事实表粒度
维度建模中一个非常重要的步骤是定义事实表的粒度。定义了事实表的粒度,则事实表能表达数据的详细程度就确定了。定义粒度的例子如下:
1.客户的零售单据上的每个条目。
2.保险单上的每个交易。
定义好事实表的粒度有很大的用处。
第一个用处就是用来确定维度是否与该事实表相关。例如,对于粒度细到医疗单据上条目项的事实表来说,医疗结果是不会作为维度和它进行关联的,因为它们不在同一个粒度上。但是,对于一般的E/R数据模型来说,医疗单据是和医疗结果是进行关联的。通常的规范化建模里没有粒度的概念,它们表示的是实体之间的关系,这也是规范化建模和维度建模中一个较大的不同之处。
定义成原子的事实表粒度后,可以选择较多的维度来对该事实表进行描述。也就是说,事实表的粒度越细,能记载的信息就会越多。原子粒度的事实表对维度建模来说是至关重要的。
前面列举的几个例子中的粒度定义都是最低粒度的,这些事实表的数据是原子的,不能再进行细分了。但是我们可以在这个基础上定义高粒度的聚集事实表。举例如下:
1.一天一个仓库一个产品的销售总量。
2.每月的保险交易总数。
3.每月诊断治疗的交费金额。
这些高粒度的聚集事实表总是具有较少的维度。通常在建立这些聚集事实表的时候,我们会去掉一些维度或者缩减某些维度的范围。也正因为如此,聚集事实表应该和其对应的原子事实表一起使用。当需要更详细信息时,可以访问其对应的原子事实表。
第二个用处是定义好事实表的粒度后,能更清楚的确定哪个事实与该事实表相关。简单的说,事实必须对于该粒度是正确的,不同粒度的事实是不能定义在该事实表中的。
总结来说,我们定义事实表的粒度及维度建模时可以采用如下的步骤:
1.熟悉源数据的情况。
2.定义事实表的粒度,最好定义到原子粒度。
3.将与这个粒度的相关信息都添加为维度。
4.添加与该粒度相关的度量信息为事实。
事实表关联非最低粒度的维度的情况
如果将事实表与维度表进行关联,建模,通过如下例子说明,
事实表fact_table,将会用level2code来关联维度表:

维度表dim_table,level3code是最低粒度,level2code及level1code是父级维度:

构建cube,会生成如下模型:
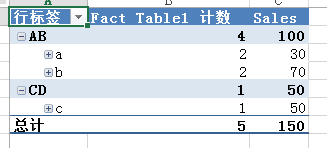
其实,事实表与维表进行关联(即join)操作生成模型,选择一致性维度进行关联,关联之后可以再进行上卷等操作,进而在更高粒度上进行聚合展示。
select * from
(
select
level2code,
sum(sales) as sales
from
fact_table
group by
level2code
) a
join
dim_table b
on a.`level2code` = b.`level2code`

进而再第一次join的基础上,可以进行聚合,可以获取更高粒度上的数据