一、Kafka
1、消息中间件(现在改名为分布式流式平台)
kafka
MQ
Redis
2、kafka的框架
生产者:Broker:消费者
正常部署的是:Broker
3、企业常用的框架
Flume-->Kafka(sink到Kafka)-->Spark streaming 流式处理
Kafka streaming
4、特点
1)发布/订阅

2)处理实时应用

3)分布式、可复制、容错性

5、官网介绍

由于企业很多用spark-streaming-kafka-0-10,所以kafka用0.10版本
二、安装部署kafka(kafka源码是scala编写的)
1、版本要求
kafka_2.11-0.10.0.0.tgz
scala version:2.11
2、环境要求
1)JDK
2)Scala
3)Zookeeper
3、软连接
ln -s zookeeper-3.4.6 zookeeper
删除:rm -rf zookeeper
类似window桌面快捷方式
ln -s 物理文件/文件夹 快捷方式的文件/文件夹
好处:
1)删除快捷的文件夹/文件,物理的没删除,增加安全系数
2)方便于升级和多版本的使用
3)了解硬连接(作业)
4、部署zk
1)conf/zoo.cfg
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
存储临时数据的,维护用
dataDir=/opt/software/zookeeper/data
server.1=hadoop001:2888:3888
server.2=hadoop002:2888:3888
server.3=hadoop003:2888:3888
三台机器的zoo.cfg一样
2)创建data
mkdir /opt/software/zookeeper/data
touch data/myid
echo 1 > data/myid
其他机器:
echo 2 > data/myid
echo 3 > data/myid
3)启动
./zkServer.sh start
4)查状态
./zkServer.sh status
5、部署kafka(kafka_2.11-0.10.0.1)
1)解压kafka
tar -zvxf kafka_2.11-0.10.0.1.tgz
2)软连接
ln -s kafka_2.11-0.10.0.1 kafka
3)修改conf/server.properties文件
Server Basics:
broker.id=1
port=9092
host.name=hadoop001
Log Basics:
log.dirs=/opt/software/kafka/logs(保存写入kafka的数据)
log Flush Policy:

数据写入磁盘的刷新方式。一个是信息刷了一万行就写入磁盘;一个是等待1s,就写入磁盘。
Zookeeper:
zookeeper.connect=hadoop001:2181,hadoop002:2181,hadoop003:2181/kafka
4)将server.properties发给其他机器并修改属于自己的server.properties
scp server.properties hadoop002://opt/software/kafka/config/
scp server.properties hadoop003://opt/software/kafka/config/
5)创建logs目录
mkdir logs
6)启动

企业上一般放在后台启动:
nohup ./kafka-server-start.sh ../config/server.properties &
./kafka-server-start.sh -daemon /opt/app/kafka/config/server.properties
![]()
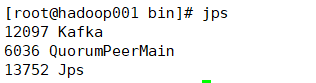
表示启动成功。
6、kafka的常用命令
1)kafka-topics.sh
概念
topic:主题
ERP系统log-->erp_topic
OA系统log-->oa_topic
为什么要用三台机器部署kafka:
因为要提高并发写/读性能。体现在partition 分区上。
创建topic,在topic里面生产消费数据

./kafka-topics.sh --create \
--zookeeper hadoop001:2181,hadoop002:2181,hadoop003:2181/kafka \
--replication-factor 3 \
--partitions 3 \
--topic test
--zookeeper hadoop001:2181,hadoop002:2181,hadoop003:2181/kafka

--replication-factor 3 1个分区3个副本
--partitions 3 3个分区,下标从0开始
进去logs目录,发现:

(1)为什么创建topic的时候zk地址要用到/kafka
因为这里/kafka指向zk的节点,便于删除zk上的kafka信息。
![]()
2)查看kafka有多少个分区
bin/kafka-topics.sh --list \
--zookeeper hadoop001:2181,hadoop002:2181,hadoop003:2181/kafka
3)发送信息和接收信息
生产者,发送消息:
bin/kafka-console-producer.sh \
--broker-list hadoop001:9092,hadoop002:9092,hadoop003:9092 \
--topic test
消费者,接收消息:
bin/kafka-console-consumer.sh \
--zookeeper hadoop001:2181,hadoop002:2181,hadoop003:2181/kafka \
--topic test \
--from-beginning
4)实验一下
在hadoop001启动生产者:

在hadoop002启动消费者:

5)单分区:有序,全局分区:无序
hadoop001:

6)如何保证生产上全局有序
案例:
MySQL BINLOG 日志文件 按顺序----有序-----》Kafka test 3个分区,但是消费的时候,读取这些分区时是无序的。
table:
ruozedata.stu
属性:
id name age
SQL:
insert into stu values(1,'jepson',18);
insert into stu values(2,'ruoze',28);
update stu set age=26 where id=1;
delete from stu where id=1;
test-0:
insert into stu values(1,'jepson',18);
test-1:
insert into stu values(2,'ruoze',28);
delete from stu where id=1;
test-2:
update stu set age=26 where id=1;
消费时
insert into stu values(2,'ruoze',28);
delete from stu where id=1;
insert into stu values(1,'jepson',18);
update stu set age=26 where id=1;消费者读取数据时读分区是无序的,可能针对同一表的操作顺序有误。
解决方案:
核心点: 共性数据发送到同一个topic的1个分区
例如生产者:
test-0:
insert into stu values(1,'jepson',18);
update stu set age=26 where id=1;
delete from stu where id=1;
test-1:
insert into stu values(2,'ruoze',28);
test-2:
消费者:
无论怎么读,同个表的操作都在同一个分区中,而同分区是有序的,就不会出现数据不同步的问题。拼装的Key: ruozedata_stu_id=1
自定义分区(代码):
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
= hash(ruozedata_stu_id=1 ) 取模 0,1,2
value: sq2)./kafka-topics.sh --describe

./kafka-topics.sh --describe \
--zookeeper hadoop001:2181,hadoop002:2181,hadoop003:2181/kafka \
--topic test
(1)解释
第一行:哪个topic 多少个分区 每个分区多少副本数
第二行开始,每一行列出了一个分区的信息,如它是第几个分区,这个分区的leader是哪个broker(之前设的broker id)(先读写到这),副本位于哪些broker(replicas),有哪些副本处于同步状态(Isr)(活跃的副本列表,有可能成为leader,比如2挂了1顶上)。

测试:kill -9 $(pgrep -f kafka)

因为我们在第二台机器kill掉了kafka,所以副本数落在第二台机器的分区的2挂了,选举1成为读写的副本
3)添加分区
--alter
Alter the number of partitions, replica assignment, and/or configuration for the topic.
改变分区数,例如,副本分配,配置主题。
将分区数改为4:
./kafka-topics.sh --alter \
--zookeeper hadoop001:2181,hadoop002:2181,hadoop003:2181/kafka \
--partitions 4 \
--topic test

成功。
4)副本的数据保存有效期
server.properties

5)删除kafka
--delete
./kafka-topics.sh --delete \
--zookeeper hadoop001:2181,hadoop002:2181,hadoop003:2181/kafka \
--topic test
(1)暴力删除
bin/kafka-topics.sh --delete \
--zookeeper yws85:2181,yws86:2181,yws87:2181/kafka \
--topic test
进入zk地址:
rmr /kafka/admin/delete_topics/test
rmr /kafka/config/topics/test
rmr /kafka/brokers/topics/test
logs物理数据:
rm -rf logs/test-*