目录
本文介绍Structured Streaming集成kafka的入门示例,主要介绍从kafka读出数据,打印在控制台以及写出到另一个Kafka topic。
1. 依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.3.1</version>
</dependency>2. 代码:
StructuredStreamingIntegrateKafka.scala
package com.ccclubs.Structuredstreaming.kafka
import com.alibaba.fastjson.JSON
import org.apache.spark.sql.SparkSession
/**
* @author: xianghu.wang
* @date: 2018/11/14
* @description: Structrured Streaming 集成 Kafka
*/
object StructuredStreamingIntegrateKafka {
def main(args: Array[String]): Unit = {
// Structrured Streaming 基于Spark SQL引擎,这里需要创建一个SparkSession作为入口
val ss = SparkSession
.builder
.appName("StructuredStreamingIntegrateKafka")
.master("local[*]")
.getOrCreate()
import ss.implicits._
ss.conf.set("spark.sql.streaming.checkpointLocation", "./")
// 读取kafka数据为DataFrame
val df = ss
.readStream
.format("kafka")
.option("kafka.bootstrap.servers","zc01:9092")
.option("subscribe","topicA")
.option("startingOffsets", "latest")
.load
// 将接受到的数据打印在控制台
val printOnConsole = df.selectExpr("CAST(value AS String)")
.map(x => json2Object(x.getString(0)))
.writeStream
.format("console")
.start()
// 将数据写出到kafka topicB
val write2Kafka = df.selectExpr("CAST(value AS String)")
.writeStream
.outputMode("Update")
.format("kafka")
.option("kafka.bootstrap.servers", "zc01:9092")
.option("topic", "topicB")
.start()
printOnConsole.awaitTermination()
write2Kafka.awaitTermination()
}
case class Person(name: String, age: Int, address: String)
def json2Object(json: String): Person = {
JSON.parseObject(json,classOf[Person])
}
}
新建一个KafkaProducer向topicA发送数据,数据结构:

新建一个消费者,消费topicB的数据。
启动生产者、Structured Streaming程序以及消费者。
3. 结果:
生产者(发送到topicA):
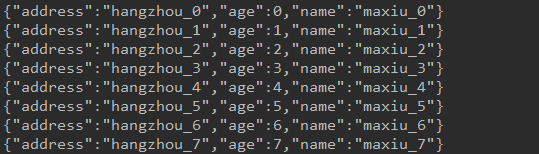
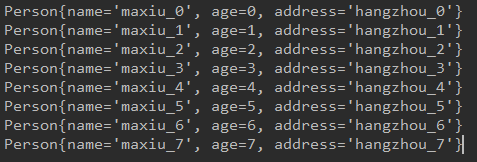
Structured Streaming:

topicB消费者:
4. 参考:
http://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html