对机器学习中常用的分类算法进行总结
目录
1.逻辑回归
(1)LR思想
逻辑回归是一个分类算法,它可以处理二元分类以及多元分类。虽然它名字里面有“回归”两个字,却不是一个回归算法。
对线性回归的结果(y=wx+b)做一个在sigmoid函数上的转换,压缩到[0,1](不仅能得出分类结果,还能得出分到此类的概率)

(2)损失函数
我们希望损失函数的值越小越好,对于二分类,当真值为1,模型的预测输出为1时,损失最好为0,它的函数为:
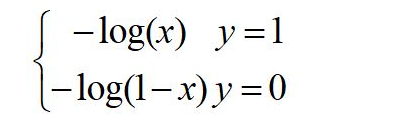

2.naive byeis
(1)NB原理
朴素贝叶斯方法是一种生成模型,对于给定的输入x,通过学习到的模型计算后验概率分布P(c | x),将后验概率最大的类作为x的类输出,已知贝叶斯定理如下
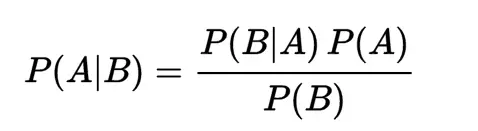
当B为样本x,A为类别c,则可以借助这个公式来推理后验概率P(c | x)

(2)NB优缺点
1)对小规模的数据表现很好,
2)适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练
3)朴素贝叶斯模型的特征条件独立假设在实际应用中往往是不成立的。(二假设:样本独立同分布、属性条件独立)
4)如果样本数据分布不能很好的代表样本空间分布,那先验概率容易测不准
3.SVM
(1)划分超平面

(2)支持向量
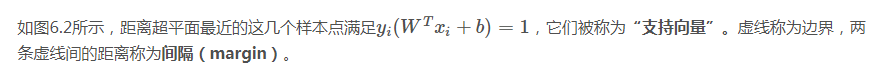


(3)拉格朗日求解

分别对w和b求偏导,并令其导数为0,故而求得

(4)非线性支持向量机和核函数
对于非线性可分的问题,将训练样本从原始空间映射到一个更高维的空间,使得样本在这个空间中线性可分


常用核函数如下表:

(5)与LR的区别(面试常考)
相同点:都是监督学习算法、分类算法、判别算法;在学术界和工业界都应用广泛
不同点:
1)loss function不同;
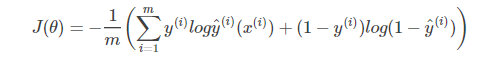
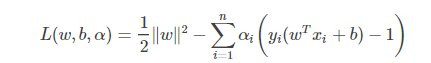
SVM损失函数自带正则||w||2,这是SVM结构风险最小化的原因。而LR需另外添加正则项。
(LR的损失函数是 cross entropy loss, adaboost的是 expotional loss ,svm是hinge loss,常见的回归模型是均方误差 loss)
2)LR考虑全局,而SVM只考虑局部的边界线附近的点;
3)在解决非线性问题时,支持向量机采用核函数的机制,而LR通常不采用核函数的方法
4)线性 SVM 依赖数据表达的距离测度,所以需要先对数据做 normalization, LR 则不受影响
4.KNN
(1)KNN原理
存在一个样本数据集合,并且样本集中每个数据都存在分类标签。输入没有标签的数据后,将新数据中的每个特征与样本集中数据对应的特征进行比较,依据投票法提取出样本集中特征最相似数据(最近邻)的分类标签。
(2)三要素
分别是k值的选取,距离度量的方式和分类决策规则。
其中,K值选择不同会导致不一样分类结果。在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
(3)KNN优缺点
1)KNN没有显示的训练过程,它是“懒惰学习”的代表,它在训练阶段只是把数据保存下来,训练时间开销为0,等收到测试样本后进行处理
2)计算量大,因为对每一个待分类的样本都要计算它到全体已知样本的距离,才目前常用的解决方法是事先对已知样本点进行剪辑,去除对分类作用不大的样本;