一、先找找教程
先看了一下知乎推荐,然后就是下面这些了:
浅析正则表达式—(原理篇)
正则表达式30分钟入门教程
正则表达式真的很6,可惜你不会写(这个文档看的这篇)
在线工具:
http://snowcoal.com/tools/regex/reg
https://regexr.com/ (推荐)
二、准备,开始记笔记了
1、元字符
元字符是构造正则表达式的一种基本元素,
| 元字符 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串结束 |
| \W、 \D、 \S | not word、not digit、not whitespace |
| [abc] | any of a, b, or c |
| [^abc] | not a, b, or c |
| [a-g] | character between a & g |
2、重复限定符
| 语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
3、分组
正则表达式中用小括号 () 来做分组,也就是括号中的内容作为一个整体。
如:匹配字符串中包含 0 到多个 ab 开头:
^(ab)*
4、转义
如果要匹配的字符串中本身就包含小括号,比如匹配(ab),那么就要转义了,在要转义的字符前面加个斜杠,也就是\即可。
^(\(ab\))*
5、条件或
正则用符号|来表示或,也叫做分支条件,当满足正则里的分支条件的任何一种条件时,都会当成是匹配成功。
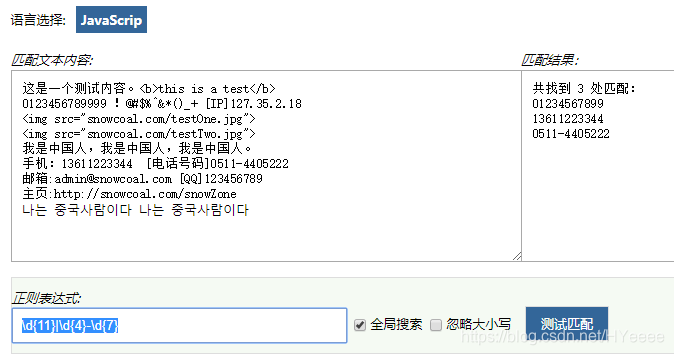
比如找出下面文字中的电话:
//匹配11位号码或者4-7格式的电话
\d{11}|\d{4}-\d{7}
6、区间
正则提供一个元字符中括号[]来表示区间条件。
^(13[0-2])
//会匹配 130、131、132 开头的
7、零宽断言
正则中的断言:就是说正则可以指明在指定的内容的前面或后面会出现满足指定规则的内容。
零宽:就是没有宽度,在正则中,断言只是匹配位置,不占字符,也就是说,匹配结果里是不会返回断言本身。
注意:零宽断言匹配的条件一定是针对毗邻的字符,比如123aabbcc,可以查到bb前面的aa,但不能查到bb前面的123。
| 名称 | 语法 | 作用 |
|---|---|---|
| 正向先行断言(正前瞻) | (?=pattern) | 匹配 pattern 表达式的前面内容,不返回本身。 |
| 正向后行断言(正后顾) | (?<=pattern) | 匹配 pattern 表达式的后面的内容,不返回本身 |
| 负向先行断言(负前瞻) | (?!pattern) | 匹配非 pattern 表达式的前面内容,不返回本身。 |
| 负向后行断言(负后顾) | (?<!pattern) | 匹配非 pattern 表达式的后面内容,不返回本身。 |
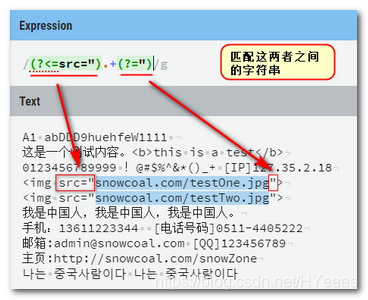
例一:返回img src中的路径:(?<=src=").+(?=") 同时使用正前瞻和正后顾。
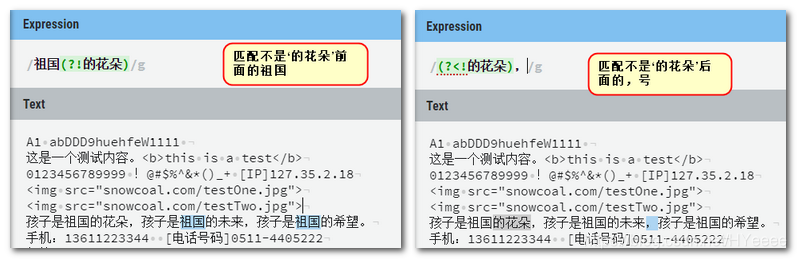
例二:负前瞻和负后顾
8、捕获和非捕获
捕获的意思是匹配表达式,但捕获通常和分组联系在一起,也就是“捕获组”。
捕获组:匹配子表达式的内容,把匹配结果保存到内存中中数字编号或显示命名的组里,以深度优先进行编号,之后可以通过序号或名称来使用这些匹配结果。
捕获组就是匹配子表达式的内容按序号或者命名保存起来以便使用
而根据命名方式的不同,又可以分为两种组:
数字编号捕获组:
比如固定电话的:020-85653333
他的正则表达式为:(0\d{2})-(\d{8})
按照左括号的顺序,这个表达式有如下分组:在分组中,第 0 组为整个表达式,第一组开始为分组。
| 编号 | 分组 | 内容 |
|---|---|---|
| 0 | (0\d{2})-(\d{8}) | 020-85653333 |
| 1 | (0\d{2}) | 020 |
| 2 | (\d{8}) | 85653333 |
命名编号捕获组
语法:(?<name>exp)
解释:给上面的一组二组命名,分组的命名由表达式中的 name 指定
比如区号也可以这样写:(?<quhao>\0\d{2})-(?<haoma>\d{8}),
按照左括号的顺序,这个表达式有如下分组:
| 序号 | 名称 | 分组 | 内容 |
|---|---|---|---|
| 0 | 0 | (0\d{2})-(\d{8}) | 020-85653333 |
| 1 | quhao | (0\d{2}) | 020 |
| 2 | haoma | (\d{8}) | 85653333 |
这个命名捕获在工具中测试出错,https://regexr.com/ 不支持这种用法
非捕获组
语法:(?:exp)
解释:和捕获组刚好相反,它用来标识那些不需要捕获的分组,你可以决定哪些分组不要。
比如上面的,如果不需要第一个分组,那就这样写:(?:\0\d{2})-(\d{8})
| 序号 | 编号 | 分组 | 内容 |
|---|---|---|---|
| 0 | 0 | (0\d{2})-(\d{8}) | 020-85653333 |
| 1 | 1 | (\d{8}) | 85653333 |
9、反向引用
捕获也可以在正则表达式内部进行引用,根据捕获组的命名规则,反向引用可分为:
数字编号组反向引用:\number
命名编号组反向引用:‘name’
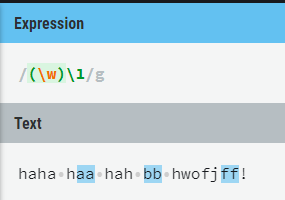
比如下面这个例子:
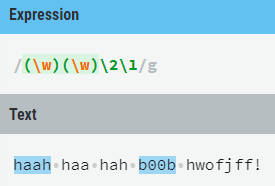
(\w)是一个分组,匹配一个字符,后面\1表示这个位置的值 = 分组1。
那么下图匹配得到的就是相同的两个字符。
同样的,查找连续相同的4个字符 / (\w)\1\1\1 /g;
下面是匹配的四字回文:
10、贪婪和非贪婪
贪婪匹配: 它会尽可能匹配最多的。比如\d{3,6},当有超过6个数字时,会匹配到第6个。
当多个贪婪在一起时,
如果字符串能满足他们各自最大程度的匹配时,就互不干扰.
但如果不能满足时,会根据深度优先原则,也就是从左到右的每一个贪婪量词,优先最大数量的满足,剩余再分配下一个量词匹配。
/(\d{1,2})(\d{3,4})/g
“617628” 是前面的\d{1,2}匹配出了 61 ,后面的匹配出了 7628
"2991" 是前面的\d{1,2}匹配出了 29 ,后面的匹配出了 91
"87321" 是前面的\d{1,2}匹配出了 87 ,后面的匹配出了 321
非贪婪 : 它会尽可能匹配最少的。比如\d{3,6}?,当有超过6个数字时,会匹配到第3个停止。
/(\d{1,2}?)(\d{3,4})/g
“61762” 是左边的懒惰匹配出 6,右边的贪婪匹配出 1762
"2991" 是左边的懒惰匹配出 2,右边的贪婪匹配出 991
"87321" 是左边的懒惰匹配出 8,右边的贪婪匹配出 7321
懒惰量词是在贪婪量词后面加个“?”
| 代码 | 说明 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
11、反义
前面说到元字符的都是要匹配什么什么,当然如果你想反着来,不想匹配某些字符,正则也提供了一些常用的反义元字符:
| 元字符 | 解释 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |