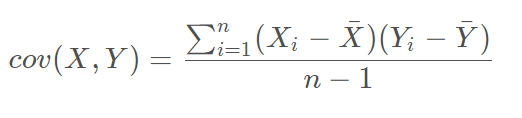
这里我详细说一下cov的计算过程:
data = [[2,7,9],[3,3,2],[5,7,5]]| 2 |
7 |
9 |
| 3 |
3 |
2 |
| 5 |
7 |
5 |
cdata = np.cov(data, rowvar=0) rowvar=0在计算协方差时使用data的列作为变量  计算协方差的特征向量与特征值:
计算协方差的特征向量与特征值:
w, u= np.linalg.eig(np.mat(cdata))
官方文当的解释 w是特征值的数组,w[i] 对应的特征向量是 u[ :, i]
选择保留的特征,需要给w排序,从大到小, 并且找出对应的特征向量(按照特征值从大到小)
rect = u[:, [....]] #这里就写选择固有特征
给数据降维:
newdata = data * rect还原原始数据:
newdata * rect.T