MySQL几种搜索引擎概述
一、引言
近几年,Elasticsearch(一下简称ES)作为开源的搜索引擎已经在国内得到越来越多的应用推广,在日志分析领域应用场景尤为广泛。传统的数据库MySQL、Oracle或者非关系型数据库MongoDB作为基础存储的企业要想实现业务数据的全文检索,该如何实现呢?
本文给出架构设计和实现原理。
二、为什么使用ES
1.大数据背景下数据量的积累与数据应用疲软矛盾一直存在。
大数据的风已经刮了几年,西安交大徐总本院士也强调“推动大数据产业必须解决好定位、规划、切入点、数据标准、开发共享等问题,互联互通是基础、定制化服务是中心、懂数据会分析是关键”。可见,数据分析的重要性。
传统企业的数据存储存在以下问题:
问题1:由于模型受限,传统企业的数据大多存储在关系型数据库mysql、Oracle,非结构化数据存储在MongoDB中。数据量也能积累到TB甚至PB级。
只能进行结构化的检索类似“ select * from table where col like '%xxx%' ”显然不能满足纷繁复杂的业务需求。
问题2:数据是死数据,数据的BI可视化展示需要专业团队开发,但不能得到很好的分析效果。
以上问题形成了数据量累计到一定量,但数据得不到很好的应用分析之间的矛盾。
2.在保持数据库不动的同时,新增全文检索,更好、更快的从亿万数据中获取检索服务。
不想抛弃原有数据存储结构,想在原有数据存储的基础上新增全文搜索。
三、传统存储模型上的ES全文检索架构
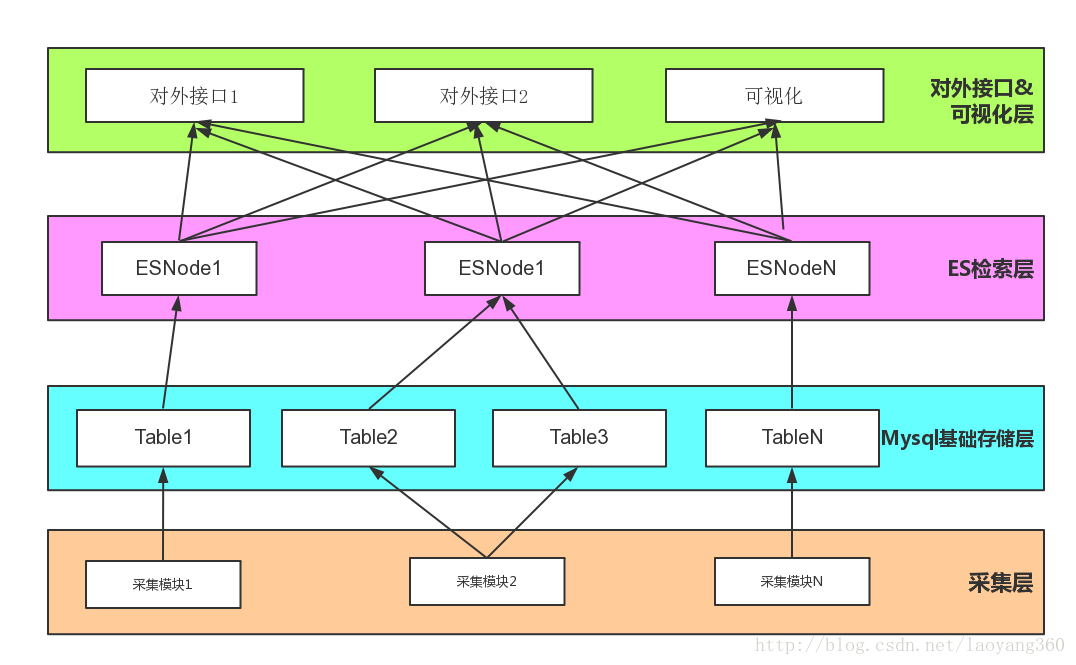
1.采集层
解决数据源头问题。
业务模型的不同,有的数据是机器设备(软件、硬件)产生的,有的则是需要自己开发爬虫(如python的scrapy)进行互联网全网爬取或者定向网站爬取。
2.MySQL基础存储层
基础数据的存储。
定义好库表结构、关联关系、主键、外键结构来存储结构化数据。
或者非结构化数据,采用Mongo键值对的方式存储。
3.ES检索层
实现基础数据的同步。这里是关键,传统的业务模型会在MySQL基础层的基础上,开展业务数据分析通常是一下步骤:
步骤1:后台数据---库表分散的建立视图,对数据进行分门别类的统计(基于Oder by,group by等操作)。
步骤2:前端可视化---通过Angularjs进行数据渲染,并通过百度的Echart模型进行可视化展示。
ES检索层的准备如下:
方式1:数据同步---基础业务数据由基础库mysql、Oracle或MongoDB同步到ES中,大多需要借助logstach实现。
同步策略参见:http://blog.csdn.net/laoyang360/article/details/72792865
mysql–>ES同步实现:http://blog.csdn.net/laoyang360/article/details/51747266

方式2:数据同步---数据存成json格式文件,然后借助阿里的fastjson解析,以bulk方式批量导入ES。
4.对外接口及可视化层
实现ES全文检索、Tag检索等对外服务、数据的分类统计、排序等可视化展示。
1、场景—:使用Elasticsearch作为主要的后端
传统项目中,搜索引擎是部署在成熟的数据存储的顶部,以提供快速且相关的搜索能力。这是因为早期的搜索引擎不能提供耐用的存储或其他经常需要的功能,如统计。 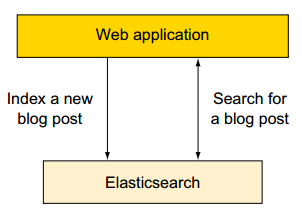
Elasticsearch是提供持久存储、统计等多项功能的现代搜索引擎。
如果你开始一个新项目,我们建议您考虑使用Elasticsearch作为唯一的数据存储,以帮助保持你的设计尽可能简单。
此种场景不支持包含频繁更新、事务(transaction)的操作。
举例如下:新建一个博客系统使用es作为存储。
1)我们可以向ES提交新的博文;
2)使用ES检索、搜索、统计数据。
ES作为存储的优势:
如果一台服务器出现故障时会发生什么?你可以通过复制 数据到不同的服务器以达到容错的目的。
注意:
整体架构设计时,需要我们权衡是否有必要增加额外的存储。
2、场景二:在现有系统中增加elasticsearch
由于ES不能提供存储的所有功能,一些场景下需要在现有系统数据存储的基础上新增ES支持。 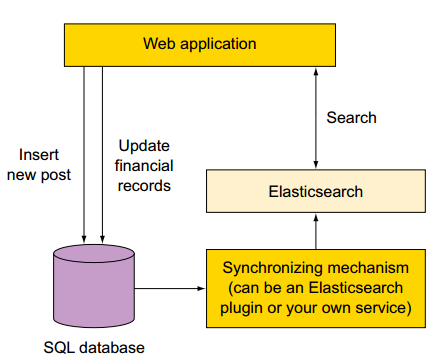
举例1:ES不支持事务、复杂的关系(至少1.X版本不支持,2.X有改善,但支持的仍然不好),如果你的系统中需要上述特征的支持,需要考虑在原有架构、原有存储的基础上的新增ES的支持。
举例2:如果你已经有一个在运行的复杂的系统,你的需求之一是在现有系统中添加检索服务。一种非常冒险的方式是重构系统以支持ES。而相对安全的方式是:将ES作为新的组件添加到现有系统中。
如果你使用了如下图所示的SQL数据库和ES存储,你需要找到一种方式使得两存储之间实时同步。需要根据数据的组成、数据库选择对应的同步插件。可供选择的插件包括:
1)MySQL、oracle选择 logstash-input-jdbc 插件。
2)mongo选择 mongo-connector工具。
假设你的在线零售商店的产品信息存储在SQL数据库中。 为了快速且相关的搜索,你安装Elasticsearch。
为了索引数据,您需要部署一个同步机制,该同步机制可以是Elasticsearch插件或你建立一个自定义的服务。此同步机制可以将对应于每个产品的所有数据和索引都存储在Elasticsearch,每个产品作为一个document存储(这里的document相当于关系型数据库中的一行/row数据)。
当在该网页上的搜索条件中输入“用户的类型”,店面网络应用程序通过Elasticsearch查询该信息。 Elasticsearch返回符合标准的产品documents,并根据你喜欢的方式来分类文档。 排序可以根据每个产品的被搜索次数所得到的相关分数,或任何存储在产品document信息,例如:最新最近加入的产品、平均得分,或者是那些插入或更新信息。 所以你可以只使用Elasticsearch处理搜索。这取决于同步机制来保持Elasticsearch获取最新变化。
3、场景三:使用elasticsearch和现有的工具
在一些使用情况下,您不必写一行代码就能通过elasticssearch完成一项工作。很多工具都可以与Elasticsearch一起工作,所以你不必到你从头开始编写。
例如,假设要部署一个大规模的日志框架存储,搜索,并分析了大量的事件。
如图下图,处理日志和输出到Elasticsearch,您可以使用日志记录工具,如rsyslog(www.rsyslog.com),Logstash(www.elastic.co/products/logstash),或Apache Flume(http://flume.apache.org)。
搜索和可视化界面分析这些日志,你可以使用Kibana(www.elastic.co/产品/ kibana)。

为什么那么多工具适配Elasticsearch?主要原因如下:
1)Elasticsearch是开源的。
2)Elasticsearch提供了JAVA API接口。
3)Elasticsearch提供了RESTful API接口(不管程序用什么语言开发,任何程序都可以访问)
4)更重要的是,REST请求和应答是典型的JSON(JavaScript对象 符号)格式。通常情况下,一个REST请求包含一个JSON文件,其回复都 也是一个JSON文件。