一、重温
1、array、map、struct
2、meta
3、join
4、compression(压缩)
二、Flume
RDBMS==>Sqoop==>Hadoop
日志:分散在各个服务器上,如何==>Hadoop?
1)crontab任务将日志写到文件,然后上传到Hadoop
2)Flume
1、Flume官网

介绍:
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows.
collecting 采集 source
aggregating 聚合 channel (找个地方把采集过来的数据暂存下)
moving 移动 sink
Flume:编写配置文件,组合source、channel、sink三者之间的关系
Agent:就是由source、channel、sink组成
编写Flume的配置文件其实就是配置Agent的过程
总结:
Flume就是一个框架,针对日志数据进行采集汇总,把日志从A地方采集到B地方去
2、下载安装apache-flume-1.6.0-cdh5.7.0-bin
http://archive.cloudera.com/cdh5/cdh/5/
然后rz上传,tar解压,chown改变所属用户
3、配置
惯例将flume-env.sh.template改为flume-env.sh
将其中JAVA_HOME输入正确的地址
管理配置系统环境变量。
4、CDH文档
由于apache版本的flume坑多一些,所以看CDH的会省心一点
地址:http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0/
flume-og(旧版本)
flume-ng(新版本)
5、命令

三、Flume使用
1、配置Flume,官网:
Flume agent configuration is stored in a local configuration file. This is a text file that follows the Java properties file format. Configurations for one or more agents can be specified in the same configuration file. The configuration file includes properties of each source, sink and channel in an agent and how they are wired together to form data flows.
2、开始配置

$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template可以查命令帮助了解agent_name:配置的agent的名称
-n:--name,-n <name> the name of this agent (required),agent的名称
-c:--conf,-c <conf> use configs in <conf> directory,使用conf文件的路径
-f:--conf-file,-f <file> specify a config file (required if -z missing),编写自定义flume_agent的config文件
bin/flume-ng agent --name a1 \--conf $FLUME_HOME/conf \--conf-file /opt/script/flume/simple-flume.conf \-Dflume/opt/script/flume.root.logger=INFO,console \-Dflume.monitoring.type=http \-Dflume.monitoring.port=343433、CDH官网conf文档例子
从指定的网络端口上采集日志到控制台输出:
# example.conf: A single-node Flume configuration # Name the components on this agenta1.sources = r1
a1.sinks = k1
a1.channels = c1
a1:就是agent的名称r1:sources的名称k1:sinks的名称c1:channels的名称a1.sources.r1.type = netcat
a1.sources.r1.bind =0.0.0.0
a1.sources.r1.port = 44444-------------------------------------------------------# Describe/configure the source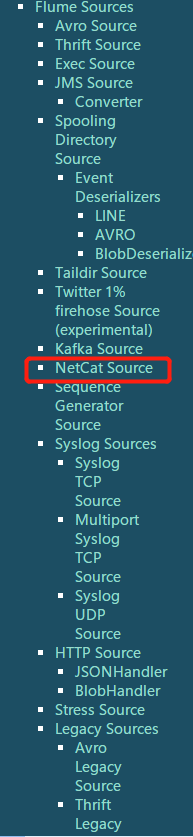

# Describe the sinka1.sinks.k1.type = logger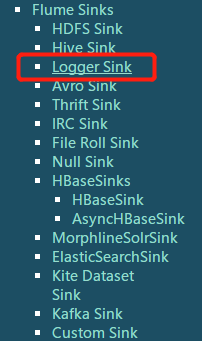

# Use a channel which buffers events in memorya1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel将上述sources,sinks中的channels指向所用的channels
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1将上述内容写入/opt/script/flume/simple-flume.conf:a1.sources = r1a1.sinks = k1 a1.channels = c1a1.sources.r1.type = netcat a1.sources.r1.bind =0.0.0.0 a1.sources.r1.port = 44444 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
执行:
bin/flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file /opt/script/flume/simple-flume.conf \-Dflume.root.logger=INFO,console \-Dflume.monitoring.type=http \-Dflume.monitoring.port=34343![]()
4、往本地IP端口打印字符
flume会采集并在控制台打印出来。


5、对当前flume作业的配置文件有重载的功能

更新conf后无需重启flume。
6、event
Event:一条数据
7、channels的监控
浏览器输入:http://192.168.137.131:34343/ 本地IP:当前flume作业的端口
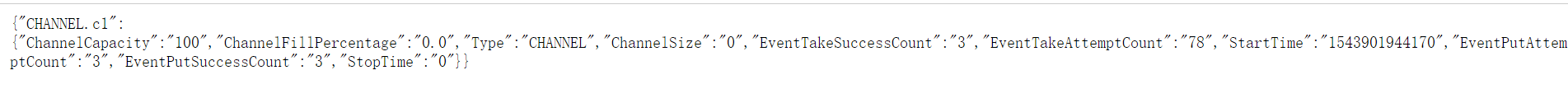 8、Event参数
8、Event参数
Event: { headers:{} body: 68 61 68 61 0D haha. }
(1)headers:
(2)body:字节数组
四、Flume支持的source、channel、sink
1、source
Avro SourceExec Source :tail -F xxx.logJMS SourceSpooling Directory Source :监控文件夹(不能有子文件夹)Taildir:NetCat:2、Sink
HDFSloggeravro:配合avro source
kafka3、channel
memoryfileAgent:各种组合source、channel、sink之间的关系把一个文件中新增的内容收集到HDFS上去exec - memory - hdfs一个文件夹spooling - memory - hdfs文件数据写入kafkaexec - memory -kafka4、如果想采集数据之后做清洗
exec - memory - hdfs ==>Spark/Hive/MR ETL(清洗)==>hdfs<==分析五、完成功能
1、需求:采集指定文件的内容到HDFS
技术选型:exec - memory -hdfs./flume-ng agent \--name a1 \--conf $FLUME_HOME/conf \--conf-file /opt/script/flume/exec-memory-hdfs.conf \-Dflume.root.logger=INFO,console \-Dflume.monitoring.type=http \-Dflume.monitoring.port=34343exec-memory-hdfs.conf:a1.sources = r1a1.sinks = k1a1.channels = c1
a1.sources.r1.type = execa1.sources.r1.command = tail -F /opt/data/data.log
a1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = hdfs://hadoop002:9000/data/flume/tail //查namenode,可以在core-site.xml里面看a1.sinks.k1.hdfs.batchSize = 10a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.writeFormat = Text
a1.channels.c1.type = memory
a1.sinks.k1.channel = c1a1.sources.r1.channels = c1成功:

查看HDFS后台
提问:为什么临时文件用tmp结尾、而最终文件前缀是flumeData答:看官网![]()
![]()
问题点:
文件太小,而分配的blocksize太大,小文件太多的话,势必会占用namenode的memory。2、需求
需求:采集指定文件夹的内容到控制台
选型:spooling - memory - logger
spooling-memory-logger.conf:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.channels = c1
a1.sources.r1.spoolDir = /opt/tmp/flume
a1.sources.r1.fileHeader = true
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
a1.channels.c1.type = memory
命令: ./flume-ng agent \
--name a1 \--conf $FLUME_HOME/conf \--conf-file /opt/script/flume/spooling-memory-logger.conf \-Dflume.root.logger=INFO,console \-Dflume.monitoring.type=http \-Dflume.monitoring.port=34343问题:
1、If a file is written to after being placed into the spooling directory, Flume will print an error to its log file and stop processing.
2、If a file name is reused at a later time, Flume will print an error to its log file and stop processing.重名会报错。
3、需求
采集指定文件以及文件夹的内容到logger
选型:taildir - memory - logger
taildir-memory-logger.conf:
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /opt/tmp/position
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /opt/tmp/flume/test1/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /opt/tmp/flume/test2/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
a1.channels.c1.type = memory
命令:
./flume-ng agent \--name a1 \--conf $FLUME_HOME/conf \--conf-file /opt/script/flume/taildir-memory-logger.conf \-Dflume.root.logger=INFO,console \-Dflume.monitoring.type=http \-Dflume.monitoring.port=34343成功:
1、输入aaa到example.log文件
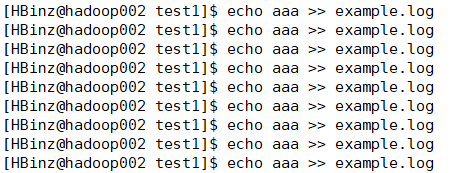

2、监控文件夹存在.log的文件
往test2拷贝.log文件夹

监控成功