下面链接是非常好的文章(比我的好,哈哈)
- https://blog.csdn.net/u013733326/article/details/79827273
- https://blog.csdn.net/u013733326/article/details/79847918
图片来自作业。下面是对作业的总结。
1. 初始化为零
为什么神经网络参数不能全部初始化为全0?
我仅能理解的是,无法打破对称性。
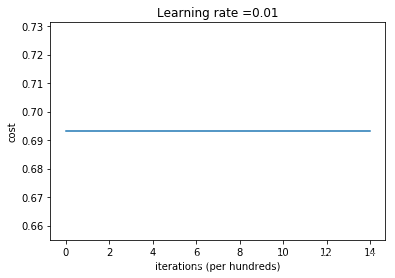
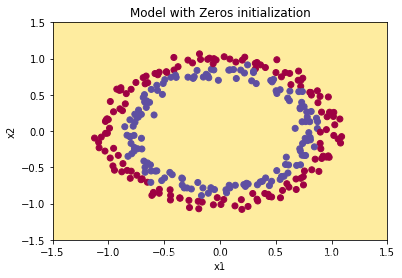
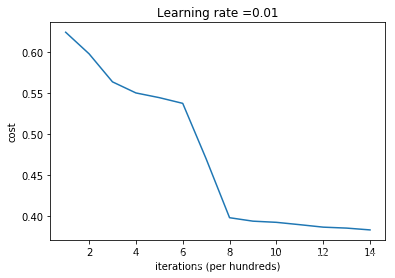
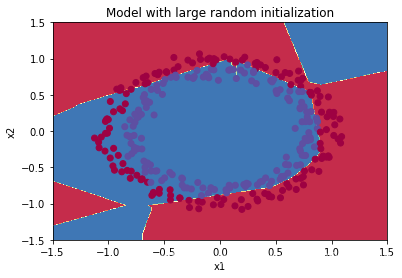
2. 随机初始化参数
为了打破对称性,我们可以随机地把参数赋值。
parameters[‘W’ + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) * 10
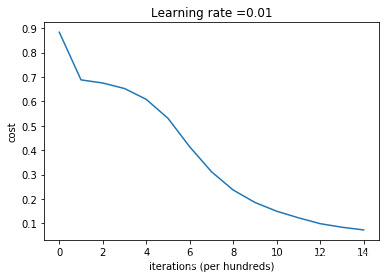
但是这次,初始参数较大。
会有较大的误差,且减慢优化速度。
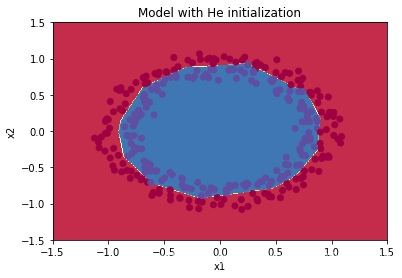
3. He initialization
这次初始参数不是乘以10。
而是乘以:
结果能很好的分类。
4. 参数初始化总结
不同的初始化方法可能导致性能最终不同
随机初始化有助于打破对称,使得不同隐藏层的单元可以学习到不同的参数。
初始化时,初始值不宜过大。
He初始化搭配ReLU激活函数常常可以得到不错的效果。
在深度学习中,如果数据集没有足够大的话,可能会导致一些过拟合的问题。过拟合导致的结果就是在训练集上有着很高的精确度,但是在遇到新的样本时,精确度下降会很严重。为了避免过拟合的问题,接下来我们要讲解的方式就是正则化。———— https://blog.csdn.net/u013733326/article/details/79847918